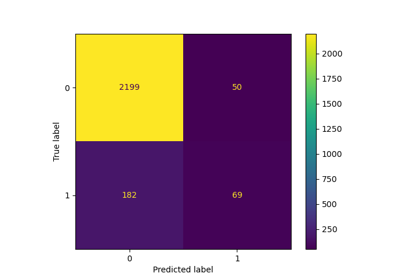
OneHotEncoder#
-
класс sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse_output=True, dtype=
Закодировать категориальные признаки как однократно закодированный числовой массив.
Входные данные для этого преобразователя должны быть массивоподобными целыми числами или строками, обозначающими значения, принимаемые категориальными (дискретными) признаками. Признаки кодируются с использованием схемы one-hot (также известной как 'one-of-K' или 'dummy'). Это создаёт двоичный столбец для каждой категории и возвращает разреженную матрицу или плотный массив (в зависимости от
sparse_outputпараметр).По умолчанию кодировщик определяет категории на основе уникальных значений в каждом признаке. Альтернативно, вы также можете указать
categoriesвручную.Это кодирование необходимо для подачи категориальных данных во многие оценки scikit-learn, в частности, линейные модели и SVM со стандартными ядрами.
Примечание: one-hot кодирование меток y должно использовать LabelBinarizer вместо этого.
Подробнее в Руководство пользователя. Для сравнения различных кодировщиков обратитесь к: Сравнение Target Encoder с другими кодировщиками.
- Параметры:
- категории'auto' или список array-like, по умолчанию='auto'
Категории (уникальные значения) для каждого признака:
'auto' : Определять категории автоматически на основе обучающих данных.
list :
categories[i]содержит категории, ожидаемые в i-м столбце. Переданные категории не должны смешивать строки и числовые значения в пределах одного признака и должны быть отсортированы в случае числовых значений.
Используемые категории можно найти в
categories_атрибут.Добавлено в версии 0.20.
- drop{‘first’, ‘if_binary’} или массивоподобный формы (n_features,), по умолчанию=None
Определяет методологию для удаления одной из категорий на признак. Это полезно в ситуациях, когда идеально коллинеарные признаки вызывают проблемы, например, при передаче полученных данных в нерегуляризованную модель линейной регрессии.
`cross_val_predict` для обучения `final_estimator`. Возможные входные данные для
None : сохранить все признаки (по умолчанию).
'first' : удалить первую категорию в каждом признаке. Если присутствует только одна категория, признак будет полностью удален.
'if_binary': удалить первую категорию в каждом признаке с двумя категориями. Признаки с 1 или более чем 2 категориями остаются без изменений.
массив :
drop[i]это категория в признакеX[:, i]которые следует удалить.
Когда
max_categoriesилиmin_frequencyнастроен на группировку редких категорий, поведение удаления обрабатывается после группировки.Добавлено в версии 0.21: Параметр
dropбыл добавлен в версии 0.21.Изменено в версии 0.23: Опция
drop='if_binary'был добавлен в версии 0.23.Изменено в версии 1.1: Поддержка удаления редких категорий.
- sparse_outputbool, по умолчанию=True
Когда
True, он возвращаетscipy.sparse.csr_matrix, т.е. разреженная матрица в формате "Compressed Sparse Row" (CSR).Добавлено в версии 1.2:
sparseбыл переименован вsparse_output- dtypeтип числа, по умолчанию=np.float64
Желаемый тип данных выходных данных.
- handle_unknown{‘error’, ‘ignore’, ‘infrequent_if_exist’, ‘warn’}, default=’error’
Определяет способ обработки неизвестных категорий во время
transform.‘error’ : Вызвать ошибку, если во время преобразования присутствует неизвестная категория.
'ignore': При встрече неизвестной категории во время преобразования, результирующие one-hot кодированные столбцы для этого признака будут содержать все нули. При обратном преобразовании неизвестная категория будет обозначена как None.
'infrequent_if_exist': При обнаружении неизвестной категории во время преобразования, результирующие столбцы с one-hot кодированием для этого признака будут отображаться на редкую категорию, если она существует. Редкая категория будет отображена на последнюю позицию в кодировании. Во время обратного преобразования неизвестная категория будет отображена на категорию, обозначенную
'infrequent'если он существует. Если'infrequent'категория не существует, тогдаtransformиinverse_transformбудет обрабатывать неизвестную категорию как сhandle_unknown='ignore'. Редкие категории существуют на основеmin_frequencyиmax_categories. Подробнее в Руководство пользователя.'warn': При обнаружении неизвестной категории во время преобразования выдается предупреждение, и кодирование продолжается, как описано для
handle_unknown="infrequent_if_exist".
Изменено в версии 1.1:
'infrequent_if_exist'был добавлен для автоматической обработки неизвестных категорий и редких категорий.Добавлено в версии 1.6: Опция
"warn"был добавлен в версии 1.6.- min_frequencyint или float, по умолчанию=None
Задаёт минимальную частоту, ниже которой категория будет считаться редкой.
Если
int, категории с меньшей мощностью будут считаться редкими.Если
float, категории с меньшей мощностью, чемmin_frequency * n_samplesбудет считаться редким.
Добавлено в версии 1.1: Подробнее в Руководство пользователя.
- max_categoriesint, default=None
Задает верхний предел количества выходных признаков для каждого входного признака при рассмотрении редких категорий. Если есть редкие категории,
max_categoriesвключает категорию, представляющую редкие категории вместе с частыми категориями. ЕслиNone, нет ограничения на количество выходных признаков.Добавлено в версии 1.1: Подробнее в Руководство пользователя.
- feature_name_combiner“concat” или callable, default=”concat”
Вызываемый объект с сигнатурой
def callable(input_feature, category)которая возвращает строку. Это используется для создания имен признаков, возвращаемыхget_feature_names_out."concat"объединяет закодированное имя признака и категорию сfeature + "_" + str(category)Например, признак X со значениями 1, 6, 7 создает имена признаковX_1, X_6, X_7.Добавлено в версии 1.3.
- Атрибуты:
- categories_список массивов
Категории каждого признака, определенные во время обучения (в порядке признаков в X и соответствующие выходным данным
transform). Это включает категорию, указанную вdrop(если есть).- drop_idx_массив формы (n_features,)
drop_idx_[i]является индексом вcategories_[i]категории для удаления для каждого признака.drop_idx_[i] = Noneесли ни одна категория не должна быть удалена из признака с индексомi, например, когдаdrop='if_binary'и признак не является бинарным.drop_idx_ = Noneесли все преобразованные признаки будут сохранены.
Если редкие категории включены путем установки
min_frequencyилиmax_categoriesв нестандартное значение иdrop_idx[i]соответствует редкой категории, тогда вся редкая категория удаляется.Изменено в версии 0.23: Добавлена возможность содержать
Noneзначения.infrequent_categories_list of ndarrayРедкие категории для каждого признака.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 1.0.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- feature_name_combinerвызываемый или None
Вызываемый объект с сигнатурой
def callable(input_feature, category)которая возвращает строку. Это используется для создания имен признаков, возвращаемыхget_feature_names_out.Добавлено в версии 1.3.
Смотрите также
OrdinalEncoderВыполняет порядковое (целочисленное) кодирование категориальных признаков.
TargetEncoderКодирует категориальные признаки с использованием целевой переменной.
sklearn.feature_extraction.DictVectorizerВыполняет one-hot кодирование элементов словаря (также обрабатывает строковые признаки).
sklearn.feature_extraction.FeatureHasherВыполняет приближённое one-hot кодирование элементов словаря или строк.
LabelBinarizerБинаризует метки в формате 'один против всех'.
MultiLabelBinarizerПреобразует между итерируемыми объектами и многометочным форматом, например, бинарной матрицей (образцы × классы), указывающей наличие метки класса.
Примеры
Для набора данных с двумя признаками мы позволяем кодировщику найти уникальные значения для каждого признака и преобразовать данные в бинарное one-hot кодирование.
>>> from sklearn.preprocessing import OneHotEncoder
Можно отбросить категории, не встречавшиеся во время
fit:>>> enc = OneHotEncoder(handle_unknown='ignore') >>> X = [['Male', 1], ['Female', 3], ['Female', 2]] >>> enc.fit(X) OneHotEncoder(handle_unknown='ignore') >>> enc.categories_ [array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)] >>> enc.transform([['Female', 1], ['Male', 4]]).toarray() array([[1., 0., 1., 0., 0.], [0., 1., 0., 0., 0.]]) >>> enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]]) array([['Male', 1], [None, 2]], dtype=object) >>> enc.get_feature_names_out(['gender', 'group']) array(['gender_Female', 'gender_Male', 'group_1', 'group_2', 'group_3'], ...)
Можно всегда удалить первый столбец для каждого признака:
>>> drop_enc = OneHotEncoder(drop='first').fit(X) >>> drop_enc.categories_ [array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)] >>> drop_enc.transform([['Female', 1], ['Male', 2]]).toarray() array([[0., 0., 0.], [1., 1., 0.]])
Или удалить столбец для признака, имеющего только 2 категории:
>>> drop_binary_enc = OneHotEncoder(drop='if_binary').fit(X) >>> drop_binary_enc.transform([['Female', 1], ['Male', 2]]).toarray() array([[0., 1., 0., 0.], [1., 0., 1., 0.]])
Можно изменить способ создания названий признаков.
>>> def custom_combiner(feature, category): ... return str(feature) + "_" + type(category).__name__ + "_" + str(category) >>> custom_fnames_enc = OneHotEncoder(feature_name_combiner=custom_combiner).fit(X) >>> custom_fnames_enc.get_feature_names_out() array(['x0_str_Female', 'x0_str_Male', 'x1_int_1', 'x1_int_2', 'x1_int_3'], dtype=object)
Редкие категории включаются установкой
max_categoriesилиmin_frequency.>>> import numpy as np >>> X = np.array([["a"] * 5 + ["b"] * 20 + ["c"] * 10 + ["d"] * 3], dtype=object).T >>> ohe = OneHotEncoder(max_categories=3, sparse_output=False).fit(X) >>> ohe.infrequent_categories_ [array(['a', 'd'], dtype=object)] >>> ohe.transform([["a"], ["b"]]) array([[0., 0., 1.], [1., 0., 0.]])
- fit(X, y=None)[источник]#
Обучить OneHotEncoder на X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для определения категорий каждого признака.
- yNone
Игнорируется. Этот параметр существует только для совместимости с
Pipeline.
- Возвращает:
- self
Обученный энкодер.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразовать данные обратно в исходное представление.
Когда встречаются неизвестные категории (все нули в one-hot кодировании),
Noneиспользуется для представления этой категории. Если признак с неизвестной категорией имеет отброшенную категорию, отброшенная категория будет его инверсией.Для заданного входного признака, если есть редкая категория, 'infrequent_sklearn' будет использоваться для представления редкой категории.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_encoded_features)
Преобразованные данные.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Обратно преобразованный массив.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразование X с использованием one-hot кодирования.
Если
sparse_output=True(по умолчанию), возвращает экземплярscipy.sparse._csr.csr_matrix(формат CSR).Если есть редкие категории для признака, установленные путем указания
max_categoriesилиmin_frequency, редкие категории группируются в одну категорию.- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для кодирования.
- Возвращает:
- X_out{ndarray, разреженная матрица} формы (n_samples, n_encoded_features)
Преобразованный ввод. Если
sparse_output=True, будет возвращена разреженная матрица.
Примеры галереи#

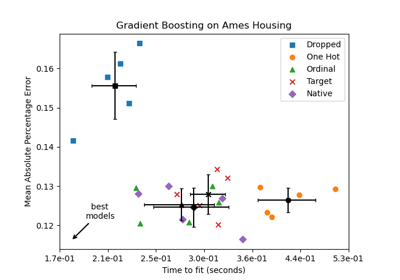
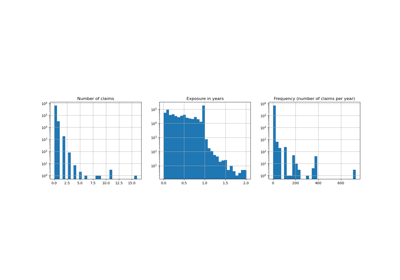
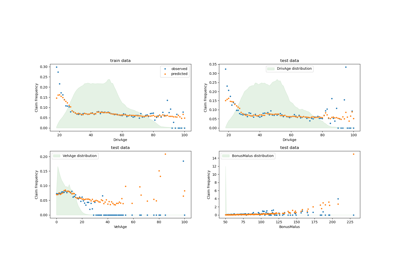
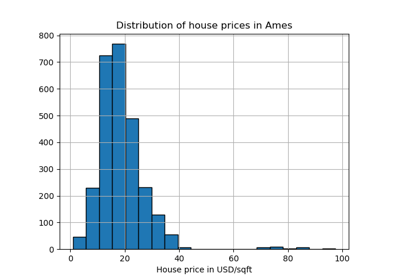
Поддержка категориальных признаков в градиентном бустинге


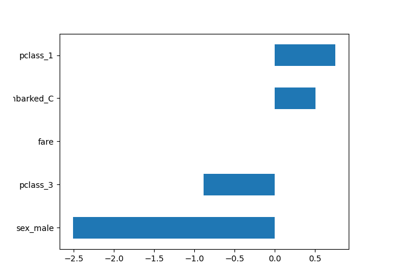
Распространённые ошибки в интерпретации коэффициентов линейных моделей
Графики частичной зависимости и индивидуального условного ожидания