GaussianMixture#
- класс sklearn.mixture.GaussianMixture(n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[источник]#
Гауссова смесь.
(Иногда recall также называют "чувствительностью")
Подробнее в Руководство пользователя.
Добавлено в версии 0.18.
- Параметры:
- n_componentsint, по умолчанию=1
Количество компонентов смеси.
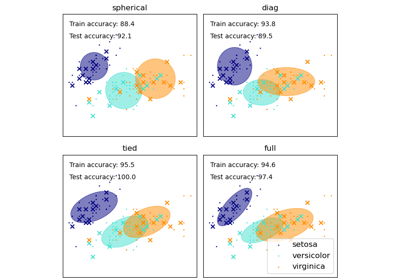
- covariance_type{‘full’, ‘tied’, ‘diag’, ‘spherical’}, по умолчанию=’full’
Строка, описывающая тип параметров ковариации для использования. Должна быть одной из:
'full': каждый компонент имеет свою общую ковариационную матрицу.
‘tied’: все компоненты используют одну и ту же общую ковариационную матрицу.
‘diag’: каждый компонент имеет свою собственную диагональную ковариационную матрицу.
‘spherical’: каждый компонент имеет свою собственную единичную дисперсию.
Первый график визуализирует функцию принятия решений для различных значений параметров на упрощенной задаче классификации, включающей только 2 входных признака и 2 возможных целевых класса (бинарная классификация). Обратите внимание, что такой график невозможно построить для задач с большим количеством признаков или целевых классов.
covariance_type, см. Выбор модели гауссовской смеси.- tolfloat, по умолчанию=1e-3
Порог сходимости. Итерации EM остановятся, когда средний прирост нижней границы будет ниже этого порога.
- reg_covarfloat, по умолчанию=1e-6
Неотрицательная регуляризация, добавленная к диагонали ковариации. Позволяет гарантировать, что ковариационные матрицы являются положительно определенными.
- max_iterint, по умолчанию=100
Количество итераций EM для выполнения.
- n_initint, по умолчанию=1
Количество инициализаций для выполнения. Сохраняются лучшие результаты.
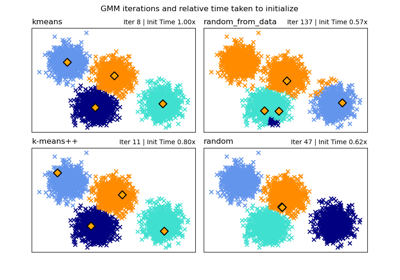
- init_params{‘kmeans’, ‘k-means++’, ‘random’, ‘random_from_data’}, по умолчанию=’kmeans’
Метод, используемый для инициализации весов, средних значений и точностей. Строка должна быть одной из:
'kmeans' : ответственности инициализируются с использованием kmeans.
'k-means++' : используйте метод k-means++ для инициализации.
‘random’ : ответственности инициализируются случайно.
'random_from_data': начальные средние значения случайным образом выбираются из точек данных.
Изменено в версии v1.1:
init_paramsтеперь принимает 'random_from_data' и 'k-means++' в качестве методов инициализации.- weights_initarray-like формы (n_components, ), по умолчанию=None
Пользовательские начальные веса. Если None, веса инициализируются с использованием
init_paramsметод.- means_initarray-like формы (n_components, n_features), по умолчанию=None
Пользовательские начальные средние значения. Если None, средние значения инициализируются с использованием
init_paramsметод.- precisions_initarray-like, default=None
Пользовательские начальные точности (обратные ковариационным матрицам). Если None, точности инициализируются с помощью метода ‘init_params’. Форма зависит от ‘covariance_type’:
(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет случайным начальным числом, передаваемым выбранному методу для инициализации параметров (см.
init_params). Кроме того, он управляет генерацией случайных выборок из подобранного распределения (см. методsample). Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.- warm_startbool, по умолчанию=False
Если 'warm_start' равен True, решение последнего обучения используется как инициализация для следующего вызова fit(). Это может ускорить сходимость, когда fit вызывается несколько раз на похожих задачах. В этом случае 'n_init' игнорируется и происходит только одна инициализация при первом вызове. См. Глоссарий.
- verboseint, по умолчанию=0
Включить подробный вывод. Если 1, то выводится текущая инициализация и каждый шаг итерации. Если больше 1, то также выводятся логарифмическая вероятность и время, необходимое для каждого шага.
- verbose_intervalint, по умолчанию=10
Количество итераций, выполненных перед следующим выводом.
- Атрибуты:
- weights_массивоподобный формы (n_components,)
Веса каждой компоненты смеси.
- means_array-like формы (n_components, n_features)
Среднее значение каждой компоненты смеси.
- covariances_array-like
Ковариация каждой компоненты смеси. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
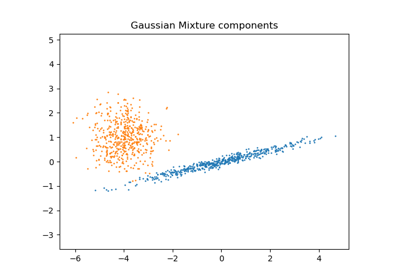
Для примера использования ковариаций см. Ковариации GMM.
- precisions_array-like
Матрицы точности для каждого компонента в смеси. Матрица точности - это обратная матрица ковариации. Матрица ковариации симметрична и положительно определена, поэтому смесь Гауссовых распределений может быть эквивалентно параметризована матрицами точности. Хранение матриц точности вместо матриц ковариации делает вычисление логарифма правдоподобия новых образцов на этапе тестирования более эффективным. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_cholesky_array-like
Разложение Холецкого матриц точности каждой компоненты смеси. Матрица точности является обратной ковариационной матрице. Ковариационная матрица симметрична и положительно определена, поэтому смесь Гауссовых распределений может быть эквивалентно параметризована матрицами точности. Хранение матриц точности вместо ковариационных матриц делает вычисление логарифма правдоподобия новых выборок при тестировании более эффективным. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- converged_. Это приводит к другому графику при вызовеbool
True, когда была достигнута сходимость наилучшего соответствия EM, False в противном случае.
- n_iter_int
Количество шагов, использованных лучшим соответствием EM для достижения сходимости.
- lower_bound_float
Нижняя граница значения логарифма правдоподобия (обучающих данных относительно модели) наилучшего соответствия EM.
- lower_bounds_array-like формы (
n_iter_,) Список значений нижней границы логарифмического правдоподобия из каждой итерации наилучшего соответствия EM.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
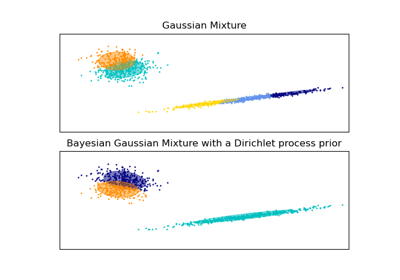
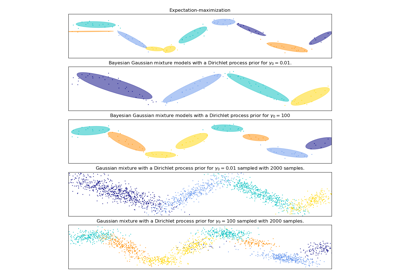
BayesianGaussianMixtureГауссова смесь моделей, обученная с использованием вариационного вывода.
Примеры
>>> import numpy as np >>> from sklearn.mixture import GaussianMixture >>> X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]]) >>> gm = GaussianMixture(n_components=2, random_state=0).fit(X) >>> gm.means_ array([[10., 2.], [ 1., 2.]]) >>> gm.predict([[0, 0], [12, 3]]) array([1, 0])
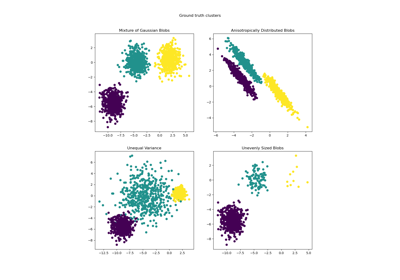
Для сравнения гауссовской смеси с другими алгоритмами кластеризации см. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных.
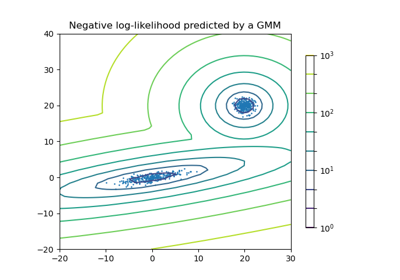
Для иллюстрации поверхности отрицательного логарифма правдоподобия
GaussianMixtureModel, см. Оценка плотности для гауссовской смеси.- aic(X)[источник]#
Информационный критерий Акаике для текущей модели на входных данных X.
Вы можете обратиться к этому математический раздел для получения дополнительной информации относительно формулировки используемого AIC.
- Параметры:
- Xмассив формы (n_samples, n_dimensions)
Входные образцы.
- Возвращает:
- aicfloat
Чем ниже, тем лучше.
- bic(X)[источник]#
Байесовский информационный критерий для текущей модели на входных данных X.
Вы можете обратиться к этому математический раздел для получения дополнительной информации о формулировке используемого BIC.
Для примера выбора GMM с использованием
bicинформационный критерий, см. Выбор модели гауссовской смеси.- Параметры:
- Xмассив формы (n_samples, n_dimensions)
Входные образцы.
- Возвращает:
- bicfloat
Чем ниже, тем лучше.
- fit(X, y=None)[источник]#
Оценить параметры модели с помощью алгоритма EM.
Метод обучает модель
n_initраз и устанавливает параметры, с которыми модель имеет наибольшую вероятность или нижнюю границу. В каждом испытании метод чередует E-шаг и M-шаг дляmax_iterраз, пока изменение правдоподобия или нижней границы не станет меньшеtol, в противном случае,ConvergenceWarningвызывается. Еслиwarm_startявляетсяTrue, затемn_initигнорируется, и единичная инициализация выполняется при первом вызове. При последующих вызовах обучение продолжается с того места, где оно остановилось.- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Подобранная смесь.
- fit_predict(X, y=None)[источник]#
Оценить параметры модели с использованием X и предсказать метки для X.
Метод обучает модель
n_initраз и устанавливает параметры, с которыми модель имеет наибольшую вероятность или нижнюю границу. В каждом испытании метод чередует E-шаг и M-шаг дляmax_iterраз, пока изменение правдоподобия или нижней границы не станет меньшеtol, в противном случае,ConvergenceWarningвызывается. После подгонки он предсказывает наиболее вероятную метку для входных точек данных.Добавлено в версии 0.20.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- меткимассив, формы (n_samples,)
Метки компонентов.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать метки для образцов данных в X с использованием обученной модели.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- меткимассив, формы (n_samples,)
Метки компонентов.
- predict_proba(X)[источник]#
Оцените плотность компонентов для каждого образца.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- respмассив, форма (n_samples, n_components)
Плотность каждой гауссовской компоненты для каждого образца в X.
- sample(n_samples=1)[источник]#
Генерировать случайные выборки из подобранного гауссовского распределения.
- Параметры:
- n_samplesint, по умолчанию=1
Количество образцов для генерации.
- Возвращает:
- Xмассив, форма (n_samples, n_features)
Случайно сгенерированный образец.
- yмассив, форма (nsamples,)
Метки компонентов.
- score(X, y=None)[источник]#
Вычислить среднее логарифмическое правдоподобие на выборку для данных X.
- Параметры:
- Xarray-like формы (n_samples, n_dimensions)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- логарифмическое правдоподобиеfloat
Логарифмическое правдоподобие
Xв рамках модели гауссовской смеси.
- score_samples(X)[источник]#
Вычислить логарифмическое правдоподобие для каждого образца.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- log_probмассив, формы (n_samples,)
Логарифм правдоподобия каждого образца в
Xв рамках текущей модели.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
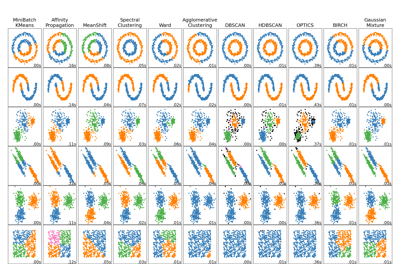
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных