permutation_importance#
- sklearn.inspection.permutation_importance(estimator, X, y, *, оценка=None, n_repeats=5, n_jobs=None, random_state=None, sample_weight=None, max_samples=1.0)[источник]#
Важность перестановок для оценки признаков [BRE].
The estimator должен быть обученным оценщиком.
Xможет быть набором данных, используемым для обучения оценщика, или отложенной выборкой. Важность перестановки признака рассчитывается следующим образом. Сначала базовый показатель, определенный оценка, оценивается на (возможно, другом) наборе данных, определённомX. Затем признаковый столбец из проверочного набора перемешивается, и метрика вычисляется снова. Важность перестановки определяется как разница между базовой метрикой и метрикой после перестановки признакового столбца.Подробнее в Руководство пользователя.
- Параметры:
- estimatorobject
- Xndarray или DataFrame, форма (n_samples, n_features)
Данные, на которых будет вычисляться важность перестановки.
- yarray-like или None, форма (n_samples, ) или (n_samples, n_classes)
Цели для контролируемого или
Noneдля неконтролируемого.- оценкаstr, callable, list, tuple или dict, по умолчанию=None
Оценщик для использования. Если
scoringпредставляет собой единичную оценку, можно использовать:str: см. Строковые имена скореров для опций.
callable: вызываемый объект scorer (например, функция) с сигнатурой
scorer(estimator, X, y). См. Вызываемые скореры подробности.None:estimator’s критерий оценки по умолчанию используется.
Если
scoringпредставляет несколько оценок, можно использовать:список или кортеж уникальных строк;
вызываемый объект, возвращающий словарь, где ключи — это имена метрик, а значения — оценки метрик;
словарь с именами метрик в качестве ключей и вызываемыми объектами в качестве значений.
Передача нескольких оценок в
scoringболее эффективен, чем вызовpermutation_importanceдля каждого из оценок, так как он повторно использует предсказания, чтобы избежать избыточных вычислений.- n_repeatsint, по умолчанию=5
Количество перестановок признака.
- n_jobsint или None, по умолчанию=None
Количество задач для параллельного выполнения. Вычисление выполняется путем вычисления пермутационного скора для каждого столбца и распараллеливается по столбцам.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState, по умолчанию=None
Псевдослучайный генератор чисел для управления перестановками каждого признака. Передайте целое число для получения воспроизводимых результатов между вызовами функции. Смотрите Глоссарий.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок, используемые при оценке.
Добавлено в версии 0.24.
- max_samplesint или float, по умолчанию=1.0
Количество образцов для выборки из X для вычисления важности признаков в каждом повторении (без замены).
Если int, то нарисовать
max_samplesвыборки.Если float, то нарисовать
max_samples * X.shape[0]выборки.Если
max_samplesравно1.0илиX.shape[0], все образцы будут использованы.
Хотя использование этой опции может давать менее точные оценки важности, она сохраняет метод работоспособным при оценке важности признаков на больших наборах данных. В сочетании с
n_repeats, это позволяет контролировать компромисс между вычислительной скоростью и статистической точностью этого метода.Добавлено в версии 1.0.
- Возвращает:
- результат
Bunchили словарь таких экземпляров Объект, подобный словарю, со следующими атрибутами.
- importances_meanndarray формы (n_features, )
Среднее значение важности признаков по
n_repeats.- importances_stdndarray формы (n_features, )
Стандартное отклонение по
n_repeats.- важностиndarray формы (n_features, n_repeats)
Сырые оценки важности перестановок.
Если в параметре scoring указано несколько метрик оценки
resultэто словарь с именами скореров в качестве ключей (например, ‘roc_auc’) иBunchобъектов, как выше, в качестве значений.
- результат
Ссылки
Примеры
>>> from sklearn.linear_model import LogisticRegression >>> from sklearn.inspection import permutation_importance >>> X = [[1, 9, 9],[1, 9, 9],[1, 9, 9], ... [0, 9, 9],[0, 9, 9],[0, 9, 9]] >>> y = [1, 1, 1, 0, 0, 0] >>> clf = LogisticRegression().fit(X, y) >>> result = permutation_importance(clf, X, y, n_repeats=10, ... random_state=0) >>> result.importances_mean array([0.4666, 0. , 0. ]) >>> result.importances_std array([0.2211, 0. , 0. ])
Примеры галереи#
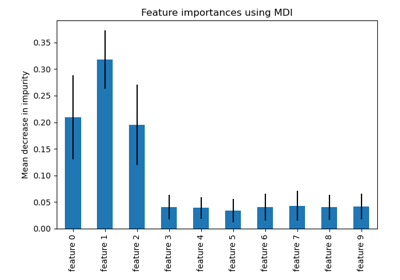

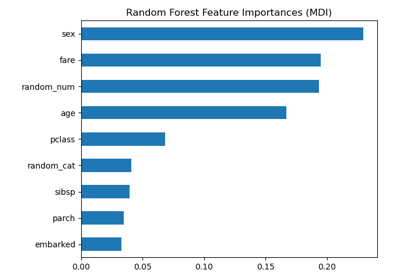
Важность перестановок против важности признаков случайного леса (MDI)
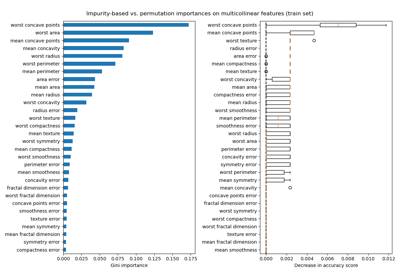
Важность перестановок с мультиколлинеарными или коррелированными признаками
