SpectralEmbedding#
- класс sklearn.manifold.SpectralEmbedding(n_components=2, *, affinity='nearest_neighbors', gamma=None, random_state=None, eigen_solver=None, eigen_tol='auto', n_neighbors=None, n_jobs=None)[источник]#
Спектральное вложение для нелинейного уменьшения размерности.
Формирует матрицу сходства, заданную указанной функцией, и применяет спектральное разложение к соответствующему лапласиану графа. Полученное преобразование задается значениями собственных векторов для каждой точки данных.
Примечание: Laplacian Eigenmaps — это фактический алгоритм, реализованный здесь.
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, по умолчанию=2
Размерность проецируемого подпространства.
- affinity{'nearest_neighbors', 'rbf', 'precomputed', 'precomputed_nearest_neighbors'} или callable, default='nearest_neighbors'
- Как построить матрицу сходства.
'nearest_neighbors' : построить матрицу сходства, вычисляя граф ближайших соседей.
'rbf' : построить матрицу сходства, вычисляя радиально-базисную функцию (RBF) ядра.
‘precomputed’ : интерпретировать
Xв качестве предвычисленной матрицы сходства.'precomputed_nearest_neighbors' : интерпретировать
Xв виде разреженного графа предвычисленных ближайших соседей и строит матрицу сходства, выбираяn_neighborsближайшие соседи.callable : использовать переданную функцию как сходство функция принимает матрицу данных (n_samples, n_features) и возвращает матрицу сходства (n_samples, n_samples).
- gammafloat, по умолчанию=None
Коэффициент ядра для ядра rbf. Если None, gamma будет установлен в 1/n_features.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Псевдослучайный генератор чисел, используемый для инициализации разложения собственных векторов lobpcg, когда
eigen_solver == 'amg', и для инициализации K-Means. Используйте целое число, чтобы результаты были детерминированными между вызовами (см. Глоссарий).Примечание
При использовании
eigen_solver == 'amg', необходимо также зафиксировать глобальное начальное значение numpy с помощьюnp.random.seed(int)для получения детерминированных результатов. См. pyamg/pyamg#139 для дополнительной информации.- eigen_solver{‘arpack’, ‘lobpcg’, ‘amg’}, default=None
Стратегия разложения по собственным значениям для использования. AMG требует установки pyamg. Может работать быстрее на очень больших разреженных задачах. Если None, то
'arpack'используется.- eigen_tolfloat, по умолчанию="auto"
Критерий остановки для собственного разложения матрицы Лапласа. Если
eigen_tol="auto"тогда переданный допуск будет зависеть отeigen_solver:Если
eigen_solver="arpack", затемeigen_tol=0.0;Если
eigen_solver="lobpcg"илиeigen_solver="amg", затемeigen_tol=Noneкоторый настраивает базовыйlobpcgрешатель для автоматического разрешения значения согласно их эвристикам. Смотрите,scipy.sparse.linalg.lobpcgподробности.
Обратите внимание, что при использовании
eigen_solver="lobpcg"илиeigen_solver="amg"значенияtol<1e-5может привести к проблемам сходимости и должен быть избегаем.Добавлено в версии 1.2.
- n_neighborsint, default=None
Количество ближайших соседей для построения графа ближайших соседей. Если None, n_neighbors будет установлено в max(n_samples/10, 1).
- n_jobsint, default=None
Количество параллельных задач для выполнения.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- embedding_ndarray формы (n_samples, n_components)
Спектральное вложение обучающей матрицы.
- affinity_matrix_ndarray формы (n_samples, n_samples)
Матрица сходства, построенная из выборок или предварительно вычисленная.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_neighbors_int
Количество ближайших соседей, фактически используемых.
Смотрите также
IsomapНелинейное снижение размерности через изометрическое отображение.
Ссылки
Учебное пособие по спектральной кластеризации, 2007 Ulrike von Luxburg
О спектральной кластеризации: анализ и алгоритм, 2001 Andrew Y. Ng, Michael I. Jordan, Yair Weiss
Нормализованные разрезы и сегментация изображений, 2000 Jianbo Shi, Jitendra Malik
Примеры
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import SpectralEmbedding >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = SpectralEmbedding(n_components=2) >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
- fit(X, y=None)[источник]#
Обучить модель на данных из X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.Если affinity равен "precomputed", X: {array-like, sparse matrix}, форма (n_samples, n_samples), интерпретировать X как предвычисленный граф смежности, вычисленный из выборок.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None)[источник]#
Обучить модель на данных X и преобразовать X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.Если affinity — "precomputed" X: {array-like, sparse matrix} формы (n_samples, n_samples), интерпретировать X как предвычисленный граф смежности, вычисленный из образцов.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- X_newarray-like формы (n_samples, n_components)
Спектральное вложение обучающей матрицы.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
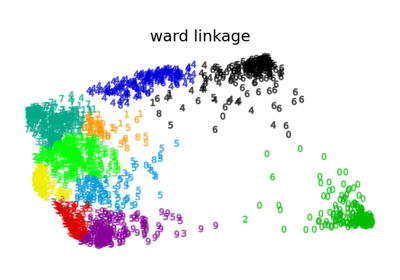
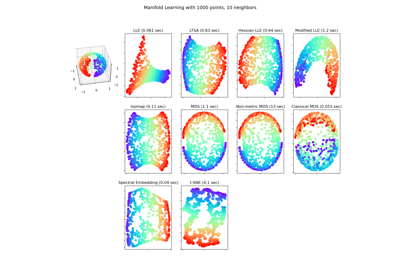
Различные агломеративные кластеризации на 2D-вложении цифр

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…