KBinsDiscretizer#
- класс sklearn.preprocessing.KBinsDiscretizer(n_bins=5, *, кодировать='onehot', стратегия='quantile', quantile_method='warn', dtype=None, subsample=200000, random_state=None)[источник]#
Бинирование непрерывных данных в интервалы.
Подробнее в Руководство пользователя.
Добавлено в версии 0.20.
- Параметры:
- n_binsint или array-like формы (n_features,), по умолчанию=5
Количество создаваемых бинов. Вызывает ValueError, если
n_bins < 2.- кодировать{‘onehot’, ‘onehot-dense’, ‘ordinal’}, по умолчанию ‘onehot’
Метод, используемый для кодирования преобразованного результата.
'onehot': Кодировать преобразованный результат с помощью one-hot кодирования и возвращать разреженную матрицу. Игнорируемые признаки всегда добавляются справа.
‘onehot-dense’: Кодировать преобразованный результат с помощью one-hot кодирования и возвращать плотный массив. Игнорируемые признаки всегда добавляются справа.
'ordinal': Возвращает идентификатор бина, закодированный как целочисленное значение.
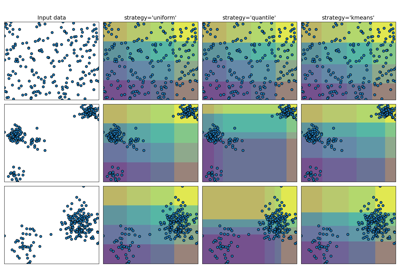
- стратегия{‘uniform’, ‘quantile’, ‘kmeans’}, по умолчанию ‘quantile’
Стратегия определения ширины бинов.
'uniform': Все бины в каждом признаке имеют одинаковую ширину.
'quantile': Все бины в каждом признаке имеют одинаковое количество точек.
‘kmeans’: Значения в каждом бине имеют одинаковый ближайший центр 1D кластера k-средних.
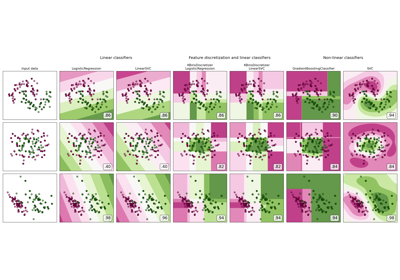
Для примера различных стратегий см.: Демонстрация различных стратегий KBinsDiscretizer.
- quantile_method{“inverted_cdf”, “averaged_inverted_cdf”,
“closest_observation”, “interpolated_inverted_cdf”, “hazen”, “weibull”, “linear”, “median_unbiased”, “normal_unbiased”}, по умолчанию=”linear” Метод для передачи в расчет np.percentile при использовании strategy=”quantile”. Только
averaged_inverted_cdfиinverted_cdfподдерживают использованиеsample_weight != Noneкогда субдискретизация не активна.Добавлено в версии 1.7.
- dtype{np.float32, np.float64}, по умолчанию=None
Желаемый тип данных для вывода. Если None, тип вывода согласован с типом ввода. Поддерживаются только np.float32 и np.float64.
Добавлено в версии 0.24.
- subsampleint или None, по умолчанию=200_000
Максимальное количество образцов, используемых для обучения модели, в целях вычислительной эффективности.
subsample=Noneозначает, что все обучающие образцы используются при вычислении квантилей, определяющих пороги бинирования. Поскольку вычисление квантилей основано на сортировке каждого столбцаXи что сортировка имеетn log(n)временная сложность, рекомендуется использовать подвыборку на наборах данных с очень большим количеством образцов.Изменено в версии 1.3: Значение по умолчанию для
subsampleизменено сNoneto200_000когдаstrategy="quantile".Изменено в версии 1.5: Значение по умолчанию для
subsampleизменено сNoneto200_000когдаstrategy="uniform"илиstrategy="kmeans".- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для субдискретизации. Передайте int для воспроизводимых результатов при множественных вызовах функции. См.
subsampleпараметр для получения дополнительных сведений. См. Глоссарий.Добавлено в версии 1.1.
- Атрибуты:
- bin_edges_ndarray из ndarray формы (n_features,)
Грани каждого бина. Содержат массивы различной формы
(n_bins_, )Игнорируемые признаки будут иметь пустые массивы.- n_bins_ndarray формы (n_features,), dtype=np.int64
Количество бинов на признак. Бины, ширина которых слишком мала (т.е. <= 1e-8), удаляются с предупреждением.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
BinarizerКласс, используемый для бинирования значений как
0или1на основе параметраthreshold.
Примечания
Для визуализации дискретизации на различных наборах данных обратитесь к Дискретизация признаков. О влиянии дискретизации на линейные модели см.: Использование KBinsDiscretizer для дискретизации непрерывных признаков.
В границах бинов для признака
i, первое и последнее значения используются только дляinverse_transform. Во время transform границы бинов расширяются до:np.concatenate([-np.inf, bin_edges_[i][1:-1], np.inf])
Вы можете комбинировать
KBinsDiscretizerсColumnTransformerесли вы хотите предобработать только часть признаков.KBinsDiscretizerможет создавать постоянные признаки (например, когдаencode = 'onehot'и некоторые бины не содержат данных). Эти признаки можно удалить с помощью алгоритмов отбора признаков (например,VarianceThreshold).Примеры
>>> from sklearn.preprocessing import KBinsDiscretizer >>> X = [[-2, 1, -4, -1], ... [-1, 2, -3, -0.5], ... [ 0, 3, -2, 0.5], ... [ 1, 4, -1, 2]] >>> est = KBinsDiscretizer( ... n_bins=3, encode='ordinal', strategy='uniform' ... ) >>> est.fit(X) KBinsDiscretizer(...) >>> Xt = est.transform(X) >>> Xt array([[ 0., 0., 0., 0.], [ 1., 1., 1., 0.], [ 2., 2., 2., 1.], [ 2., 2., 2., 2.]])
Иногда может быть полезно преобразовать данные обратно в исходное пространство признаков. Функция
inverse_transformфункция преобразует бинированные данные обратно в исходное пространство признаков. Каждое значение будет равно среднему значению двух границ бина.>>> est.bin_edges_[0] array([-2., -1., 0., 1.]) >>> est.inverse_transform(Xt) array([[-1.5, 1.5, -3.5, -0.5], [-0.5, 2.5, -2.5, -0.5], [ 0.5, 3.5, -1.5, 0.5], [ 0.5, 3.5, -1.5, 1.5]])
Хотя этот этап предобработки может быть оптимизацией, важно отметить, что массив, возвращаемый
inverse_transformбудет иметь внутренний типnp.float64илиnp.float32, обозначаемыйdtypeвходной аргумент. Это может значительно увеличить использование памяти массивом. См. Пример векторного квантования гдеKBinsDescretizerиспользуется для кластеризации изображения в бины и увеличивает размер изображения в 8 раз.- fit(X, y=None, sample_weight=None)[источник]#
Обучить оценщик.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для дискретизации.
- yNone
Игнорируется. Этот параметр существует только для совместимости с
Pipeline.- sample_weightndarray формы (n_samples,)
Содержит весовые значения, связанные с каждым образцом.
Добавлено в версии 1.3.
Изменено в версии 1.7: Добавлена поддержка strategy="uniform".
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных характеристик.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразует дискретизированные данные обратно в исходное пространство признаков.
Обратите внимание, что эта функция не воссоздаёт исходные данные из-за округления при дискретизации.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Преобразованные данные в бинированном пространстве.
- Возвращает:
- X_originalndarray, dtype={np.float32, np.float64}
Данные в исходном пространстве признаков.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KBinsDiscretizer[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Дискретизируйте данные.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для дискретизации.
- Возвращает:
- Xt{ndarray, sparse matrix}, dtype={np.float32, np.float64}
Данные в бинированном пространстве. Будет разреженной матрицей, если
self.encode='onehot'и ndarray в противном случае.
Примеры галереи#

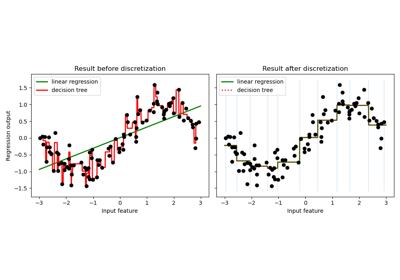
Использование KBinsDiscretizer для дискретизации непрерывных признаков