TunedThresholdClassifierCV#
- класс sklearn.model_selection.TunedThresholdClassifierCV(estimator, *, оценка='balanced_accuracy', response_method='auto', пороги=100, cv=None, refit=True, n_jobs=None, random_state=None, store_cv_results=False)[источник]#
Классификатор, который пост-настраивает порог принятия решений с использованием перекрестной проверки.
Этот оценщик пост-настраивает порог принятия решения (точку отсечения), который используется для преобразования оценок апостериорной вероятности (т.е. выхода
predict_proba) или оценки решений (т.е. выходdecision_function) в метку класса. Настройка выполняется путем оптимизации бинарной метрики, потенциально ограниченной другой метрикой.Подробнее в Руководство пользователя.
Добавлено в версии 1.5.
- Параметры:
- estimatorэкземпляр estimator
Классификатор, обученный или нет, для которого мы хотим оптимизировать порог принятия решения, используемый во время
predict.- оценкаstr или callable, по умолчанию="balanced_accuracy"
Целевая метрика для оптимизации. Может быть одной из:
str: строка, связанная с функцией оценки для бинарной классификации, см. Строковые имена скореров для опций.
callable: вызываемый объект scorer (например, функция) с сигнатурой
scorer(estimator, X, y). См. Вызываемые скореры подробности.
- response_method{“auto”, “decision_function”, “predict_proba”}, по умолчанию=”auto”
Методы классификатора
estimatorсоответствующий функции принятия решения, для которой мы хотим найти порог. Это может быть:if
"auto", он попытается вызвать для каждого классификатора,"predict_proba"или"decision_function"в таком порядке.в противном случае, один из
"predict_proba"или"decision_function". Если метод не реализован классификатором, он вызовет ошибку.
- порогиint или array-like, по умолчанию=100
Количество порогов решений для использования при дискретизации выхода классификатора
method. Передайте массивоподобный объект, чтобы вручную указать используемые пороги.- cvint, float, генератор перекрестной проверки, итерируемый или "prefit", default=None
Определяет стратегию разделения перекрестной проверки для обучения классификатора. Возможные входные данные для cv:
None, чтобы использовать стандартную 5-кратную стратифицированную K-кратную перекрестную проверку;Целое число для указания количества фолдов в стратифицированной k-кратной перекрестной проверке;
Число с плавающей точкой для указания одного перемешанного разбиения. Число с плавающей точкой должно быть в (0, 1) и представлять размер валидационного набора;
Объект, который будет использоваться как генератор перекрёстной проверки;
Итерируемый объект, возвращающий разделения на обучающую и тестовую выборки;
"prefit", чтобы обойти перекрестную проверку.
Обратитесь Руководство пользователя для различных стратегий перекрестной проверки, которые можно использовать здесь.
Предупреждение
Используя
cv="prefit"и передавая тот же набор данных для обученияestimatorи настройка точки отсечения подвержена нежелательному переобучению. Вы можете обратиться к Соображения относительно переобучения модели и перекрестной проверки для примера.Эта опция должна использоваться только тогда, когда набор, используемый для подгонки
estimatorотличается от того, который используется для настройки точки отсечения (путем вызоваTunedThresholdClassifierCV.fit).- refitbool, по умолчанию=True
) для обеспечения согласованного поведения вместо использования
refit=Falseпри кросс-валидации с более чем одним разбиением вызовет ошибку. Аналогично,refit=Trueв сочетании сcv="prefit"вызовет ошибку.- n_jobsint, default=None
Количество задач для параллельного выполнения. Когда
cvпредставляет стратегию перекрестной проверки, подгонка и оценка на каждом разделе данных выполняются параллельно.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет случайностью перекрестной проверки, когда
cv, это предсказание находится в том же целевом пространстве, которое использовалось при обучении (например, одно из {'красный', 'янтарный', 'зелёный'}, если Глоссарий.- store_cv_resultsbool, по умолчанию=False
Сохранять ли все оценки и пороги, вычисленные в процессе перекрестной проверки.
- Атрибуты:
- estimator_экземпляр estimator
Обученный классификатор, используемый при предсказании.
- best_threshold_float
Новый порог принятия решений.
- best_score_float или None
Оптимальное значение целевой метрики, вычисленное на
best_threshold_.- cv_results_dict или None
Словарь, содержащий оценки и пороги, вычисленные в процессе перекрестной проверки. Существует только если
store_cv_results=True. Ключи:"thresholds"и"scores".classes_ndarray формы (n_classes,)Метки классов.
- n_features_in_int
Количество признаков, замеченных во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Смотрите также
sklearn.model_selection.FixedThresholdClassifierКлассификатор, использующий постоянный порог.
sklearn.calibration.CalibratedClassifierCVОценщик, который калибрует вероятности.
Примеры
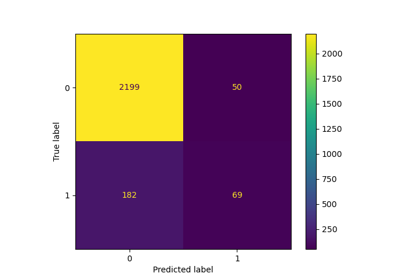
>>> from sklearn.datasets import make_classification >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.metrics import classification_report >>> from sklearn.model_selection import TunedThresholdClassifierCV, train_test_split >>> X, y = make_classification( ... n_samples=1_000, weights=[0.9, 0.1], class_sep=0.8, random_state=42 ... ) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, stratify=y, random_state=42 ... ) >>> classifier = RandomForestClassifier(random_state=0).fit(X_train, y_train) >>> print(classification_report(y_test, classifier.predict(X_test))) precision recall f1-score support 0 0.94 0.99 0.96 224 1 0.80 0.46 0.59 26 accuracy 0.93 250 macro avg 0.87 0.72 0.77 250 weighted avg 0.93 0.93 0.92 250 >>> classifier_tuned = TunedThresholdClassifierCV( ... classifier, scoring="balanced_accuracy" ... ).fit(X_train, y_train) >>> print( ... f"Cut-off point found at {classifier_tuned.best_threshold_:.3f}" ... ) Cut-off point found at 0.342 >>> print(classification_report(y_test, classifier_tuned.predict(X_test))) precision recall f1-score support 0 0.96 0.95 0.96 224 1 0.61 0.65 0.63 26 accuracy 0.92 250 macro avg 0.78 0.80 0.79 250 weighted avg 0.92 0.92 0.92 250
- decision_function(X)[источник]#
Функция принятия решений для образцов в
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- решенияndarray формы (n_samples,)
Функция принятия решений вычисляет обученный оценщик.
- fit(X, y, **params)[источник]#
Обучить классификатор.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yarray-like формы (n_samples,)
Целевые значения.
- **paramsdict
Параметры для передачи в
fitметод базового классификатора.
- Возвращает:
- selfobject
Возвращает экземпляр self.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать цель для новых образцов.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образцы, как принято в
estimator.predict.
- Возвращает:
- class_labelsndarray формы (n_samples,)
Предсказанный класс.
- predict_log_proba(X)[источник]#
Предсказать логарифмические вероятности классов для
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- log_probabilitiesndarray формы (n_samples, n_classes)
Логарифмические вероятности классов входных выборок.
- predict_proba(X)[источник]#
Предсказать вероятности классов для
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- вероятностиndarray формы (n_samples, n_classes)
Вероятности классов входных образцов.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') TunedThresholdClassifierCV[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
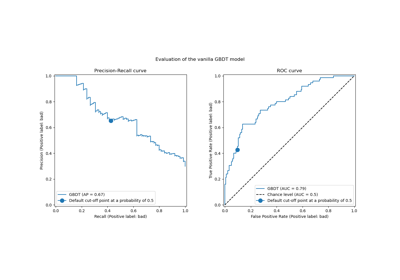
Последующая настройка порога принятия решений для обучения с учетом стоимости
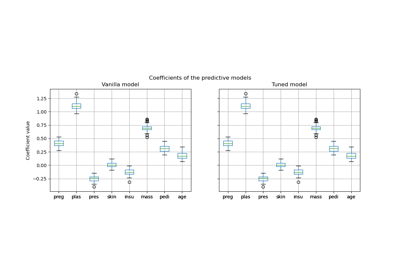
Пост-фактумная настройка точки отсечения функции принятия решений