load_diabetes#
- sklearn.datasets.load_diabetes(*, return_X_y=False, as_frame=False, масштабированный=True)[источник]#
Загружает и возвращает набор данных по диабету (регрессия).
Всего образцов
442
Снижение размерности
10
Признаки
действительное, -.2 < x < .2
Целевые переменные
целое число 25 - 346
Примечание
Значение каждого признака (т.е.
feature_names) может быть неясным (особенно дляltg) так как документация исходного набора данных не является явной. Мы предоставляем информацию, которая кажется правильной в соответствии с научной литературой в этой области исследований.Подробнее в Руководство пользователя.
- Параметры:
- return_X_ybool, по умолчанию=False
Если True, возвращает
(data, target)вместо объекта Bunch. См. ниже для получения дополнительной информации оdataиtargetобъект.Добавлено в версии 0.18.
- as_framebool, по умолчанию=False
Если True, данные представляют собой pandas DataFrame, включающий столбцы с соответствующими типами данных (числовые). Цель — pandas DataFrame или Series в зависимости от количества целевых столбцов. Если
return_X_yравно True, тогда (data,target) будут pandas DataFrame или Series, как описано ниже.Добавлено в версии 0.23.
- масштабированныйbool, по умолчанию=True
Если True, переменные признаков центрируются по среднему значению и масштабируются на стандартное отклонение, умноженное на квадратный корень из
n_samples. Если False, возвращаются исходные данные для переменных признаков.Добавлено в версии 1.1.
- Возвращает:
- данные
Bunch Объект, подобный словарю, со следующими атрибутами.
- данные{ndarray, dataframe} формы (442, 10)
Матрица данных. Если
as_frame=True,dataбудет pandas DataFrame.- target: {ndarray, Series} формы (442,)
Целевая переменная регрессии. Если
as_frame=True,targetбудет pandas Series.- feature_names: list
Имена столбцов набора данных.
- фрейм: DataFrame формы (442, 11)
Только присутствует, когда
as_frame=TrueМы определяем функцию для загрузки данных изdataиtarget.Добавлено в версии 0.23.
- DESCR: str
Полное описание набора данных.
- data_filename: str
Путь к местоположению данных.
- target_filename: str
Путь к местоположению цели.
- (data, target)кортеж если
return_X_yравно True Возвращает кортеж из двух ndarray формы (n_samples, n_features) Двумерный массив, где каждая строка представляет один образец, а каждый столбец представляет признаки и/или цель данного образца.
Добавлено в версии 0.18.
- данные
Примеры
>>> from sklearn.datasets import load_diabetes >>> diabetes = load_diabetes() >>> diabetes.target[:3] array([151., 75., 141.]) >>> diabetes.data.shape (442, 10)
Примеры галереи#


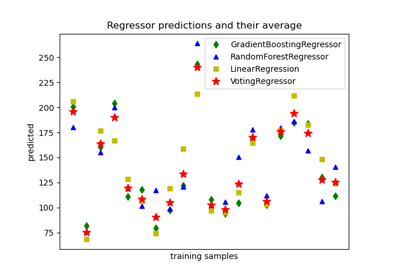
Построить индивидуальные и голосующие регрессионные предсказания
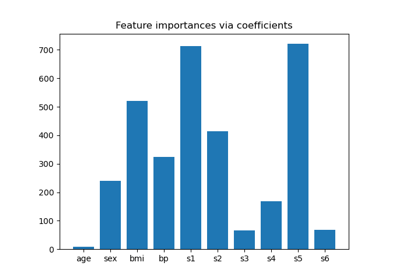
Основанный на модели и последовательный отбор признаков
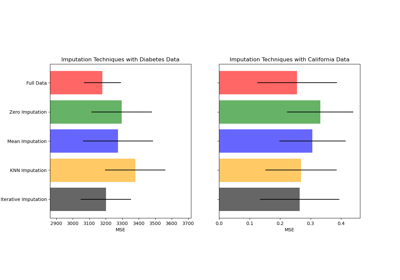
Заполнение пропущенных значений перед построением оценщика
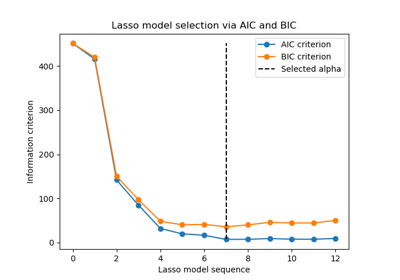
Выбор модели Lasso с помощью информационных критериев
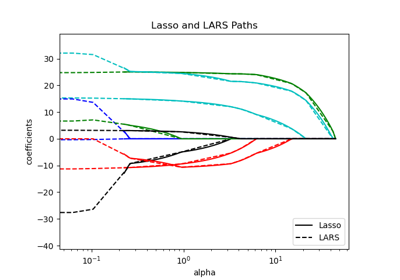
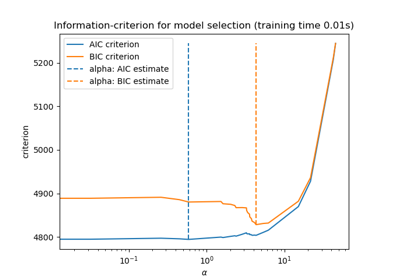
Выбор модели Lasso: AIC-BIC / перекрёстная проверка

Расширенное построение графиков с частичной зависимостью