KMeans#
- класс sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init='auto', max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, алгоритм='lloyd')[источник]#
Кластеризация K-Means.
Подробнее в Руководство пользователя.
- Параметры:
- n_clustersint, по умолчанию=8
Количество кластеров для формирования, а также количество центроидов для генерации.
Пример того, как выбрать оптимальное значение для
n_clustersобратитесь к Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans.- init{‘k-means++’, ‘random’}, вызываемый объект или массив формы (n_clusters, n_features), по умолчанию=’k-means++’
Метод инициализации:
‘k-means++’ : выбирает начальные центроиды кластеров с использованием выборки, основанной на эмпирическом распределении вероятностей вклада точек в общую инерцию. Этот метод ускоряет сходимость. Реализованный алгоритм - "жадный k-means++". Он отличается от ванильного k-means++ тем, что делает несколько попыток на каждом шаге выборки и выбирает лучший центроид среди них.
‘random’: выбирать
n_clustersнаблюдения (строки) случайным образом из данных для начальных центроидов.Если передается массив, он должен иметь форму (n_clusters, n_features) и задавать начальные центры.
Если передается вызываемый объект, он должен принимать аргументы X, n_clusters и случайное состояние и возвращать инициализацию.
Для примера использования различных
initстратегии, см. Демонстрация кластеризации K-Means на данных рукописных цифр.Для оценки влияния инициализации см. пример Эмпирическая оценка влияния инициализации k-means.
- n_init‘auto’ или int, по умолчанию=’auto’
Количество запусков алгоритма k-средних с разными начальными центроидами. Конечный результат — лучший вывод из
n_initпоследовательных запусков с точки зрения инерции. Несколько запусков рекомендуются для разреженных многомерных задач (см. Кластеризация разреженных данных с помощью k-средних).Когда
n_init='auto', количество запусков зависит от значения init: 10, если используетсяinit='random'илиinitявляется вызываемым объектом; 1, если используетсяinit='k-means++'илиinitявляется array-like.Добавлено в версии 1.2: Добавлена опция 'auto' для
n_init.Изменено в версии 1.4: Значение по умолчанию для
n_initизменено на'auto'.- max_iterint, по умолчанию=300
Максимальное количество итераций алгоритма k-средних для одного запуска.
- tolfloat, по умолчанию=1e-4
Относительный допуск относительно нормы Фробениуса разницы центров кластеров на двух последовательных итерациях для объявления сходимости.
- verboseint, по умолчанию=0
Режим подробности.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для инициализации центроидов. Используйте целое число, чтобы сделать случайность детерминированной. См. Глоссарий.
- copy_xbool, по умолчанию=True
При предварительном вычислении расстояний более численно точно центрировать данные сначала. Если copy_x равен True (по умолчанию), то исходные данные не изменяются. Если False, исходные данные изменяются и возвращаются обратно перед возвратом функции, но могут возникнуть небольшие численные различия из-за вычитания и последующего добавления среднего значения данных. Обратите внимание, что если исходные данные не являются C-непрерывными, копия будет сделана, даже если copy_x равен False. Если исходные данные разреженные, но не в формате CSR, копия будет сделана, даже если copy_x равен False.
- алгоритм{"lloyd", "elkan"}, по умолчанию="lloyd"
Алгоритм K-means для использования. Классический алгоритм в стиле EM — это
"lloyd"."elkan"вариация может быть более эффективной на некоторых наборах данных с четко определенными кластерами, используя неравенство треугольника. Однако она более требовательна к памяти из-за выделения дополнительного массива формы(n_samples, n_clusters).Изменено в версии 0.18: Добавлен алгоритм Элкана
Изменено в версии 1.1: Переименовано "full" в "lloyd", а "auto" и "full" устарели. Изменено "auto" для использования "lloyd" вместо "elkan".
- Атрибуты:
- cluster_centers_ndarray формы (n_clusters, n_features)
Координаты центров кластеров. Если алгоритм останавливается до полной сходимости (см.
tolиmax_iter), эти не будут согласованы сlabels_.- labels_ndarray формы (n_samples,)
Метки каждой точки
- inertia_float
Isomap
- n_iter_int
Количество выполненных итераций.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
MiniBatchKMeansАльтернативная онлайн-реализация, которая выполняет инкрементальные обновления позиций центров с использованием мини-пакетов. Для крупномасштабного обучения (например, n_samples > 10k) MiniBatchKMeans, вероятно, намного быстрее, чем реализация по умолчанию.
Примечания
Задача k-средних решается с использованием алгоритма Ллойда или Элкана.
Средняя сложность задается как O(k n T), где n - количество образцов, а T - количество итераций.
Наихудшая сложность задается как O(n^(k+2/p)) с n = n_samples, p = n_features. См. “Насколько медленен метод k-средних?” D. Arthur и S. Vassilvitskii - SoCG2006. для получения дополнительной информации.
На практике алгоритм k-средних очень быстрый (один из самых быстрых доступных алгоритмов кластеризации), но он попадает в локальные минимумы. Поэтому может быть полезно перезапускать его несколько раз.
Если алгоритм останавливается до полной сходимости (из-за
tolилиmax_iter),labels_иcluster_centers_не будет согласованным, т.е.cluster_centers_не будут средними значениями точек в каждом кластере. Кроме того, оценщик переназначитlabels_после последней итерации, чтобы сделатьlabels_согласовано сpredictна обучающей выборке.Примеры
>>> from sklearn.cluster import KMeans >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [10, 2], [10, 4], [10, 0]]) >>> kmeans = KMeans(n_clusters=2, random_state=0, n_init="auto").fit(X) >>> kmeans.labels_ array([1, 1, 1, 0, 0, 0], dtype=int32) >>> kmeans.predict([[0, 0], [12, 3]]) array([1, 0], dtype=int32) >>> kmeans.cluster_centers_ array([[10., 2.], [ 1., 2.]])
Примеры распространенных проблем с K-Means и способы их решения см. в Демонстрация предположений k-means.
Для демонстрации того, как K-Means может использоваться для кластеризации текстовых документов, см. Кластеризация текстовых документов с использованием k-means.
Для сравнения K-Means и MiniBatchKMeans см. пример Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans.
Для сравнения между K-Means и BisectingKMeans обратитесь к примеру Сравнение производительности биссекционного K-средних и обычного K-средних.
- fit(X, y=None, sample_weight=None)[источник]#
Вычисляет кластеризацию k-средних.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие экземпляры для кластеризации. Следует отметить, что данные будут преобразованы в C-упорядочивание, что вызовет копирование памяти, если предоставленные данные не являются C-непрерывными. Если передана разреженная матрица, будет сделана копия, если она не в формате CSR.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
sample_weightне используется во время инициализации, еслиinitявляется вызываемым объектом или предоставленным пользователем массивом.Добавлено в версии 0.20.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_predict(X, y=None, sample_weight=None)[источник]#
Вычислить центры кластеров и предсказать индекс кластера для каждого образца.
Удобный метод; эквивалентен вызову fit(X) с последующим predict(X).
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- меткиndarray формы (n_samples,)
Индекс кластера, к которому принадлежит каждый образец.
- fit_transform(X, y=None, sample_weight=None)[источник]#
Выполнить кластеризацию и преобразовать X в пространство расстояний до кластеров.
Эквивалентно fit(X).transform(X), но реализовано более эффективно.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- X_newndarray формы (n_samples, n_clusters)
X преобразован в новое пространство.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказывает ближайший кластер, к которому принадлежит каждый образец в X.
В литературе по векторному квантованию,
cluster_centers_называется кодовая книга, и каждое значение, возвращаемоеpredictявляется индексом ближайшего кода в кодовой книге.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для предсказания.
- Возвращает:
- меткиndarray формы (n_samples,)
Индекс кластера, к которому принадлежит каждый образец.
- score(X, y=None, sample_weight=None)[источник]#
Противоположное значение X по целевой функции K-средних.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- scorefloat
Противоположное значение X по целевой функции K-средних.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KMeans[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KMeans[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X)[источник]#
Преобразовать X в пространство расстояний до кластеров.
В новом пространстве каждое измерение — это расстояние до центров кластеров. Обратите внимание, что даже если X разрежен, массив, возвращаемый
transformобычно будет плотной.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- Возвращает:
- X_newndarray формы (n_samples, n_clusters)
X преобразован в новое пространство.
Примеры галереи#
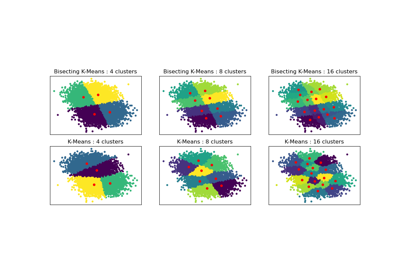
Сравнение производительности биссекционного K-средних и обычного K-средних
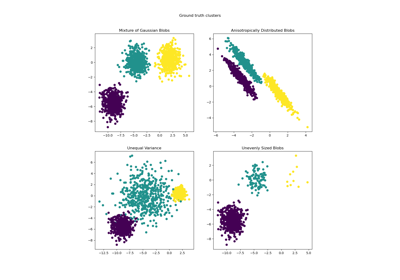
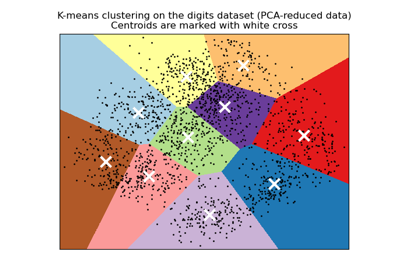
Демонстрация кластеризации K-Means на данных рукописных цифр
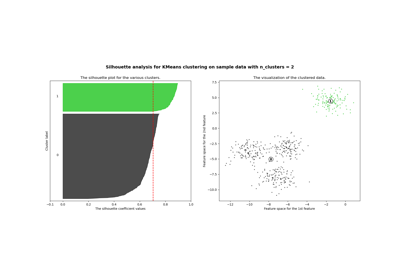
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans
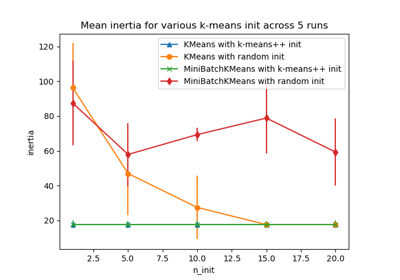
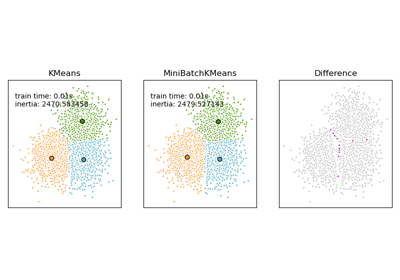
Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans
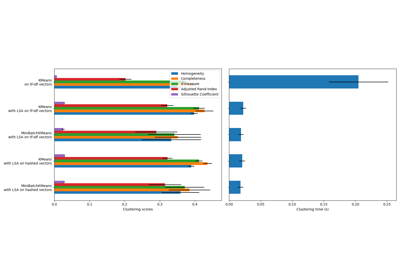
Кластеризация текстовых документов с использованием k-means