TimeSeriesSplit#
- класс sklearn.model_selection.TimeSeriesSplit(n_splits=5, *, max_train_size=None, test_size=None, разрыв=0)[источник]#
Валидатор перекрестной проверки временных рядов.
Предоставляет индексы обучающей/тестовой выборки для разделения временных данных, где другие методы перекрестной проверки неприменимы, так как они привели бы к обучению на будущих данных и оценке на прошлых данных. Для обеспечения сопоставимых метрик по фолдам выборки должны быть равномерно распределены. После выполнения этого условия каждый тестовый набор охватывает одинаковую временную продолжительность, в то время как размер обучающего набора накапливает данные из предыдущих разделений.
Этот объект перекрестной проверки является вариацией
KFold. В k-м разделении он возвращает первые k блоков как обучающий набор и (k+1)-й блок как тестовый набор.Обратите внимание, что в отличие от стандартных методов перекрестной проверки, последовательные обучающие наборы являются надмножествами предыдущих.
Подробнее в Руководство пользователя.
Для визуализации поведения перекрёстной проверки и сравнения общих методов разделения scikit-learn обратитесь к Визуализация поведения кросс-валидации в scikit-learn
Добавлено в версии 0.18.
- Параметры:
- n_splitsint, по умолчанию=5
Количество разбиений. Должно быть не менее 2.
Изменено в версии 0.22:
n_splitsзначение по умолчанию изменено с 3 на 5.- max_train_sizeint, default=None
Максимальный размер для одного обучающего набора.
- test_sizeint, default=None
Используется для ограничения размера тестового набора. По умолчанию
n_samples // (n_splits + 1), что является максимально допустимым значением сgap=0.Добавлено в версии 0.24.
- разрывint, по умолчанию=0
Количество образцов, исключаемых из конца каждого обучающего набора перед тестовым набором.
Добавлено в версии 0.24.
Примечания
Обучающая выборка имеет размер
i * n_samples // (n_splits + 1) + n_samples % (n_splits + 1)вith разделение, с тестовым набором размераn_samples//(n_splits + 1)по умолчанию, гдеn_samples— количество образцов. Обратите внимание, что эта формула действительна только тогда, когдаtest_sizeиmax_train_sizeоставлены по умолчанию.Примеры
>>> import numpy as np >>> from sklearn.model_selection import TimeSeriesSplit >>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) >>> y = np.array([1, 2, 3, 4, 5, 6]) >>> tscv = TimeSeriesSplit() >>> print(tscv) TimeSeriesSplit(gap=0, max_train_size=None, n_splits=5, test_size=None) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0] Test: index=[1] Fold 1: Train: index=[0 1] Test: index=[2] Fold 2: Train: index=[0 1 2] Test: index=[3] Fold 3: Train: index=[0 1 2 3] Test: index=[4] Fold 4: Train: index=[0 1 2 3 4] Test: index=[5] >>> # Fix test_size to 2 with 12 samples >>> X = np.random.randn(12, 2) >>> y = np.random.randint(0, 2, 12) >>> tscv = TimeSeriesSplit(n_splits=3, test_size=2) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0 1 2 3 4 5] Test: index=[6 7] Fold 1: Train: index=[0 1 2 3 4 5 6 7] Test: index=[8 9] Fold 2: Train: index=[0 1 2 3 4 5 6 7 8 9] Test: index=[10 11] >>> # Add in a 2 period gap >>> tscv = TimeSeriesSplit(n_splits=3, test_size=2, gap=2) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0 1 2 3] Test: index=[6 7] Fold 1: Train: index=[0 1 2 3 4 5] Test: index=[8 9] Fold 2: Train: index=[0 1 2 3 4 5 6 7] Test: index=[10 11]
Для более подробного примера см. Инженерия временных признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_n_splits(X=None, y=None, группы=None)[источник]#
Возвращает количество итераций разделения, установленное с помощью
n_splitsparam при создании кросс-валидатора.- Параметры:
- Xмассивоподобный объект формы (n_samples, n_features), по умолчанию=None
Всегда игнорируется, существует для совместимости API.
- yarray-like формы (n_samples,), по умолчанию=None
Всегда игнорируется, существует для совместимости API.
- группыarray-like формы (n_samples,), по умолчанию=None
Всегда игнорируется, существует для совместимости API.
- Возвращает:
- n_splitsint
Возвращает количество итераций разделения в кросс-валидаторе.
- split(X, y=None, группы=None)[источник]#
Сгенерировать индексы для разделения данных на обучающую и тестовую выборки.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,), по умолчанию=None
Всегда игнорируется, существует для совместимости API.
- группыarray-like формы (n_samples,), по умолчанию=None
Всегда игнорируется, существует для совместимости API.
- Возвращает:
- обучатьndarray
Индексы обучающей выборки для этого разбиения.
- тестndarray
Индексы тестового набора для этого разбиения.
Примеры галереи#

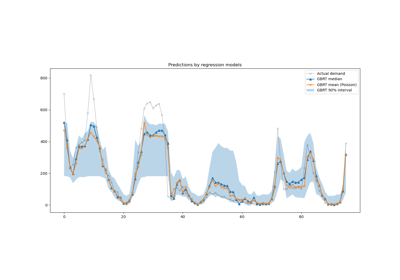
Лаггированные признаки для прогнозирования временных рядов
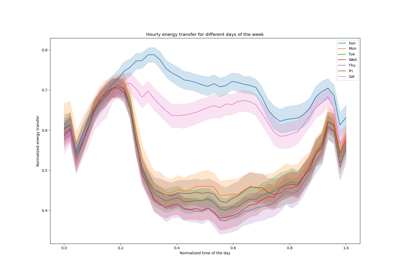
Признаки в деревьях с градиентным бустингом на гистограммах
Визуализация поведения кросс-валидации в scikit-learn