classification_report#
- sklearn.metrics.classification_report(y_true, y_pred, *, метки=None, target_names=None, sample_weight=None, digits=2, output_dict=False, zero_division='warn')[источник]#
Построить текстовый отчет, показывающий основные метрики классификации.
Подробнее в Руководство пользователя.
- Параметры:
- y_true1d array-like, или массив индикаторов меток / разреженная матрица
Истинные (правильные) целевые значения. Разреженная матрица поддерживается только когда цели имеют многометочный тип.
- y_pred1d array-like, или массив индикаторов меток / разреженная матрица
Оцененные цели, возвращаемые классификатором. Разреженная матрица поддерживается только когда цели имеют многометочный тип.
- меткиarray-like формы (n_labels,), по умолчанию=None
Необязательный список индексов меток для включения в отчет.
- target_namesarray-like формы (n_labels,), по умолчанию=None
Необязательные отображаемые имена, соответствующие меткам (в том же порядке).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- digitsint, по умолчанию=2
Количество знаков для форматирования выходных значений с плавающей точкой. Когда
output_dictявляетсяTrue, это будет проигнорировано, и возвращаемые значения не будут округлены.- output_dictbool, по умолчанию=False
Если True, возвращает вывод в виде словаря.
Добавлено в версии 0.20.
- zero_division{"warn", 0.0, 1.0, np.nan}, по умолчанию="warn"
Устанавливает значение, возвращаемое при делении на ноль. Если установлено значение "warn", это действует как 0, но также выдаются предупреждения.
Добавлено в версии 1.3:
np.nanопция была добавлена.
- Возвращает:
- reportstr или dict
Текстовое резюме точности, полноты, F1-меры для каждого класса. Словарь возвращается, если output_dict=True. Словарь имеет следующую структуру:
{'label 1': {'precision':0.5, 'recall':1.0, 'f1-score':0.67, 'support':1}, 'label 2': { ... }, ... }
Сообщаемые средние включают макро-среднее (усреднение невзвешенного среднего по меткам), взвешенное среднее (усреднение среднего, взвешенного по поддержке, по меткам) и выборочное среднее (только для многометочной классификации). Микро-среднее (усреднение общих истинных положительных, ложных отрицательных и ложных положительных результатов) показывается только для многометочной или многоклассовой классификации с подмножеством классов, потому что в противном случае оно соответствует точности и было бы одинаковым для всех метрик. См. также
precision_recall_fscore_supportдля получения дополнительных сведений о средних значениях.Обратите внимание, что в бинарной классификации полнота положительного класса также известна как «чувствительность»; полнота отрицательного класса — «специфичность».
Смотрите также
precision_recall_fscore_supportВычислить точность, полноту, F-меру и поддержку для каждого класса.
confusion_matrixВычисление матрицы ошибок для оценки точности классификации.
multilabel_confusion_matrixВычислить матрицу ошибок для каждого класса или образца.
Примеры
>>> from sklearn.metrics import classification_report >>> y_true = [0, 1, 2, 2, 2] >>> y_pred = [0, 0, 2, 2, 1] >>> target_names = ['class 0', 'class 1', 'class 2'] >>> print(classification_report(y_true, y_pred, target_names=target_names)) precision recall f1-score support class 0 0.50 1.00 0.67 1 class 1 0.00 0.00 0.00 1 class 2 1.00 0.67 0.80 3 accuracy 0.60 5 macro avg 0.50 0.56 0.49 5 weighted avg 0.70 0.60 0.61 5 >>> y_pred = [1, 1, 0] >>> y_true = [1, 1, 1] >>> print(classification_report(y_true, y_pred, labels=[1, 2, 3])) precision recall f1-score support 1 1.00 0.67 0.80 3 2 0.00 0.00 0.00 0 3 0.00 0.00 0.00 0 micro avg 1.00 0.67 0.80 3 macro avg 0.33 0.22 0.27 3 weighted avg 1.00 0.67 0.80 3
Примеры галереи#
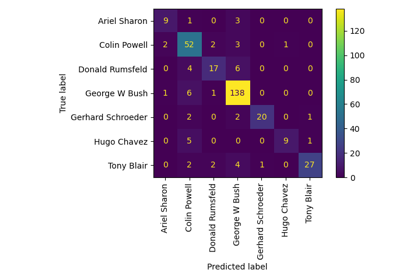
Пример распознавания лиц с использованием собственных лиц и SVM
Трансформер столбцов с разнородными источниками данных


Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией

Признаки ограниченной машины Больцмана для классификации цифр
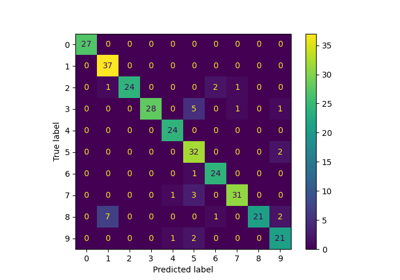
Распространение меток на цифрах: Демонстрация производительности
