fetch_openml#
- sklearn.datasets.fetch_openml(имя: str | None = None, *, версия: str | int = 'active', data_id: int | None = None, data_home: str | PathLike | None = None, target_column: str | Список | None = 'default-target', cache: bool = True, return_X_y: bool = False, as_frame: str | bool = 'auto', n_retries: int = 3, задержка: float = 1.0, parser: str = 'auto', read_csv_kwargs: Dict | None = None)[источник]#
Загрузите набор данных из openml по имени или идентификатору набора данных.
Наборы данных однозначно идентифицируются либо целочисленным ID, либо комбинацией имени и версии (т.е. может быть несколько версий набора данных 'iris'). Пожалуйста, укажите либо имя, либо data_id (не оба). Если указано имя, также может быть предоставлена версия.
Подробнее в Руководство пользователя.
Добавлено в версии 0.20.
Примечание
ЭКСПЕРИМЕНТАЛЬНЫЙ
API является экспериментальным (особенно структура возвращаемого значения) и может подвергаться небольшим обратно несовместимым изменениям без предупреждения в будущих выпусках.
- Параметры:
- имяstr, default=None
Строковый идентификатор набора данных. Обратите внимание, что OpenML может иметь несколько наборов данных с одинаковым именем.
- версияint или 'active', по умолчанию='active'
Версия набора данных. Может быть предоставлена только если также
nameзадано. Если установлено значение 'active', используется самая старая версия, которая все еще активна. Поскольку может существовать более одной активной версии набора данных, и эти версии могут принципиально отличаться друг от друга, настоятельно рекомендуется задавать точную версию.- data_idint, default=None
OpenML ID набора данных. Наиболее конкретный способ получения набора данных. Если data_id не задан, имя (и потенциальная версия) используются для получения набора данных.
- data_homestr или path-like, по умолчанию=None
Укажите другую папку для загрузки и кэширования наборов данных. По умолчанию все данные scikit-learn хранятся в подпапках '~/scikit_learn_data'.
- target_columnstr, list или None, default='default-target'
Укажите имя столбца в данных, который следует использовать в качестве целевой переменной. Если 'default-target', используется стандартный целевой столбец, хранящийся на сервере. Если
None, все столбцы возвращаются как данные, а целевая переменная —None. Если список (строк), все столбцы с этими именами возвращаются как multi-target (Примечание: не все классификаторы scikit-learn могут обрабатывать все типы multi-output комбинаций).- cachebool, по умолчанию=True
Кэшировать ли загруженные наборы данных в
data_home.- return_X_ybool, по умолчанию=False
Если True, возвращает
(data, target)вместо объекта Bunch. См. ниже для получения дополнительной информации оdataиtargetобъекты.- as_framebool или 'auto', по умолчанию='auto'
Если True, данные представляют собой pandas DataFrame, включающий столбцы с соответствующими типами данных (числовые, строковые или категориальные). Цель - pandas DataFrame или Series в зависимости от количества target_columns. Bunch будет содержать
frameатрибут с целью и данными. Еслиreturn_X_yравно True, тогда(data, target)будут pandas DataFrame или Series, как описано выше.Если
as_frameравно ‘auto’, данные и целевая переменная будут преобразованы в DataFrame или Series, как если быas_frameустановлено в True, если набор данных не хранится в разреженном формате.Если
as_frameравно False, данные и целевые значения будут массивами NumPy иdataбудет содержать только числовые значения, когдаparser="liac-arff"где категории предоставлены в атрибутеcategoriesизBunchэкземпляром. Когдаparser="pandas", порядковое кодирование не выполняется.Изменено в версии 0.24: Значение по умолчанию для
as_frameизменено сFalseto'auto'в 0.24.- n_retriesint, по умолчанию=3
Количество повторных попыток при возникновении HTTP-ошибок или таймаутов сети. Ошибки с кодом состояния 412 не будут повторяться, так как они представляют общие ошибки OpenML.
- задержкаfloat, по умолчанию=1.0
Количество секунд между повторными попытками.
- parser{“auto”, “pandas”, “liac-arff”}, по умолчанию=”auto”
Парсер, используемый для загрузки файла ARFF. Реализованы два парсера:
"pandas": это самый эффективный парсер. Однако он требует установки pandas и может открывать только плотные наборы данных."liac-arff": это чистый парсер ARFF на Python, который гораздо менее эффективен по памяти и процессору. Он работает с разреженными наборами данных ARFF.
Если
"auto", парсер выбирается автоматически таким образом, что"liac-arff"выбирается для разреженных ARFF-наборов данных, в противном случае"pandas"выбран.Добавлено в версии 1.2.
Изменено в версии 1.4: Значение по умолчанию для
parserизменения с"liac-arff"to"auto".- read_csv_kwargsdict, по умолчанию=None
Аргументы ключевых слов, передаваемые в
pandas.read_csvпри загрузке данных из файла ARFF и использовании парсера pandas. Это может позволить переопределить некоторые параметры по умолчанию.Добавлено в версии 1.3.
- Возвращает:
- данные
Bunch Объект, подобный словарю, со следующими атрибутами.
- данныеnp.array, scipy.sparse.csr_matrix из чисел с плавающей точкой или pandas DataFrame
Матрица признаков. Категориальные признаки кодируются как порядковые.
- цельnp.array, pandas Series или DataFrame
Целевая переменная регрессии или метки классификации, если применимо. Тип данных — float, если числовой, и object, если категориальный. Если
as_frameравно True,targetявляется объектом pandas.- DESCRstr
Полное описание набора данных.
- feature_nameslist
Имена столбцов набора данных.
- target_names: список
Имена целевых столбцов.
Добавлено в версии 0.22.
- категорииdict или None
Сопоставляет каждое имя категориального признака со списком значений, так что значение, закодированное как i, является i-м в списке. Если
as_frameравно True, это None.- подробностиdict
Больше метаданных из OpenML.
- фреймpandas DataFrame
Только присутствует, когда
as_frame=TrueМы определяем функцию для загрузки данных изdataиtarget.
- (data, target)кортеж если
return_X_yравно True Примечание
ЭКСПЕРИМЕНТАЛЬНЫЙ
Этот интерфейс экспериментальный и последующие релизы могут изменять атрибуты без предупреждения (хотя изменения должны быть только незначительными в
dataиtarget).Пропущенные значения в 'data' представлены как NaN. Пропущенные значения в 'target' представлены как NaN (числовая цель) или None (категориальная цель).
- данные
Примечания
The
"pandas"и"liac-arff"парсеры могут приводить к разным типам данных на выходе. Основные различия следующие:The
"liac-arff"парсер всегда кодирует категориальные признаки какstrобъектов. В отличие от этого,"pandas"парсер вместо этого выводит тип во время чтения, и числовые категории будут приведены к целым числам, когда это возможно.The
"liac-arff"парсер использует float64 для кодирования числовых признаков, помеченных как ‘REAL’ и ‘NUMERICAL’ в метаданных."pandas"парсер вместо этого определяет, соответствуют ли эти числовые признаки целым числам, и использует расширенный тип данных Integer от pandas.В частности, классификационные наборы данных с целочисленными категориями обычно загружаются как таковые
(0, 1, ...)с"pandas"парсер, пока"liac-arff"принудительно использует строковые метки классов, такие как"0","1"и так далее.The
"pandas"парсер не будет удалять одинарные кавычки - т.е.'- из строковых столбцов. Например, строка'my string'будет сохранен как есть, в то время как"liac-arff"парсер удалит одинарные кавычки. Для категориальных столбцов одинарные кавычки удаляются из значений.
Кроме того, когда
as_frame=Falseиспользуется,"liac-arff"парсер возвращает порядково закодированные данные, где категории предоставляются в атрибутеcategoriesизBunchэкземпляр. Вместо этого,"pandas"возвращает массив NumPy, где категории не закодированы.Примеры
>>> from sklearn.datasets import fetch_openml >>> adult = fetch_openml("adult", version=2) >>> adult.frame.info()
RangeIndex: 48842 entries, 0 to 48841 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 48842 non-null int64 1 workclass 46043 non-null category 2 fnlwgt 48842 non-null int64 3 education 48842 non-null category 4 education-num 48842 non-null int64 5 marital-status 48842 non-null category 6 occupation 46033 non-null category 7 relationship 48842 non-null category 8 race 48842 non-null category 9 sex 48842 non-null category 10 capital-gain 48842 non-null int64 11 capital-loss 48842 non-null int64 12 hours-per-week 48842 non-null int64 13 native-country 47985 non-null category 14 class 48842 non-null category dtypes: category(9), int64(6) memory usage: 2.7 MB
Примеры галереи#


Удаление шума с изображения с использованием ядерного PCA
Эффект преобразования целей в регрессионной модели
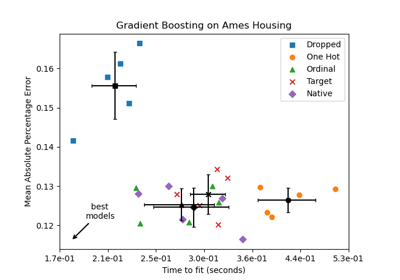
Поддержка категориальных признаков в градиентном бустинге
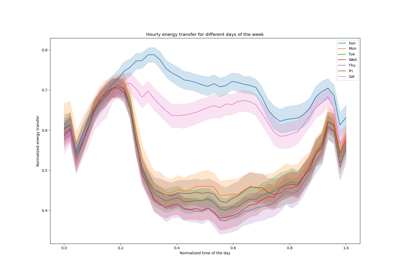
Признаки в деревьях с градиентным бустингом на гистограммах

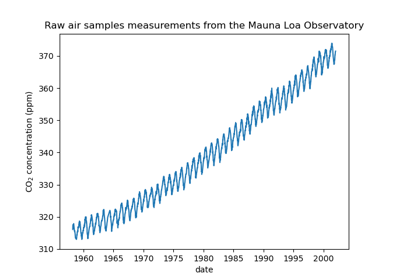
Прогнозирование уровня CO2 на наборе данных Mona Loa с использованием гауссовской регрессии (GPR)

Распространённые ошибки в интерпретации коэффициентов линейных моделей
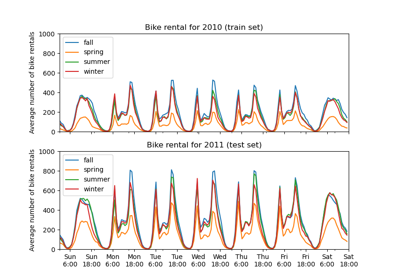
Графики частичной зависимости и индивидуального условного ожидания
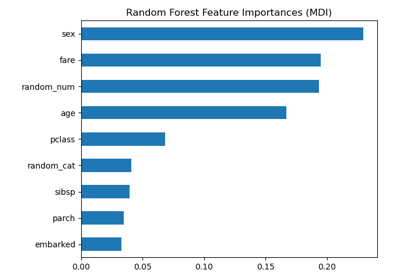
Важность перестановок против важности признаков случайного леса (MDI)
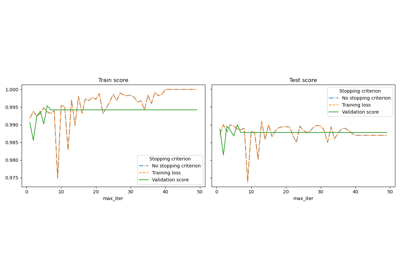
Ранняя остановка стохастического градиентного спуска
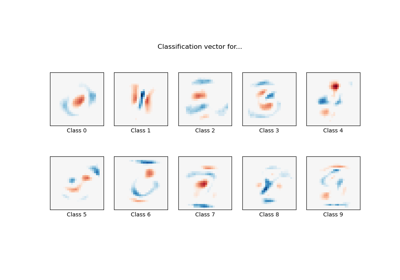
Классификация MNIST с использованием мультиномиальной логистической регрессии + L1

Последующая настройка порога принятия решений для обучения с учетом стоимости
Пост-фактумная настройка точки отсечения функции принятия решений
Многометочная классификация с использованием цепочки классификаторов