NeighborhoodComponentsAnalysis#
- класс sklearn.neighbors.NeighborhoodComponentsAnalysis(n_components=None, *, init='auto', warm_start=False, max_iter=50, tol=1e-05, callback=None, verbose=0, random_state=None)[источник]#
Анализ компонент соседства.
Анализ компонентов соседства (NCA) — это алгоритм машинного обучения для обучения метрикам. Он обучает линейное преобразование с учителем, чтобы повысить точность классификации стохастического правила ближайших соседей в преобразованном пространстве.
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, default=None
Предпочтительная размерность проецируемого пространства. Если None, будет установлено в
n_features.- init{'auto', 'pca', 'lda', 'identity', 'random'} или ndarray формы (n_features_a, n_features_b), default='auto'
Инициализация линейного преобразования. Возможные варианты:
'auto','pca','lda','identity','random', и массив numpy формы(n_features_a, n_features_b).'auto'В зависимости от
n_components, выбирается наиболее разумная инициализация. Еслиn_components <= min(n_features, n_classes - 1)мы используем'lda', так как использует информацию меток. Если нет, ноn_components < min(n_features, n_samples), мы используем'pca', так как он проецирует данные в значимые направления (те, что с большей дисперсией). В противном случае мы просто используем'identity'.
'lda'min(n_components, n_classes)наиболее дискриминативных компонентов входных данных, переданных вfitбудет использоваться для инициализации преобразования. (Еслиn_components > n_classes, остальные компоненты будут нулевыми.) (См.LinearDiscriminantAnalysis)
'identity'Если
n_componentsстрого меньше, чем размерность входных данных, переданных вfit, единичная матрица будет усечена до первыхn_componentsстрок.
'random'Начальное преобразование будет случайным массивом формы
(n_components, n_features). Каждое значение выбирается из стандартного нормального распределения.
- numpy array
n_features_bдолжен соответствовать размерности входных данных, передаваемых вfitи n_features_a должно быть меньше или равно этому. Еслиn_componentsне являетсяNone,n_features_aдолжны соответствовать ему.
- warm_startbool, по умолчанию=False
Если
Trueиfitбыл вызван ранее, решение предыдущего вызоваfitиспользуется в качестве начального линейного преобразования (n_componentsиinitбудут проигнорированы).- max_iterint, по умолчанию=50
Максимальное количество итераций в оптимизации.
- tolfloat, по умолчанию=1e-5
Допуск сходимости для оптимизации.
- callbackвызываемый объект, по умолчанию=None
Если не
None, эта функция вызывается после каждой итерации оптимизатора, принимая в качестве аргументов текущее решение (преобразованная матрица в развернутом виде) и количество итераций. Это может быть полезно, если нужно исследовать или сохранять преобразование, найденное после каждой итерации.- verboseint, по умолчанию=0
Если 0, сообщения о прогрессе не выводятся. Если 1, сообщения о прогрессе выводятся в stdout. Если > 1, сообщения о прогрессе выводятся и
dispпараметрscipy.optimize.minimizeбудет установлено вverbose - 2.- random_stateint или numpy.RandomState, по умолчанию=None
Псевдослучайный генератор чисел или его семя, если int. Если
init='random',random_stateиспользуется для инициализации случайного преобразования. Еслиinit='pca',random_stateпередается как аргумент в PCA при инициализации преобразования. Передайте целое число для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Линейное преобразование, изученное в процессе обучения.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- n_iter_int
Подсчитывает количество итераций, выполненных оптимизатором.
- random_state_numpy.RandomState
Объект генератора псевдослучайных чисел, используемый во время инициализации.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
sklearn.discriminant_analysis.LinearDiscriminantAnalysisЛинейный дискриминантный анализ.
sklearn.decomposition.PCAМетод главных компонент (PCA).
Ссылки
[1]J. Goldberger, G. Hinton, S. Roweis, R. Salakhutdinov. "Neighbourhood Components Analysis". Advances in Neural Information Processing Systems. 17, 513-520, 2005. https://www.cs.toronto.edu/~rsalakhu/papers/ncanips.pdf
[2]Запись в Википедии о Neighborhood Components Analysis https://en.wikipedia.org/wiki/Neighbourhood_components_analysis
Примеры
>>> from sklearn.neighbors import NeighborhoodComponentsAnalysis >>> from sklearn.neighbors import KNeighborsClassifier >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import train_test_split >>> X, y = load_iris(return_X_y=True) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... stratify=y, test_size=0.7, random_state=42) >>> nca = NeighborhoodComponentsAnalysis(random_state=42) >>> nca.fit(X_train, y_train) NeighborhoodComponentsAnalysis(...) >>> knn = KNeighborsClassifier(n_neighbors=3) >>> knn.fit(X_train, y_train) KNeighborsClassifier(...) >>> print(knn.score(X_test, y_test)) 0.933333... >>> knn.fit(nca.transform(X_train), y_train) KNeighborsClassifier(...) >>> print(knn.score(nca.transform(X_test), y_test)) 0.961904...
- fit(X, y)[источник]#
Обучает модель на основе предоставленных обучающих данных.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие выборки.
- yarray-like формы (n_samples,)
Соответствующие метки обучения.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Применить изученное преобразование к данным.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы данных.
- Возвращает:
- X_embedded: ndarray формы (n_samples, n_components)
Преобразованные образцы данных.
- Вызывает:
- NotFittedError
Если
fitне вызывался ранее.
Примеры галереи#

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…
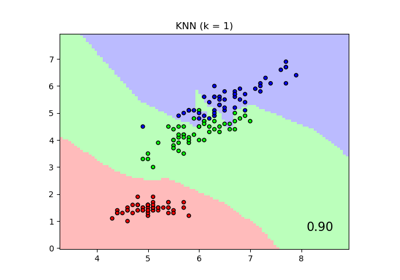
Сравнение ближайших соседей с анализом компонент соседства и без него
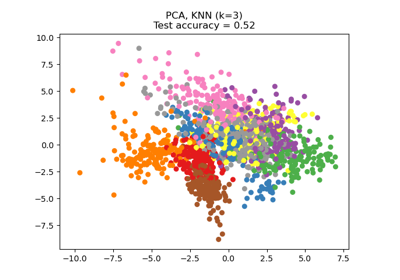
Снижение размерности с помощью анализа компонентов соседства