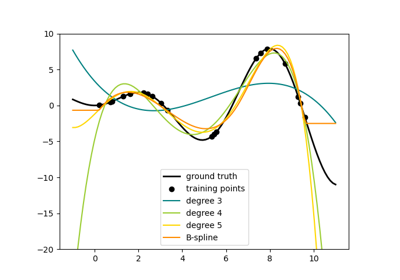
SplineTransformer#
- класс sklearn.preprocessing.SplineTransformer(n_knots=5, степень=3, *, узлы='uniform', экстраполяция='constant', include_bias=True, порядок='C', handle_missing='error', sparse_output=False)[источник]#
Генерация одномерных B-сплайновых базисов для признаков.
Создать новую матрицу признаков, состоящую из
n_splines=n_knots + degree - 1(n_knots - 1дляextrapolation="periodic") базисные функции сплайнов (B-сплайны) полиномиального порядка=`degree` для каждого признака.Чтобы узнать больше о классе SplineTransformer, перейдите к: Инженерия временных признаков
Подробнее в Руководство пользователя.
Добавлено в версии 1.0.
- Параметры:
- n_knotsint, по умолчанию=5
Количество узлов сплайнов, если
knotsравен одному из {‘uniform’, ‘quantile’}. Должен быть больше или равен 2. Игнорируется, еслиknotsявляется array-like.- степеньint, по умолчанию=3
Полиномиальная степень базиса сплайна. Должна быть неотрицательным целым числом.
- узлы{'uniform', 'quantile'} или массивоподобный объект формы (n_knots, n_features), по умолчанию='uniform'
Установите позиции узлов так, чтобы первый узел <= признаки <= последний узел.
Если 'uniform',
n_knotsколичество узлов равномерно распределено от минимальных до максимальных значений признаков.Если 'quantile', они распределены равномерно вдоль квантилей признаков.
Если задан array-like, он напрямую указывает отсортированные позиции узлов, включая граничные узлы. Обратите внимание, что внутренне
degreeколичество узлов добавляется перед первым узлом, столько же после последнего узла.
- экстраполяция{'error', 'constant', 'linear', 'continue', 'periodic'}, по умолчанию='constant'
Если 'error', значения вне минимального и максимального значений обучающих признаков вызывают
ValueError. Если 'constant', значение сплайнов в минимальной и максимальной точке признаков используется как постоянная экстраполяция. Если 'linear', используется линейная экстраполяция. Если 'continue', сплайны экстраполируются как есть, т.е. опцияextrapolate=Trueвscipy.interpolate.BSpline. Если 'periodic', используются периодические сплайны с периодичностью, равной расстоянию между первым и последним узлом. Периодические сплайны обеспечивают равные значения функции и производные на первом и последнем узле. Например, это позволяет избежать введения произвольного скачка между 31 декабря и 1 января в сплайн-признаках, полученных из естественно периодического признака 'день года'. В этом случае рекомендуется вручную установить значения узлов для управления периодичностью.- include_biasbool, по умолчанию=True
Если False, то последний сплайн-элемент внутри диапазона данных признака удаляется. Поскольку B-сплайны суммируются до единицы по базисным функциям сплайна для каждой точки данных, они неявно включают член смещения, т.е. столбец единиц. Он действует как член перехвата в линейных моделях.
- порядок{‘C’, ‘F’}, по умолчанию ‘C’
Порядок выходного массива в плотном случае.
'F'порядок вычисляется быстрее, но может замедлить последующие оценщики.- handle_missing{‘error’, ‘zeros’}, по умолчанию='error'
Определяет способ обработки пропущенных значений.
‘error’ : Вызвать ошибку, если
np.nanзначения присутствуют во времяfit.‘zeros’ : Кодировать сплайны пропущенных значений значениями
0.
Обратите внимание, что
handle_missing='zeros'отличается от первоначального заполнения пропущенных значений нулями и последующего создания сплайн-базиса. Последний создает базисные функции сплайнов, которые имеют ненулевые значения в пропущенных значениях, тогда как этот вариант просто устанавливает все значения базисных функций сплайнов в ноль в пропущенных значениях.Добавлено в версии 1.8.
- sparse_outputbool, по умолчанию=False
Будет возвращать разреженную матрицу CSR, если установлено True, иначе вернет массив.
Добавлено в версии 1.2.
- Атрибуты:
- bsplines_список формы (n_features,)
Список объектов BSplines, по одному для каждого признака.
- n_features_in_int
Общее количество входных признаков.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_features_out_int
Общее количество выходных признаков, которое вычисляется как
n_features * n_splines, гдеn_splinesэто количество базовых элементов B-сплайнов,n_knots + degree - 1для непериодических сплайнов иn_knots - 1для периодических. Еслиinclude_bias=False, тогда это толькоn_features * (n_splines - 1).
Смотрите также
KBinsDiscretizerПреобразователь, который разбивает непрерывные данные на интервалы.
PolynomialFeaturesТрансформер, генерирующий полиномиальные признаки и признаки взаимодействия.
Примечания
Высокие степени и большое количество узлов могут вызвать переобучение.
См. examples/linear_model/plot_polynomial_interpolation.py.
Примеры
>>> import numpy as np >>> from sklearn.preprocessing import SplineTransformer >>> X = np.arange(6).reshape(6, 1) >>> spline = SplineTransformer(degree=2, n_knots=3) >>> spline.fit_transform(X) array([[0.5 , 0.5 , 0. , 0. ], [0.18, 0.74, 0.08, 0. ], [0.02, 0.66, 0.32, 0. ], [0. , 0.32, 0.66, 0.02], [0. , 0.08, 0.74, 0.18], [0. , 0. , 0.5 , 0.5 ]])
- fit(X, y=None, sample_weight=None)[источник]#
Вычисление позиций узлов сплайнов.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные.
- yNone
Игнорируется.
- sample_weightarray-like формы (n_samples,), по умолчанию = None
Индивидуальные веса для каждого образца. Используются для расчета квантилей, если
knots="quantile". Дляknots="uniform", наблюдения с нулевым весом игнорируются при нахождении минимума и максимумаX.
- Возвращает:
- selfobject
Обученный преобразователь.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SplineTransformer[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать данные каждого признака в B-сплайны.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для преобразования.
- Возвращает:
- XBS{ndarray, sparse matrix} формы (n_samples, n_features * n_splines)
Матрица признаков, где n_splines — количество базисных элементов B-сплайнов, n_knots + degree - 1.
Примеры галереи#

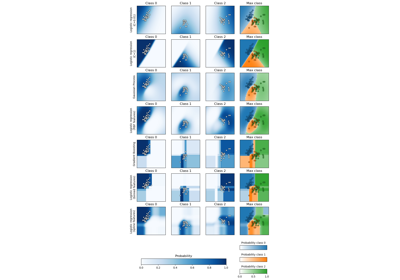
Визуализация вероятностных предсказаний VotingClassifier