Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017). В ACM Transactions on Database Systems (TODS), 42(3), 19.#
- класс sklearn.cluster.Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017). В ACM Transactions on Database Systems (TODS), 42(3), 19.(n_clusters=8, *, eigen_solver=None, n_components=None, random_state=None, n_init=10, gamma=1.0, affinity='rbf', n_neighbors=10, eigen_tol='auto', assign_labels='kmeans', степень=3, coef0=1, kernel_params=None, n_jobs=None, verbose=False)[источник]#
Применить кластеризацию к проекции нормализованного лапласиана.
На практике спектральная кластеризация очень полезна, когда структура отдельных кластеров сильно невыпуклая, или в более общем случае, когда мера центра и разброса кластера не является подходящим описанием всего кластера, например, когда кластеры представляют собой вложенные круги на 2D-плоскости.
Если матрица сходства является матрицей смежности графа, этот метод может использоваться для нахождения нормализованных разрезов графа [1], [2].
При вызове
fit, матрица сходства строится с использованием либо ядерной функции, такой как гауссово (также известное как RBF) ядро с евклидовым расстояниемd(X, X):np.exp(-gamma * d(X,X) ** 2)
или матрица связности k-ближайших соседей.
Альтернативно, пользовательская матрица сходства может быть указана путем установки
affinity='precomputed'.Подробнее в Руководство пользователя.
- Параметры:
- n_clustersint, по умолчанию=8
Размерность проекционного подпространства.
- eigen_solver{‘arpack’, ‘lobpcg’, ‘amg’}, default=None
Стратегия разложения по собственным значениям для использования. AMG требует установки pyamg. Он может быть быстрее на очень больших, разреженных задачах, но также может приводить к нестабильностям. Если None, то
'arpack'используется. См. [4] для получения дополнительных сведений о'lobpcg'.- n_componentsint, default=None
Количество собственных векторов для использования в спектральном вложении. Если None, по умолчанию
n_clusters.- random_stateint, экземпляр RandomState, по умолчанию=None
Псевдослучайный генератор чисел, используемый для инициализации разложения собственных векторов lobpcg, когда
eigen_solver == 'amg', и для инициализации K-Means. Используйте целое число, чтобы результаты были детерминированными между вызовами (см. Глоссарий).Примечание
При использовании
eigen_solver == 'amg', необходимо также зафиксировать глобальное начальное значение numpy с помощьюnp.random.seed(int)для получения детерминированных результатов. См. pyamg/pyamg#139 для дополнительной информации.- n_initint, по умолчанию=10
Количество запусков алгоритма k-средних с разными начальными центрами. Конечные результаты будут лучшим выводом из n_init последовательных запусков с точки зрения инерции. Используется только если
assign_labels='kmeans'.- gammafloat, по умолчанию=1.0
Коэффициент ядра для ядер rbf, poly, sigmoid, laplacian и chi2. Игнорируется для
affinity='nearest_neighbors',affinity='precomputed'илиaffinity='precomputed_nearest_neighbors'.- affinitystr или callable, по умолчанию='rbf'
- Как построить матрицу сходства.
‘nearest_neighbors’: построение матрицы сходства путем вычисления графа ближайших соседей.
'rbf': построить матрицу сходства с использованием радиально-базисной функции (RBF) ядра.
'precomputed': интерпретировать
Xв качестве предвычисленной матрицы сходства, где большие значения указывают на большее сходство между экземплярами.'precomputed_nearest_neighbors': интерпретировать
Xкак разреженный граф предвычисленных расстояний и построить бинарную матрицу сходства изn_neighborsближайших соседей каждого экземпляра.одно из ядер, поддерживаемых
pairwise_kernels.
Следует использовать только ядра, которые дают оценки сходства (неотрицательные значения, возрастающие с увеличением сходства). Это свойство не проверяется алгоритмом кластеризации.
- n_neighborsint, по умолчанию=10
Количество соседей, используемое при построении матрицы сходства методом ближайших соседей. Игнорируется для
affinity='rbf'.- eigen_tolfloat, по умолчанию="auto"
Критерий остановки для собственного разложения матрицы Лапласа. Если
eigen_tol="auto"тогда переданный допуск будет зависеть отeigen_solver:Если
eigen_solver="arpack", затемeigen_tol=0.0;Если
eigen_solver="lobpcg"илиeigen_solver="amg", затемeigen_tol=Noneкоторый настраивает базовыйlobpcgрешатель для автоматического разрешения значения согласно их эвристикам. Смотрите,scipy.sparse.linalg.lobpcgподробности.
Обратите внимание, что при использовании
eigen_solver="lobpcg"илиeigen_solver="amg"значенияtol<1e-5может привести к проблемам сходимости и должен быть избегаем.Добавлено в версии 1.2: Добавлена опция 'auto'.
- assign_labels{‘kmeans’, ‘discretize’, ‘cluster_qr’}, по умолчанию=’kmeans’
Стратегия присвоения меток в пространстве вложения. Существует два способа присвоения меток после лапласианского вложения. k-средних — популярный выбор, но он может быть чувствителен к инициализации. Дискретизация — другой подход, который менее чувствителен к случайной инициализации [3]. Метод cluster_qr [5] непосредственно извлекает кластеры из собственных векторов в спектральной кластеризации. В отличие от k-means и дискретизации, cluster_qr не имеет настраиваемых параметров и не выполняет итераций, но может превзойти k-means и дискретизацию как по качеству, так и по скорости.
Изменено в версии 1.1: Добавлен новый метод маркировки 'cluster_qr'.
- степеньfloat, по умолчанию=3
Степень полиномиального ядра. Игнорируется другими ядрами.
- coef0float, по умолчанию=1
Нулевой коэффициент для полиномиальных и сигмоидных ядер. Игнорируется другими ядрами.
- kernel_paramsdict of str to any, default=None
Параметры (именованные аргументы) и значения для ядра, передаваемые как вызываемый объект. Игнорируется другими ядрами.
- n_jobsint, default=None
Количество параллельных задач для выполнения при
affinity='nearest_neighbors'илиaffinity='precomputed_nearest_neighbors'. Поиск соседей будет выполняться параллельно.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- verbosebool, по умолчанию=False
Режим подробности.
Добавлено в версии 0.24.
- Атрибуты:
- affinity_matrix_array-like формы (n_samples, n_samples)
Матрица сходства, используемая для кластеризации. Доступна только после вызова
fit.- labels_ndarray формы (n_samples,)
Метки каждой точки
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
sklearn.cluster.KMeansКластеризация K-Means.
sklearn.cluster.DBSCANПространственная кластеризация приложений с шумом на основе плотности.
Примечания
Матрица расстояний, в которой 0 указывает на идентичные элементы, а высокие значения указывают на очень различные элементы, может быть преобразована в матрицу сходства / подобия, хорошо подходящую для алгоритма, путем применения гауссова (также известного как RBF, тепловой) ядра:
np.exp(- dist_matrix ** 2 / (2. * delta ** 2))
где
deltaявляется свободным параметром, представляющим ширину гауссова ядра.An alternative is to take a symmetric version of the k-nearest neighbors connectivity matrix of the points.
Если установлен пакет pyamg, он используется: это значительно ускоряет вычисления.
Ссылки
[4]Примеры
>>> from sklearn.cluster import SpectralClustering >>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [1, 0], ... [4, 7], [3, 5], [3, 6]]) >>> clustering = SpectralClustering(n_clusters=2, ... assign_labels='discretize', ... random_state=0).fit(X) >>> clustering.labels_ array([1, 1, 1, 0, 0, 0]) >>> clustering SpectralClustering(assign_labels='discretize', n_clusters=2, random_state=0)
Для сравнения спектральной кластеризации с другими алгоритмами кластеризации см. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
- fit(X, y=None)[источник]#
Выполнить спектральную кластеризацию на основе признаков или матрицы сходства.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Обучающие экземпляры для кластеризации, сходства / аффинности между экземплярами, если
affinity='precomputed', или расстояния между экземплярами, еслиaffinity='precomputed_nearest_neighbors. Если разреженная матрица предоставлена в формате, отличном отcsr_matrix,csc_matrix, илиcoo_matrix, он будет преобразован в разреженнуюcsr_matrix.- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученный экземпляр оценщика.
- fit_predict(X, y=None)[источник]#
Выполнить спектральную кластеризацию на
Xи возвращать метки кластеров.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Обучающие экземпляры для кластеризации, сходства / аффинности между экземплярами, если
affinity='precomputed', или расстояния между экземплярами, еслиaffinity='precomputed_nearest_neighbors. Если разреженная матрица предоставлена в формате, отличном отcsr_matrix,csc_matrix, илиcoo_matrix, он будет преобразован в разреженнуюcsr_matrix.- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- меткиndarray формы (n_samples,)
Метки кластеров.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
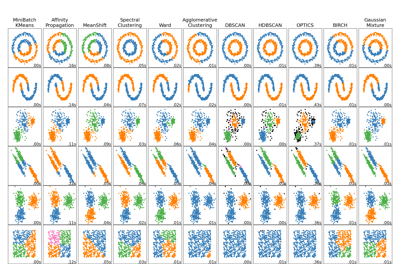
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных