Nystroem#
- класс sklearn.kernel_approximation.Nystroem(ядро='rbf', *, gamma=None, coef0=None, степень=None, kernel_params=None, n_components=100, random_state=None, n_jobs=None)[источник]#
Приближение карты ядра с использованием подмножества обучающих данных.
Создает приближенное отображение признаков для произвольного ядра используя подмножество данных в качестве базиса.
Подробнее в Руководство пользователя.
Добавлено в версии 0.13.
- Параметры:
- ядроstr или callable, по умолчанию='rbf'
Ядерное отображение для аппроксимации. Вызываемый объект должен принимать два аргумента и ключевые аргументы, переданные этому объекту, как
kernel_params, и должен возвращать число с плавающей точкой.- gammafloat, по умолчанию=None
Параметр Gamma для RBF, лапласиана, полинома, экспоненциального chi2 и сигмоидных ядер. Интерпретация значения по умолчанию оставлена на усмотрение ядра; см. документацию sklearn.metrics.pairwise. Игнорируется другими ядрами.
- coef0float, по умолчанию=None
Нулевой коэффициент для полиномиальных и сигмоидных ядер. Игнорируется другими ядрами.
- степеньfloat, по умолчанию=None
Степень полиномиального ядра. Игнорируется другими ядрами.
- kernel_paramsdict, по умолчанию=None
Дополнительные параметры (ключевые аргументы) для функции ядра, передаваемые как вызываемый объект.
- n_componentsint, по умолчанию=100
Количество признаков для построения. Сколько точек данных будет использовано для построения отображения.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Генератор псевдослучайных чисел для управления равномерной выборкой без возвращения
n_componentsобучающих данных для построения базового ядра. Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.- n_jobsint, default=None
Количество заданий для вычисления. Это работает путем разбиения матрицы ядра на
n_jobsравномерные срезы и вычислять их параллельно.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.Добавлено в версии 0.24.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Подмножество обучающих точек, используемых для построения карты признаков.
- component_indices_ndarray формы (n_components)
Индексы
components_в обучающем наборе.- normalization_ndarray формы (n_components, n_components)
Матрица нормализации, необходимая для встраивания. Квадратный корень из матрицы ядра на
components_.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
AdditiveChi2SamplerПриближенное отображение признаков для аддитивного хи-квадрат ядра.
PolynomialCountSketchАппроксимация полиномиального ядра с помощью Tensor Sketch.
RBFSamplerАппроксимируйте карту признаков ядра RBF с использованием случайных признаков Фурье.
SkewedChi2SamplerПриближенное отображение признаков для "скошенного хи-квадрат" ядра.
sklearn.metrics.pairwise.kernel_metricsСписок встроенных ядер.
Ссылки
Williams, C.K.I. and Seeger, M. “Using the Nystroem method to speed up kernel machines”, Advances in neural information processing systems 2001
T. Yang, Y. Li, M. Mahdavi, R. Jin и Z. Zhou "Метод Нистрёма против случайных фурье-признаков: теоретическое и эмпирическое сравнение", Advances in Neural Information Processing Systems 2012
Примеры
>>> from sklearn import datasets, svm >>> from sklearn.kernel_approximation import Nystroem >>> X, y = datasets.load_digits(n_class=9, return_X_y=True) >>> data = X / 16. >>> clf = svm.LinearSVC() >>> feature_map_nystroem = Nystroem(gamma=.2, ... random_state=1, ... n_components=300) >>> data_transformed = feature_map_nystroem.fit_transform(data) >>> clf.fit(data_transformed, y) LinearSVC() >>> clf.score(data_transformed, y) 0.9987...
- fit(X, y=None)[источник]#
Обучить оценщик на данных.
Выбирает подмножество обучающих точек, вычисляет ядро на них и вычисляет матрицу нормализации.
- Параметры:
- Xarray-like, shape (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yarray-like, shape (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Применить отображение признаков к X.
Вычисляет приближенное отображение признаков с использованием ядра между некоторыми точками обучения и X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для преобразования.
- Возвращает:
- X_transformedndarray формы (n_samples, n_components)
Преобразованные данные.
Примеры галереи#

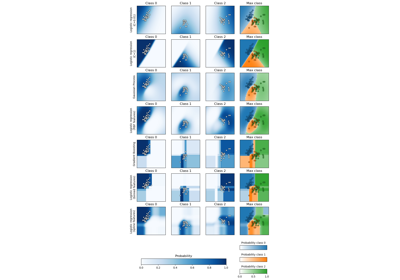
Визуализация вероятностных предсказаний VotingClassifier
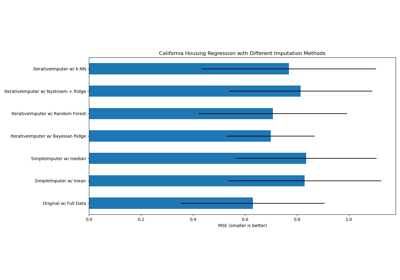
Заполнение пропущенных значений с вариантами IterativeImputer
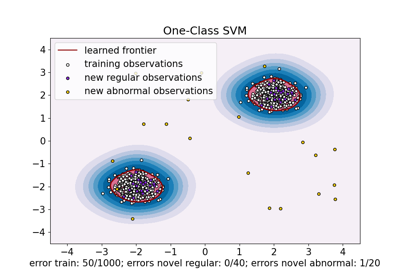
One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска
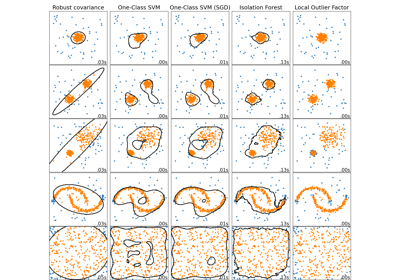
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных
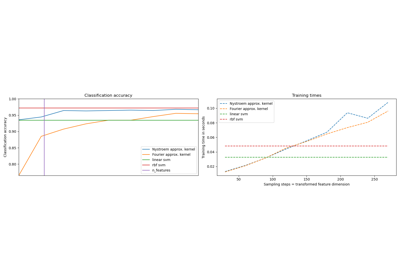
Аппроксимация явного отображения признаков для RBF-ядер