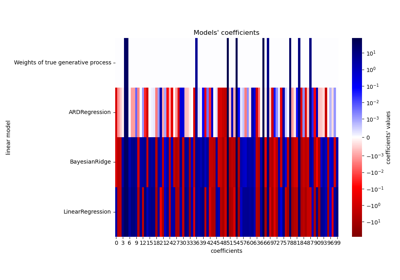
ARDRegression#
- класс sklearn.linear_model.ARDRegression(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, compute_score=False, threshold_lambda=10000.0, fit_intercept=True, copy_X=True, verbose=False)[источник]#
Байесовская ARD-регрессия.
Обучает веса регрессионной модели, используя ARD априор. Веса регрессионной модели предполагаются распределёнными по Гауссу. Также оценивает параметры lambda (точности распределений весов) и alpha (точность распределения шума). Оценка выполняется итеративными процедурами (максимизация правдоподобия)
Подробнее в Руководство пользователя.
- Параметры:
- max_iterint, по умолчанию=300
Максимальное количество итераций.
Изменено в версии 1.3.
- tolfloat, по умолчанию=1e-3
Остановить алгоритм, если w сошелся.
- alpha_1float, по умолчанию=1e-6
Гиперпараметр: параметр формы для априорного распределения Гамма над параметром альфа.
- alpha_2float, по умолчанию=1e-6
Гиперпараметр: обратный параметр масштаба (параметр скорости) для гамма-распределения априорного значения параметра alpha.
- lambda_1float, по умолчанию=1e-6
Гиперпараметр : параметр формы для гамма-распределения априори над параметром lambda.
- lambda_2float, по умолчанию=1e-6
Гиперпараметр: параметр обратного масштаба (параметр скорости) для Гамма-распределения априорного над параметром lambda.
- compute_scorebool, по умолчанию=False
Если True, вычисляет целевую функцию на каждом шаге модели.
- threshold_lambdafloat, default=10 000
Порог для удаления (обрезки) весов с высокой точностью из вычислений.
- fit_interceptbool, по умолчанию=True
Вычислять ли свободный член для этой модели. Если установлено false, свободный член не будет использоваться в вычислениях (т.е. ожидается, что данные центрированы).
- copy_Xbool, по умолчанию=True
Если True, X будет скопирован; иначе, он может быть перезаписан.
- verbosebool, по умолчанию=False
Режим подробного вывода при обучении модели.
- Атрибуты:
- coef_массивоподобный формы (n_features,)
Коэффициенты регрессионной модели (среднее распределения)
- alpha_float
оцененная точность шума.
- lambda_массивоподобный формы (n_features,)
оцененные точности весов.
- sigma_array-like формы (n_features, n_features)
оценочная матрица дисперсии-ковариации весов
- scores_float
если вычислено, значение целевой функции (для максимизации)
- n_iter_int
Фактическое количество итераций для достижения критерия остановки.
Добавлено в версии 1.3.
- intercept_float
Независимый член в функции решения. Установлен в 0.0, если
fit_intercept = False.- X_offset_float
Если
fit_intercept=True, смещение, вычитаемое для центрирования данных к нулевому среднему. В противном случае устанавливается в np.zeros(n_features).- X_scale_float
Установить в np.ones(n_features).
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
BayesianRidgeБайесовская гребневая регрессия.
Ссылки
D. J. C. MacKay, Байесовское нелинейное моделирование для конкурса прогнозирования, Труды ASHRAE, 1994.
R. Salakhutdinov, Лекции по статистическому машинному обучению, http://www.utstat.toronto.edu/~rsalakhu/sta4273/notes/Lecture2.pdf#page=15 Их бета — это наша
self.alpha_Их альфа — это нашаself.lambda_ARD немного отличается от слайда: только размерности/признаки, для которыхself.lambda_ < self.threshold_lambdaсохраняются, а остальные отбрасываются.Примеры
>>> from sklearn import linear_model >>> clf = linear_model.ARDRegression() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) ARDRegression() >>> clf.predict([[1, 1]]) array([1.])
Сравнение линейных байесовских регрессоров демонстрирует ARD регрессию.
Модели на основе L1 для разреженных сигналов демонстрирует ARD-регрессию вместе с Lasso и Elastic-Net для разреженных, коррелированных сигналов в присутствии шума.
- fit(X, y)[источник]#
Обучить модель в соответствии с предоставленными обучающими данными и параметрами.
Итеративная процедура для максимизации свидетельства
- Параметры:
- Xarray-like формы (n_samples, n_features)
Вектор обучения, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения (целые числа). Будут приведены к типу X при необходимости.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X, return_std=False)[источник]#
Прогнозирование с использованием линейной модели.
В дополнение к среднему прогностического распределения, также может быть возвращено его стандартное отклонение.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образцы.
- return_stdbool, по умолчанию=False
Возвращать ли стандартное отклонение апостериорного предсказания.
- Возвращает:
- y_meanarray-like формы (n_samples,)
Среднее апостериорного распределения для запрашиваемых точек.
- y_stdarray-like формы (n_samples,)
Стандартное отклонение прогностического распределения точек запроса.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') ARDRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
predictметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpredictесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpredict.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- return_stdstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
return_stdпараметр вpredict.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ARDRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.