HashingVectorizer#
-
класс sklearn.feature_extraction.text.HashingVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', n_features=1048576, binary=False, norm='l2', alternate_sign=True, dtype=
Преобразовать коллекцию текстовых документов в матрицу встречаемости токенов.
Преобразует коллекцию текстовых документов в разреженную матрицу scipy.sparse, содержащую количества вхождений токенов (или бинарную информацию о вхождении), возможно нормализованную как частоты токенов, если norm='l1', или спроецированную на евклидову единичную сферу, если norm='l2'.
Эта реализация векторизатора текста использует хеширование для сопоставления строки токена с целочисленным индексом признака.
Эта стратегия имеет несколько преимуществ:
он очень экономичен по памяти и масштабируем для больших наборов данных, так как нет необходимости хранить словарь терминов в памяти.
быстро сериализуется и десериализуется, так как не содержит состояния, кроме параметров конструктора.
его можно использовать в потоковом (частичное обучение) или параллельном конвейере, так как во время обучения не вычисляется состояние.
Также есть несколько недостатков (по сравнению с использованием CountVectorizer с словарем в памяти):
нет способа вычислить обратное преобразование (от индексов признаков к строковым именам признаков), что может быть проблемой при попытке интроспекции, какие признаки наиболее важны для модели.
могут возникать коллизии: различные токены могут быть отображены на один и тот же индекс признака. Однако на практике это редко является проблемой, если n_features достаточно велико (например, 2 ** 18 для задач классификации текста).
без взвешивания IDF, так как это сделало бы преобразователь сохраняющим состояние.
Используемая хеш-функция — 32-битная версия Murmurhash3 со знаком.
Для сравнения эффективности различных экстракторов признаков см. Сравнение FeatureHasher и DictVectorizer.
Для примера кластеризации документов и сравнения с
TfidfVectorizer, см. Кластеризация текстовых документов с использованием k-means.Подробнее в Руководство пользователя.
- Параметры:
- входные данные{'filename', 'file', 'content'}, по умолчанию='content'
Если
'filename', последовательность, передаваемая в качестве аргумента в fit, ожидается быть списком имён файлов, которые необходимо прочитать для получения исходного содержимого для анализа.Если
'file', элементы последовательности должны иметь метод 'read' (объект, подобный файлу), который вызывается для получения байтов в памяти.Если
'content', ожидается, что входные данные будут последовательностью элементов, которые могут быть строкового или байтового типа.
- кодировкаstr, по умолчанию='utf-8'
Если для анализа переданы байты или файлы, это кодирование используется для декодирования.
- decode_error{‘strict’, ‘ignore’, ‘replace’}, по умолчанию ‘strict’
Инструкция о том, что делать, если для анализа предоставлена байтовая последовательность, содержащая символы, не соответствующие заданному
encoding. По умолчанию это 'strict', что означает, что будет вызвана ошибка UnicodeDecodeError. Другие значения: 'ignore' и 'replace'.- strip_accents{'ascii', 'unicode'} или вызываемый объект, по умолчанию=None
Удаление акцентов и выполнение другой нормализации символов на этапе предварительной обработки. 'ascii' — быстрый метод, который работает только с символами, имеющими прямое отображение в ASCII. 'unicode' — немного более медленный метод, который работает с любыми символами. None (по умолчанию) означает, что нормализация символов не выполняется.
И 'ascii', и 'unicode' используют нормализацию NFKD из
unicodedata.normalize.- нижний регистрbool, по умолчанию=True
Преобразовать все символы в нижний регистр перед токенизацией.
- препроцессорвызываемый объект, по умолчанию=None
Переопределить этап предобработки (преобразование строк), сохраняя шаги токенизации и генерации n-грамм. Применяется только если
analyzerне является вызываемым.- токенизаторвызываемый объект, по умолчанию=None
Переопределить шаг токенизации строк, сохраняя шаги предобработки и генерации n-грамм. Применяется только если
analyzer == 'word'.- stop_words{‘english’}, list, default=None
Если 'english', используется встроенный список стоп-слов для английского языка. Существует несколько известных проблем с 'english', и вам следует рассмотреть альтернативу (см. Использование стоп-слов).
Если список, предполагается, что этот список содержит стоп-слова, все из которых будут удалены из результирующих токенов. Применяется только если
analyzer == 'word'.- token_patternstr или None, default=r"(?u)\b\w\w+\b"
Регулярное выражение, обозначающее, что составляет «токен», используется только если
analyzer == 'word'. По умолчанию регулярное выражение выбирает токены из 2 или более буквенно-цифровых символов (знаки пунктуации полностью игнорируются и всегда рассматриваются как разделители токенов).Если в token_pattern есть захватывающая группа, то захваченное содержимое группы, а не все совпадение, становится токеном. Допускается не более одной захватывающей группы.
- ngram_rangeкортеж (min_n, max_n), по умолчанию=(1, 1)
Нижняя и верхняя границы диапазона значений n для извлечения различных n-грамм. Все значения n, такие что min_n <= n <= max_n, будут использованы. Например,
ngram_rangeof(1, 1)означает только униграммы,(1, 2)означает униграммы и биграммы, и(2, 2)означает только биграммы. Применяется только еслиanalyzerне является вызываемым.- analyzer{‘word’, ‘char’, ‘char_wb’} или вызываемый, по умолчанию='word'
Должен ли признак состоять из n-грамм слов или символов. Опция 'char_wb' создает символьные n-граммы только из текста внутри границ слов; n-граммы на краях слов дополняются пробелом.
Если передана вызываемая функция, она используется для извлечения последовательности признаков из необработанного входного сигнала.
Изменено в версии 0.21: Начиная с версии 0.21, если
inputявляется'filename'или'file', данные сначала считываются из файла, а затем передаются заданному вызываемому анализатору.- n_featuresint, default=(2 ** 20)
Количество признаков (столбцов) в выходных матрицах. Малое количество признаков может привести к коллизиям хешей, но большое количество приведет к большей размерности коэффициентов в линейных моделях.
- бинарныйbool, по умолчанию=False
Если True, все ненулевые счётчики устанавливаются в 1. Это полезно для дискретных вероятностных моделей, которые моделируют бинарные события, а не целочисленные счётчики.
- norm{‘l1’, ‘l2’}, по умолчанию=’l2’
Норма, используемая для нормализации векторов терминов. None означает отсутствие нормализации.
- alternate_signbool, по умолчанию=True
Когда установлено True, к признакам добавляется чередующийся знак, чтобы приблизительно сохранить скалярное произведение в хешированном пространстве даже для малого n_features. Этот подход аналогичен разреженному случайному проецированию.
Добавлено в версии 0.19.
- dtypeтип, по умолчанию=np.float64
Тип матрицы, возвращаемой fit_transform() или transform().
Смотрите также
CountVectorizerПреобразование коллекции текстовых документов в матрицу количества токенов.
TfidfVectorizerПреобразовать коллекцию необработанных документов в матрицу признаков TF-IDF.
Примечания
Этот оценщик без состояния и не требует обучения. Однако мы рекомендуем вызывать
fit_transformвместоtransform, так как проверка параметров выполняется только вfit.Примеры
>>> from sklearn.feature_extraction.text import HashingVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = HashingVectorizer(n_features=2**4) >>> X = vectorizer.fit_transform(corpus) >>> print(X.shape) (4, 16)
- build_analyzer()[источник]#
Возвращает вызываемый объект для обработки входных данных.
Вызываемый объект обрабатывает предобработку, токенизацию и генерацию n-грамм.
- Возвращает:
- analyzer: вызываемый объект
Функция для обработки предварительной обработки, токенизации и генерации n-грамм.
- build_preprocessor()[источник]#
Возвращает функцию для предварительной обработки текста перед токенизацией.
- Возвращает:
- препроцессор: вызываемый объект
Функция для предварительной обработки текста перед токенизацией.
- build_tokenizer()[источник]#
Возвращает функцию, которая разбивает строку на последовательность токенов.
- Возвращает:
- tokenizer: вызываемый объект
Функция для разделения строки на последовательность токенов.
- декодировать(doc)[источник]#
Декодировать входные данные в строку символов Unicode.
Стратегия декодирования зависит от параметров векторизатора.
- Параметры:
- docbytes или str
Строка для декодирования.
- Возвращает:
- doc: str
Строка символов юникода.
- fit(X, y=None)[источник]#
Проверяет только параметры оценщика.
Этот метод позволяет: (i) проверить параметры оценщика и (ii) быть совместимым с API трансформеров scikit-learn.
- Параметры:
- Xndarray формы [n_samples, n_features]
Обучающие данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Экземпляр HashingVectorizer.
- fit_transform(X, y=None)[источник]#
Преобразовать последовательность документов в матрицу документ-термин.
- Параметры:
- Xитерируемый объект по исходным текстовым документам, длина = n_samples
Образцы. Каждый образец должен быть текстовым документом (либо байты, либо строки Unicode, имя файла или файловый объект в зависимости от аргумента конструктора), который будет токенизирован и хеширован.
- yлюбой
Игнорируется. Этот параметр существует только для совместимости с sklearn.pipeline.Pipeline.
- Возвращает:
- Xразреженная матрица формы (n_samples, n_features)
Матрица документ-термин.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- get_stop_words()[источник]#
Построить или получить эффективный список стоп-слов.
- Возвращает:
- stop_words: list или None
Список стоп-слов.
- partial_fit(X, y=None)[источник]#
Проверяет только параметры оценщика.
Этот метод позволяет: (i) проверить параметры оценщика и (ii) быть совместимым с API трансформеров scikit-learn.
- Параметры:
- Xndarray формы [n_samples, n_features]
Обучающие данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Экземпляр HashingVectorizer.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать последовательность документов в матрицу документ-термин.
- Параметры:
- Xитерируемый объект по исходным текстовым документам, длина = n_samples
Образцы. Каждый образец должен быть текстовым документом (либо байты, либо строки Unicode, имя файла или файловый объект в зависимости от аргумента конструктора), который будет токенизирован и хеширован.
- Возвращает:
- Xразреженная матрица формы (n_samples, n_features)
Матрица документ-термин.
Примеры галереи#
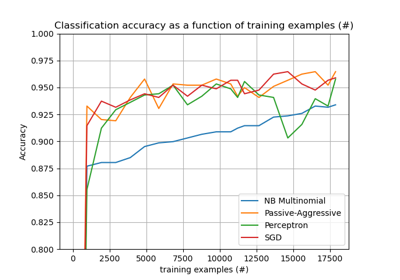
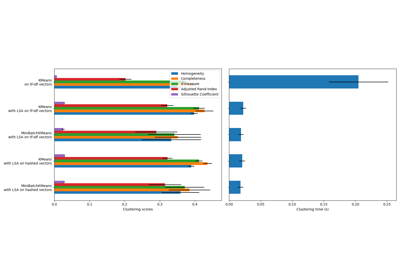
Кластеризация текстовых документов с использованием k-means
