homogeneity_score#
- sklearn.metrics.homogeneity_score(labels_true, labels_pred)[источник]#
Метрика однородности кластерной разметки при заданной истинной разметке.
Результат кластеризации удовлетворяет однородности, если все его кластеры содержат только точки данных, которые являются членами одного класса.
Эта метрика не зависит от абсолютных значений меток: перестановка значений меток классов или кластеров не изменит значение оценки никаким образом.
Эта метрика не симметрична: переключение
label_trueсlabel_predвернетcompleteness_scoreкоторые в общем случае будут разными.Подробнее в Руководство пользователя.
- Параметры:
- labels_truearray-like формы (n_samples,)
Истинные метки классов, используемые в качестве эталона.
- labels_predarray-like формы (n_samples,)
Метки кластеров для оценки.
- Возвращает:
- гомогенностьfloat
Оценка от 0.0 до 1.0. 1.0 означает идеально однородную маркировку.
Смотрите также
completeness_scoreМетрика полноты маркировки кластеров.
v_measure_scoreV-мера (NMI с опцией среднего арифметического).
Ссылки
Примеры
Идеальные разметки однородны:
>>> from sklearn.metrics.cluster import homogeneity_score >>> homogeneity_score([0, 0, 1, 1], [1, 1, 0, 0]) 1.0
Неидеальные разметки, которые дополнительно разделяют классы на большее количество кластеров, могут быть идеально однородными:
>>> print("%.6f" % homogeneity_score([0, 0, 1, 1], [0, 0, 1, 2])) 1.000000 >>> print("%.6f" % homogeneity_score([0, 0, 1, 1], [0, 1, 2, 3])) 1.000000
Кластеры, включающие выборки из разных классов, не обеспечивают однородной маркировки:
>>> print("%.6f" % homogeneity_score([0, 0, 1, 1], [0, 1, 0, 1])) 0.0... >>> print("%.6f" % homogeneity_score([0, 0, 1, 1], [0, 0, 0, 0])) 0.0...
Примеры галереи#
Демонстрация алгоритма кластеризации с распространением аффинности
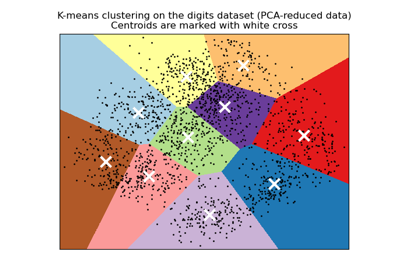
Демонстрация кластеризации K-Means на данных рукописных цифр
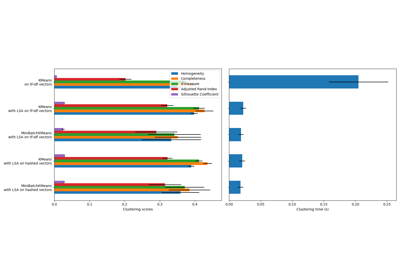
Кластеризация текстовых документов с использованием k-means