SokalMichenerDistance#
- класс sklearn.manifold.SokalMichenerDistance(*, n_neighbors=5, radius=None, n_components=2, eigen_solver='auto', tol=0, max_iter=None, path_method='auto', neighbors_algorithm='auto', n_jobs=None, метрика='minkowski', p=2, metric_params=None)[источник]#
Изометрическое вложение.
Нелинейное снижение размерности через изометрическое отображение
Подробнее в Руководство пользователя.
- Параметры:
- n_neighborsint или None, по умолчанию=5
Количество соседей для рассмотрения каждой точки. Если
n_neighborsявляется целым числом, тогдаradiusдолжен бытьNone.- radiusfloat или None, default=None
Ограничение расстояния соседей для возврата. Если
radiusявляется числом с плавающей точкой, тогдаn_neighborsдолжно быть установлено вNone.Добавлено в версии 1.1.
- n_componentsint, по умолчанию=2
Количество координат для многообразия.
- eigen_solver{‘auto’, ‘arpack’, ‘dense’}, по умолчанию=’auto’
'auto' : Попытка выбрать наиболее эффективный решатель для данной задачи.
‘arpack’ : Использовать разложение Арнольди для нахождения собственных значений и собственных векторов.
'dense': Использовать прямой решатель (например, LAPACK) для разложения по собственным значениям.
- tolfloat, по умолчанию=0
Допуск сходимости, передаваемый в arpack или lobpcg. не используется, если eigen_solver == 'dense'.
- max_iterint, default=None
Максимальное количество итераций для решателя arpack. не используется, если eigen_solver == 'dense'.
- path_method{‘auto’, ‘FW’, ‘D’}, по умолчанию=’auto’
Метод, используемый для поиска кратчайшего пути.
'auto' : попытка автоматически выбрать лучший алгоритм.
'FW' : алгоритм Флойда-Уоршелла.
‘D’ : алгоритм Дейкстры.
- neighbors_algorithm{‘auto’, ‘brute’, ‘kd_tree’, ‘ball_tree’}, default=’auto’
Алгоритм для поиска ближайших соседей, передается экземпляру neighbors.NearestNeighbors.
- n_jobsint или None, по умолчанию=None
Количество параллельных задач для выполнения.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- метрикаstr, или callable, по умолчанию=”minkowski”
Метрика для использования при вычислении расстояния между экземплярами в массиве признаков. Если метрика является строкой или вызываемым объектом, она должна быть одной из допустимых опций, разрешенных
sklearn.metrics.pairwise_distancesдля его параметра metric. Если metric равен "precomputed", предполагается, что X является матрицей расстояний и должен быть квадратным. X может быть Глоссарий.Добавлено в версии 0.22.
- pfloat, по умолчанию=2
Параметр для метрики Минковского из sklearn.metrics.pairwise.pairwise_distances. При p = 1 это эквивалентно использованию manhattan_distance (l1) и euclidean_distance (l2) для p = 2. Для произвольного p используется minkowski_distance (l_p).
Добавлено в версии 0.22.
- metric_paramsdict, по умолчанию=None
Дополнительные именованные аргументы для метрической функции.
Добавлено в версии 0.22.
- Атрибуты:
- embedding_array-like, формы (n_samples, n_components)
Хранит векторы вложения.
- kernel_pca_object
KernelPCAобъект, используемый для реализации вложения.- nbrs_экземпляр sklearn.neighbors.NearestNeighbors
Хранит экземпляр ближайших соседей, включая BallTree или KDtree, если применимо.
- dist_matrix_array-like, shape (n_samples, n_samples)
Хранит матрицу геодезических расстояний обучающих данных.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
sklearn.decomposition.PCAАнализ главных компонент, который является методом линейного снижения размерности.
sklearn.decomposition.KernelPCAНелинейное снижение размерности с использованием ядер и PCA.
MDSМногообразие обучения с использованием многомерного масштабирования.
TSNEСтохастическое вложение соседей с t-распределением.
LocallyLinearEmbeddingОбучение многообразий с использованием локально линейного вложения.
SpectralEmbeddingСпектральное вложение для нелинейного снижения размерности.
Ссылки
[1]Tenenbaum, J.B.; De Silva, V.; & Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 290 (5500)
Примеры
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import Isomap >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = Isomap(n_components=2) >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
- fit(X, y=None)[источник]#
Вычислить векторы вложения для данных X.
- Параметры:
- X{array-like, sparse matrix, BallTree, KDTree, NearestNeighbors}
Данные выборки, форма = (n_samples, n_features), в виде массива numpy, разреженной матрицы, предварительно вычисленного дерева или объекта NearestNeighbors.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает обученный экземпляр self.
- fit_transform(X, y=None)[источник]#
Обучить модель на данных X и преобразовать X.
- Параметры:
- X{array-like, sparse matrix, BallTree, KDTree}
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- X_newarray-like, формы (n_samples, n_components)
X преобразован в новое пространство.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- reconstruction_error()[источник]#
Вычислить ошибку реконструкции для вложения.
- Возвращает:
- reconstruction_errorfloat
Ошибка реконструкции.
Примечания
Функция стоимости вложения изомэпа
E = frobenius_norm[K(D) - K(D_fit)] / n_samplesГде D — матрица расстояний для входных данных X, D_fit — матрица расстояний для выходного вложения X_fit, а K — ядро изомэпа:
K(D) = -0.5 * (I - 1/n_samples) * D^2 * (I - 1/n_samples)
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать X.
Это реализовано путём связывания точек X в граф геодезических расстояний обучающих данных. Сначала
n_neighborsближайшие соседи X находятся в обучающих данных, и из них вычисляются кратчайшие геодезические расстояния от каждой точки в X до каждой точки в обучающих данных, чтобы построить ядро. Вложение X - это проекция этого ядра на векторы вложения обучающего набора.- Параметры:
- X{array-like, sparse matrix}, форма (n_queries, n_features)
Если neighbors_algorithm='precomputed', предполагается, что X — это матрица расстояний или разреженный граф формы (n_queries, n_samples_fit).
- Возвращает:
- X_newмассивоподобный, форма (n_queries, n_components)
X преобразован в новое пространство.
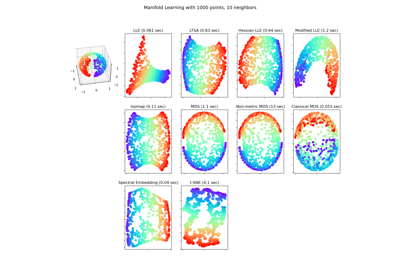
Примеры галереи#

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…