FastICA#
- класс sklearn.decomposition.FastICA(n_components=None, *, алгоритм='parallel', whiten='unit-variance', fun='logcosh', fun_args=None, max_iter=200, tol=0.0001, w_init=None, whiten_solver='svd', random_state=None)[источник]#
FastICA: быстрый алгоритм для независимого компонентного анализа.
Реализация основана на [1].
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, default=None
Количество компонентов для использования. Если передано None, используются все.
- алгоритм{‘parallel’, ‘deflation’}, по умолчанию=’parallel’
Укажите, какой алгоритм использовать для FastICA.
- whitenstr или bool, по умолчанию=’unit-variance’
Укажите стратегию отбеливания для использования.
Если ‘arbitrary-variance’, используется отбеливание с произвольной дисперсией.
Если 'unit-variance', матрица отбеливания масштабируется так, чтобы каждый восстановленный источник имел единичную дисперсию.
Если False, данные уже считаются отбеленными, и отбеливание не выполняется.
Изменено в версии 1.3: Значение по умолчанию для
whitenизменено на 'unit-variance' в версии 1.3.- fun{‘logcosh’, ‘exp’, ‘cube’} или вызываемый объект, по умолчанию=’logcosh’
Функциональная форма функции G, используемая в приближении к негативной энтропии. Может быть либо 'logcosh', 'exp', либо 'cube'. Вы также можете предоставить свою собственную функцию. Она должна возвращать кортеж, содержащий значение функции и её производной в точке. Производная должна быть усреднена по её последнему измерению. Пример:
def my_g(x): return x ** 3, (3 * x ** 2).mean(axis=-1)
- fun_argsdict, по умолчанию=None
Аргументы для передачи в функциональную форму. Если пусто или None и если fun='logcosh', fun_args примет значение {'alpha' : 1.0}.
- max_iterint, default=200
Максимальное количество итераций во время обучения.
- tolfloat, по умолчанию=1e-4
Положительная скалярная величина, задающая допуск, при котором несмешивающая матрица считается сошедшейся.
- w_initarray-like формы (n_components, n_components), по умолчанию=None
Начальный массив для разделения смеси. Если
w_init=None, тогда используется массив значений, взятых из нормального распределения.- whiten_solver{“eigh”, “svd”}, по умолчанию=”svd”
Решатель для отбеливания.
“svd” является более стабильным численно, если задача вырождена, и часто быстрее, когда
n_samples <= n_features.“eigh” обычно более эффективен по памяти, когда
n_samples >= n_features, и может быть быстрее, когдаn_samples >= 50 * n_features.
Добавлено в версии 1.2.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Используется для инициализации
w_initкогда не указано, с нормальным распределением. Передайте int для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Линейный оператор для применения к данным для получения независимых источников. Это равно матрице разделения, когда
whitenравно False, и соответствуетnp.dot(unmixing_matrix, self.whitening_)когдаwhitenравно True.- mixing_ndarray формы (n_features, n_components)
Псевдообратная матрица для
components_. Это линейный оператор, который отображает независимые источники в данные.- mean_ndarray формы (n_features,)
Среднее по признакам. Устанавливается только если
self.whitenравно True.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Если алгоритм — «дефляция», n_iter — максимальное количество итераций, выполняемых по всем компонентам. В противном случае это просто количество итераций, необходимых для сходимости.
- whitening_ndarray формы (n_components, n_features)
Устанавливается только если whiten имеет значение 'True'. Это матрица предварительного отбеливания, которая проецирует данные на первые
n_componentsглавные компоненты.
Смотрите также
PCAМетод главных компонент (PCA).
IncrementalPCAИнкрементальный анализ главных компонент (IPCA).
KernelPCAАнализ главных компонент с ядром (KPCA).
MiniBatchSparsePCAМини-пакетный разреженный анализ главных компонент.
SparsePCAРазреженный анализ главных компонент (SparsePCA).
Ссылки
[1]A. Hyvarinen and E. Oja, Independent Component Analysis: Algorithms and Applications, Neural Networks, 13(4-5), 2000, pp. 411-430.
Примеры
>>> from sklearn.datasets import load_digits >>> from sklearn.decomposition import FastICA >>> X, _ = load_digits(return_X_y=True) >>> transformer = FastICA(n_components=7, ... random_state=0, ... whiten='unit-variance') >>> X_transformed = transformer.fit_transform(X) >>> X_transformed.shape (1797, 7)
- fit(X, y=None)[источник]#
Обучить модель на X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None)[источник]#
Обучить модель и восстановить источники из X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Оцененные источники, полученные путем преобразования данных с помощью оцененной матрицы разделения.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X, copy=True)[источник]#
Преобразовать источники обратно в смешанные данные (применить матрицу смешивания).
- Параметры:
- Xarray-like формы (n_samples, n_components)
Источники, где
n_samplesэто количество образцов иn_componentsэто количество компонентов.- copybool, по умолчанию=True
Если False, данные, переданные в fit, перезаписываются. По умолчанию True.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Восстановленные данные, полученные с помощью матрицы смешивания.
- set_inverse_transform_request(*, copy: bool | None | str = '$UNCHANGED$') FastICA[источник]#
Настроить, следует ли запрашивать передачу метаданных в
inverse_transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяinverse_transformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вinverse_transform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вinverse_transform.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') FastICA[источник]#
Настроить, следует ли запрашивать передачу метаданных в
transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяtransformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вtransform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вtransform.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X, copy=True)[источник]#
Восстановить источники из X (применить матрицу разделения).
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для преобразования, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- copybool, по умолчанию=True
Если False, данные, переданные в fit, могут быть перезаписаны. По умолчанию True.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Оцененные источники, полученные путем преобразования данных с помощью оцененной матрицы разделения.
Примеры галереи#

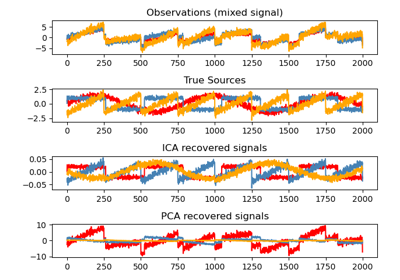
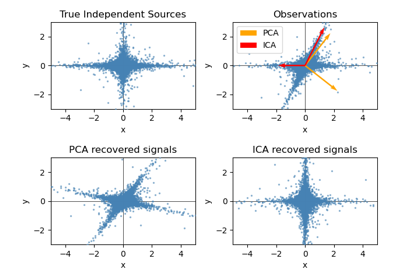
Разделение слепых источников с использованием FastICA