load_iris#
- sklearn.datasets.load_iris(*, return_X_y=False, as_frame=False)[источник]#
Загружает и возвращает набор данных ирисов (классификация).
Набор данных iris — это классический и очень простой набор данных для многоклассовой классификации.
Классы
3
Примеров на класс
50
Всего образцов
150
Снижение размерности
4
Признаки
действительное, положительное
Подробнее в Руководство пользователя.
Изменено в версии 0.20: Исправлены две ошибочные точки данных в соответствии с работой Фишера. Новая версия совпадает с версией в R, но не с версией в репозитории UCI Machine Learning Repository.
- Параметры:
- return_X_ybool, по умолчанию=False
Если True, возвращает
(data, target)вместо объекта Bunch. См. ниже для получения дополнительной информации оdataиtargetобъект.Добавлено в версии 0.18.
- as_framebool, по умолчанию=False
Если True, данные представляют собой pandas DataFrame, включающий столбцы с соответствующими типами данных (числовые). Цель — pandas DataFrame или Series в зависимости от количества целевых столбцов. Если
return_X_yравно True, тогда (data,target) будут pandas DataFrame или Series, как описано ниже.Добавлено в версии 0.23.
- Возвращает:
- данные
Bunch Объект, подобный словарю, со следующими атрибутами.
- данные{ndarray, dataframe} формы (150, 4)
Матрица данных. Если
as_frame=True,dataбудет pandas DataFrame.- target: {ndarray, Series} формы (150,)
Целевая переменная классификации. Если
as_frame=True,targetбудет pandas Series.- feature_names: list
Имена столбцов набора данных.
- target_names: ndarray формы (3, )
Имена целевых классов.
- фрейм: DataFrame формы (150, 5)
Только присутствует, когда
as_frame=TrueМы определяем функцию для загрузки данных изdataиtarget.Добавлено в версии 0.23.
- DESCR: str
Полное описание набора данных.
- filename: str
Путь к местоположению данных.
Добавлено в версии 0.20.
- (data, target)кортеж если
return_X_yравно True Кортеж из двух ndarray. Первый содержит 2D-массив формы (n_samples, n_features), где каждая строка представляет один образец, а каждый столбец представляет признаки. Второй ndarray формы (n_samples,) содержит целевые образцы.
Добавлено в версии 0.18.
- данные
Примеры
Допустим, вас интересуют выборки 10, 25 и 50, и вы хотите узнать их названия классов.
>>> from sklearn.datasets import load_iris >>> data = load_iris() >>> samples = [10, 25, 50] >>> data.target[samples] array([0, 0, 1]) >>> data.target_names[data.target[samples]] array(['setosa', 'setosa', 'versicolor'], dtype='
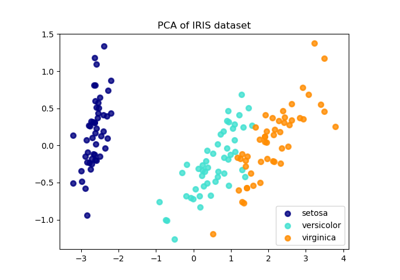
См. Анализ главных компонент (PCA) на наборе данных Iris для более подробного примера работы с набором данных iris.
Примеры галереи#
Построить дендрограмму иерархической кластеризации

Объединение нескольких методов извлечения признаков
Анализ главных компонент (PCA) на наборе данных Iris
Сравнение LDA и PCA 2D проекции набора данных Iris
Факторный анализ (с вращением) для визуализации паттернов

Построить поверхности решений ансамблей деревьев на наборе данных ирисов
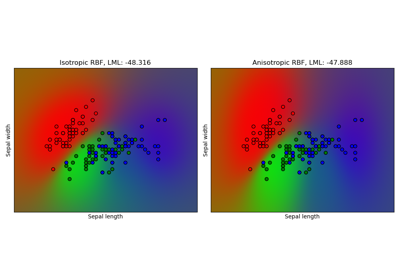
Гауссовский процесс классификации (GPC) на наборе данных iris
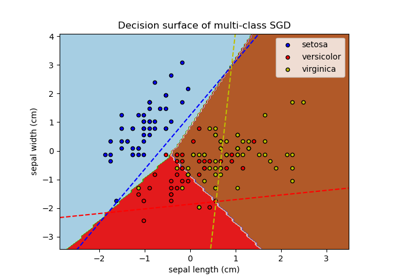
Построение многоклассового SGD на наборе данных iris
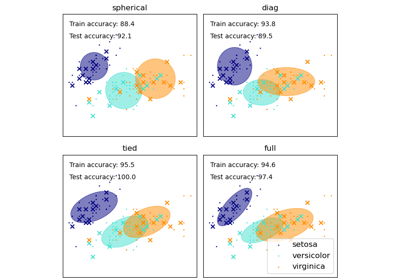
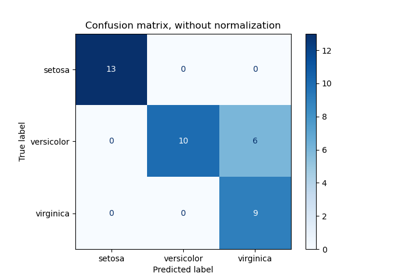
Оценить производительность классификатора с помощью матрицы ошибок


Тест с перестановками для значимости оценки классификации
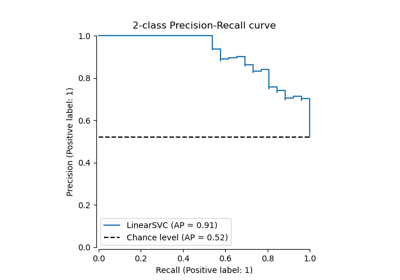
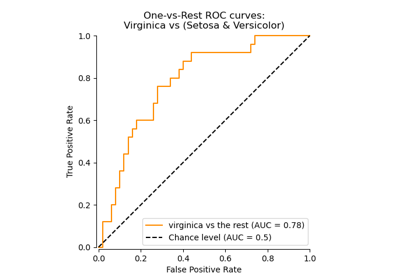
Многоклассовая рабочая характеристика приемника (ROC)
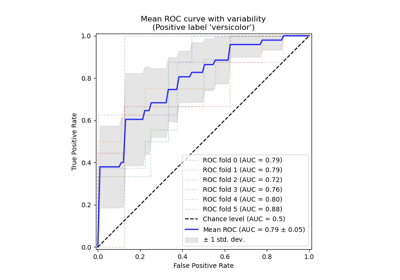
Рабочая характеристика приёмника (ROC) с перекрёстной проверкой
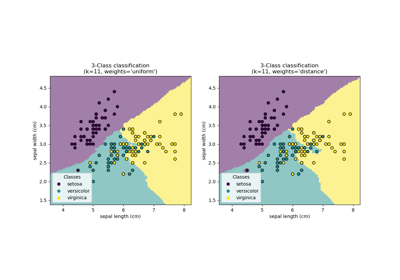
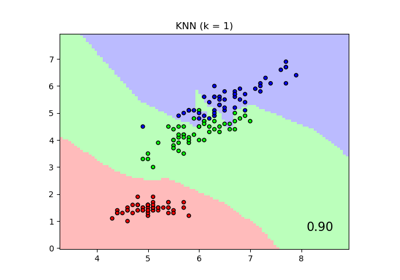
Сравнение ближайших соседей с анализом компонент соседства и без него
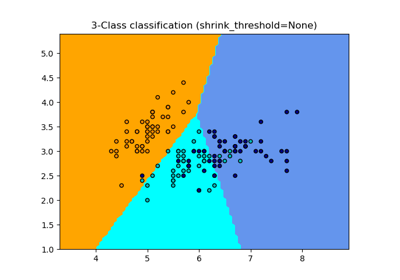
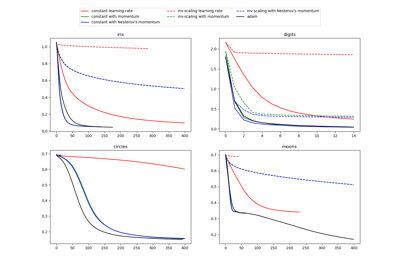
Сравнение стохастических стратегий обучения для MLPClassifier

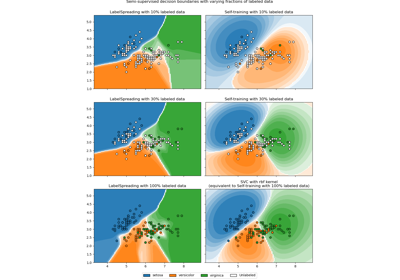
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris
Построение различных классификаторов SVM на наборе данных iris
Построить поверхность решений деревьев решений, обученных на наборе данных ирисов