RobustScaler#
- класс sklearn.preprocessing.RobustScaler(*, with_centering=True, with_scaling=True, quantile_range=(25.0, 75.0), copy=True, unit_variance=False)[источник]#
Масштабирование признаков с использованием статистики, устойчивой к выбросам.
Этот масштабатор удаляет медиану и масштабирует данные в соответствии с диапазоном квантилей (по умолчанию IQR: межквартильный размах). IQR — это диапазон между 1-м квартилем (25-й квантиль) и 3-м квартилем (75-й квантиль).
Центрирование и масштабирование происходят независимо для каждого признака путем вычисления соответствующих статистик на выборках в обучающем наборе. Медиана и межквартильный размах затем сохраняются для использования на последующих данных с помощью
transformметод.Стандартизация набора данных — это распространенная предобработка для многих оценщиков машинного обучения. Обычно это делается путем удаления среднего значения и масштабирования до единичной дисперсии. Однако выбросы часто могут негативно влиять на выборочное среднее / дисперсию. В таких случаях использование медианы и межквартильного размаха часто дает лучшие результаты. Для визуализации примера и сравнения с другими масштабаторами обратитесь к Сравните RobustScaler с другими масштабаторами.
Добавлено в версии 0.17.
Подробнее в Руководство пользователя.
- Параметры:
- with_centeringbool, по умолчанию=True
Если
True, центрировать данные перед масштабированием. Это вызоветtransformвызывать исключение при попытке применения к разреженным матрицам, потому что их центрирование влечет построение плотной матрицы, которая в типичных случаях использования, вероятно, будет слишком большой для размещения в памяти.- with_scalingbool, по умолчанию=True
Если
True, масштабировать данные до межквартильного размаха.- quantile_rangeкортеж (q_min, q_max), 0.0 < q_min < q_max < 100.0, default=(25.0, 75.0)
Квантильный диапазон, используемый для расчета
scale_. По умолчанию это равно IQR, т.е.q_min— это первый квартиль иq_maxявляется третьим квартилем.Добавлено в версии 0.18.
- copybool, по умолчанию=True
Если
False, попробуйте избежать копирования и выполнить масштабирование на месте. Это не гарантирует всегда работу на месте; например, если данные не являются массивом NumPy или разреженной матрицей CSR scipy, копия всё равно может быть возвращена.- unit_variancebool, по умолчанию=False
Если
True, масштабируйте данные так, чтобы нормально распределенные признаки имели дисперсию 1. В общем случае, если разница между x-значениямиq_maxиq_minдля стандартного нормального распределения больше 1, набор данных будет масштабирован вниз. Если меньше 1, набор данных будет масштабирован вверх.Добавлено в версии 0.24.
- Атрибуты:
- center_массив чисел с плавающей точкой
Медианное значение для каждого признака в обучающем наборе.
- scale_массив чисел с плавающей точкой
(Масштабированный) межквартильный размах для каждого признака в обучающем наборе.
Добавлено в версии 0.17: scale_ атрибут.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
robust_scaleкоммуникация вокруг scikit-learn
sklearn.decomposition.PCAДополнительно удаляет линейную корреляцию между признаками с 'whiten=True'.
Примечания
https://en.wikipedia.org/wiki/Median https://en.wikipedia.org/wiki/Interquartile_range
Примеры
>>> from sklearn.preprocessing import RobustScaler >>> X = [[ 1., -2., 2.], ... [ -2., 1., 3.], ... [ 4., 1., -2.]] >>> transformer = RobustScaler().fit(X) >>> transformer RobustScaler() >>> transformer.transform(X) array([[ 0. , -2. , 0. ], [-1. , 0. , 0.4], [ 1. , 0. , -1.6]])
- fit(X, y=None)[источник]#
Вычислить медиану и квантили для использования при масштабировании.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для вычисления медианы и квантилей, применяемых для последующего масштабирования по осям признаков.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученный масштабатор.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
То же, что и входные признаки.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Масштабировать данные обратно к исходному представлению.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Масштабированные данные, которые нужно преобразовать обратно.
- Возвращает:
- X_original{ndarray, разреженная матрица} формы (n_samples, n_features)
Преобразованный массив.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Центрировать и масштабировать данные.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для масштабирования по указанной оси.
- Возвращает:
- X_tr{ndarray, разреженная матрица} формы (n_samples, n_features)
Преобразованный массив.
Примеры галереи#
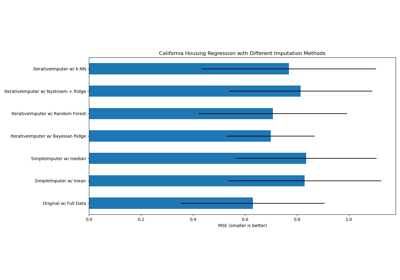
Заполнение пропущенных значений с вариантами IterativeImputer
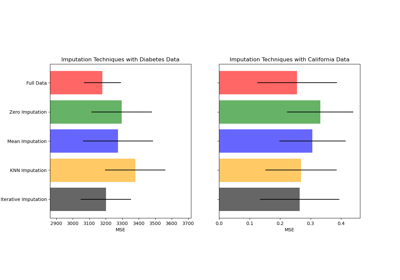
Заполнение пропущенных значений перед построением оценщика
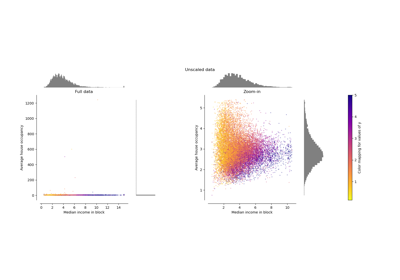
Сравнение влияния различных масштабировщиков на данные с выбросами