LocallyLinearEmbedding#
- класс sklearn.manifold.LocallyLinearEmbedding(*, n_neighbors=5, n_components=2, reg=0.001, eigen_solver='auto', tol=1e-06, max_iter=100, метод='standard', hessian_tol=0.0001, modified_tol=1e-12, neighbors_algorithm='auto', random_state=None, n_jobs=None)[источник]#
Локально-линейное вложение.
Подробнее в Руководство пользователя.
- Параметры:
- n_neighborsint, по умолчанию=5
Количество соседей для рассмотрения каждой точки.
- n_componentsint, по умолчанию=2
Количество координат для многообразия.
- regfloat, по умолчанию=1e-3
Константа регуляризации, умножает след локальной ковариационной матрицы расстояний.
- eigen_solver{‘auto’, ‘arpack’, ‘dense’}, по умолчанию=’auto’
Решатель, используемый для вычисления собственных векторов. Доступные варианты:
'auto': алгоритм попытается выбрать наилучший метод для входных данных.'arpack': используйте итерацию Арнольди в режиме сдвига-инверсии. Для этого метода M может быть плотной матрицей, разреженной матрицей или общим линейным оператором.'dense': использует стандартные операции с плотными матрицами для разложения по собственным значениям. Для этого метода M должен быть массивом или матричным типом. Этот метод следует избегать для больших задач.
Предупреждение
ARPACK может быть нестабильным для некоторых задач. Лучше попробовать несколько случайных начальных значений, чтобы проверить результаты.
- tolfloat, по умолчанию=1e-6
Допуск для метода 'arpack' Не используется, если eigen_solver=='dense'.
- max_iterint, по умолчанию=100
Максимальное количество итераций для солвера arpack. Не используется, если eigen_solver=='dense'.
- метод{'standard', 'hessian', 'modified', 'ltsa'}, по умолчанию='standard'
standard: используйте стандартный алгоритм локально линейного вложения. см. ссылку [1]hessian: использовать метод собственных карт Гессиана. Этот метод требуетn_neighbors > n_components * (1 + (n_components + 1) / 2. см. ссылку [2]modified: используйте модифицированный алгоритм локально линейного вложения. см. ссылку [3]ltsa: использует алгоритм локального выравнивания касательного пространства. см. ссылку [4]
- hessian_tolfloat, по умолчанию=1e-4
Допуск для метода отображения собственных значений гессиана. Используется только если
method == 'hessian'.- modified_tolfloat, default=1e-12
Допуск для модифицированного метода LLE. Используется только если
method == 'modified'.- neighbors_algorithm{‘auto’, ‘brute’, ‘kd_tree’, ‘ball_tree’}, default=’auto’
Алгоритм для поиска ближайших соседей, передаваемый в
NearestNeighborsэкземпляр.- random_stateint, экземпляр RandomState, по умолчанию=None
Определяет генератор случайных чисел, когда
eigen_solver== ‘arpack’. Передайте int для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.- n_jobsint или None, по умолчанию=None
Количество параллельных задач для выполнения.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- embedding_array-like, shape [n_samples, n_components]
Хранит векторы вложений
- reconstruction_error_float
Ошибка реконструкции, связанная с
embedding_- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- nbrs_объект NearestNeighbors
Хранит экземпляр ближайших соседей, включая BallTree или KDtree, если применимо.
Смотрите также
SpectralEmbeddingСпектральное вложение для нелинейного уменьшения размерности.
TSNEРаспределенное стохастическое вложение соседей.
Ссылки
[1]Roweis, S. & Saul, L. Nonlinear dimensionality reduction by locally linear embedding. Science 290:2323 (2000).
[2]Донохо, Д. и Граймс, К. Собственные карты Гессиана: методы локально линейного вложения для данных высокой размерности. Proc Natl Acad Sci U S A. 100:5591 (2003).
[4]Чжан, З. и Чжа, Х. Главные многообразия и нелинейное снижение размерности через выравнивание касательных пространств. Журнал Шанхайского университета. 8:406 (2004)
Примеры
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import LocallyLinearEmbedding >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = LocallyLinearEmbedding(n_components=2) >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
- fit(X, y=None)[источник]#
Вычислить векторы вложения для данных X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающий набор.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученная
LocallyLinearEmbeddingэкземпляр класса.
- fit_transform(X, y=None)[источник]#
Вычисляет векторы вложения для данных X и преобразует X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающий набор.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- X_newarray-like, формы (n_samples, n_components)
Возвращает сам экземпляр.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразование новых точек в пространство вложений.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающий набор.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Возвращает сам экземпляр.
Примечания
Из-за масштабирования, выполняемого этим методом, не рекомендуется использовать его вместе с методами, которые не являются инвариантными к масштабу (как SVM).
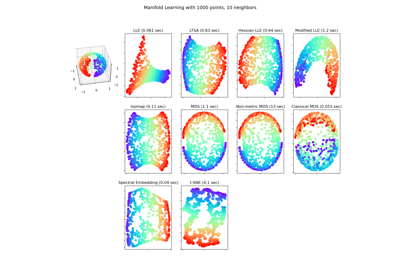
Примеры галереи#

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…