BayesianRidge#
- класс sklearn.linear_model.BayesianRidge(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, copy_X=True, verbose=False)[источник]#
Байесовская гребневая регрессия.
Обучает байесовскую гребневую модель. Подробности об этой реализации и оптимизации параметров регуляризации лямбда (точность весов) и альфа (точность шума) см. в разделе Notes.
Подробнее в Руководство пользователя. Для интуитивной визуализации того, как синусоида аппроксимируется полиномом с использованием различных пар начальных значений, см. Аппроксимация кривой с использованием байесовской гребневой регрессии.
- Параметры:
- max_iterint, по умолчанию=300
Максимальное количество итераций по полному набору данных перед остановкой независимо от любых критериев ранней остановки.
Изменено в версии 1.3.
- tolfloat, по умолчанию=1e-3
Остановить алгоритм, если w сошелся.
- alpha_1float, по умолчанию=1e-6
Гиперпараметр: параметр формы для априорного распределения Гамма над параметром альфа.
- alpha_2float, по умолчанию=1e-6
Гиперпараметр: обратный параметр масштаба (параметр скорости) для гамма-распределения априорного значения параметра alpha.
- lambda_1float, по умолчанию=1e-6
Гиперпараметр : параметр формы для гамма-распределения априори над параметром lambda.
- lambda_2float, по умолчанию=1e-6
Гиперпараметр: параметр обратного масштаба (параметр скорости) для Гамма-распределения априорного над параметром lambda.
- alpha_initfloat, по умолчанию=None
Начальное значение для alpha (точность шума). Если не задано, alpha_init равно 1/Var(y).
Добавлено в версии 0.22.
- lambda_initfloat, по умолчанию=None
Начальное значение для лямбды (точность весов). Если не задано, lambda_init равно 1.
Добавлено в версии 0.22.
- compute_scorebool, по умолчанию=False
Если True, вычисляет логарифм маргинального правдоподобия на каждой итерации оптимизации.
- fit_interceptbool, по умолчанию=True
Определять ли свободный член для этой модели. Свободный член не рассматривается как вероятностный параметр и поэтому не имеет связанной дисперсии. Если установлено в False, свободный член не будет использоваться в вычислениях (т.е. ожидается, что данные центрированы).
- copy_Xbool, по умолчанию=True
Если True, X будет скопирован; иначе, он может быть перезаписан.
- verbosebool, по умолчанию=False
Режим подробного вывода при обучении модели.
- Атрибуты:
- coef_массивоподобный формы (n_features,)
Коэффициенты регрессионной модели (среднее распределения)
- intercept_float
Независимый член в функции решения. Установлен в 0.0, если
fit_intercept = False.- alpha_float
Оцененная точность шума.
- lambda_float
Оцененная точность весов.
- sigma_array-like формы (n_features, n_features)
Оценочная матрица дисперсии-ковариации весов
- scores_массивоподобный формы (n_iter_+1,)
Если computed_score равно True, значение логарифма маргинального правдоподобия (которое нужно максимизировать) на каждой итерации оптимизации. Массив начинается со значения логарифма маргинального правдоподобия, полученного для начальных значений alpha и lambda, и заканчивается значением, полученным для оценённых alpha и lambda.
- n_iter_int
Фактическое количество итераций для достижения критерия остановки.
- X_offset_ndarray формы (n_features,)
Если
fit_intercept=True, смещение, вычитаемое для центрирования данных к нулевому среднему. В противном случае устанавливается в np.zeros(n_features).- X_scale_ndarray формы (n_features,)
Установить в np.ones(n_features).
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
ARDRegressionБайесовская ARD-регрессия.
Примечания
Существует несколько стратегий выполнения байесовской гребневой регрессии. Эта реализация основана на алгоритме, описанном в Приложении A (Tipping, 2001), где обновления параметров регуляризации выполняются, как предложено в (MacKay, 1992). Обратите внимание, что согласно A New View of Automatic Relevance Determination (Wipf and Nagarajan, 2008) эти правила обновления не гарантируют, что маргинальное правдоподобие увеличивается между двумя последовательными итерациями оптимизации.
Ссылки
D. J. C. MacKay, Bayesian Interpolation, Computation and Neural Systems, Vol. 4, No. 3, 1992.
M. E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, Journal of Machine Learning Research, Vol. 1, 2001.
Примеры
>>> from sklearn import linear_model >>> clf = linear_model.BayesianRidge() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) BayesianRidge() >>> clf.predict([[1, 1]]) array([1.])
- fit(X, y, sample_weight=None)[источник]#
Обучите модель.
- Параметры:
- Xndarray формы (n_samples, n_features)
Обучающие данные.
- yndarray формы (n_samples,)
Целевые значения. Будут приведены к типу данных X при необходимости.
- sample_weightndarray формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждого образца.
Добавлено в версии 0.20: параметр sample_weight поддержку для BayesianRidge.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X, return_std=False)[источник]#
Прогнозирование с использованием линейной модели.
В дополнение к среднему прогностического распределения, также может быть возвращено его стандартное отклонение.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образцы.
- return_stdbool, по умолчанию=False
Возвращать ли стандартное отклонение апостериорного предсказания.
- Возвращает:
- y_meanarray-like формы (n_samples,)
Среднее апостериорного распределения для запрашиваемых точек.
- y_stdarray-like формы (n_samples,)
Стандартное отклонение прогностического распределения точек запроса.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') BayesianRidge[источник]#
Настроить, следует ли запрашивать передачу метаданных в
predictметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpredictесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpredict.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- return_stdstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
return_stdпараметр вpredict.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

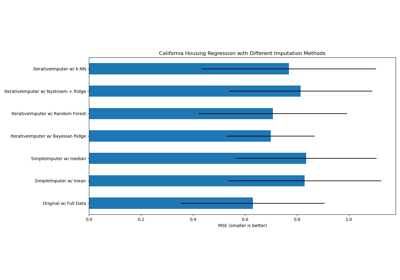
Заполнение пропущенных значений с вариантами IterativeImputer
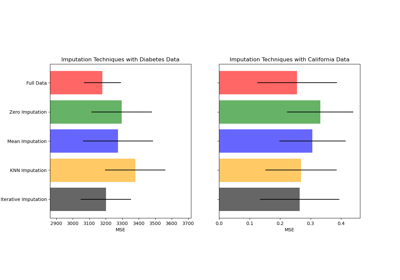
Заполнение пропущенных значений перед построением оценщика
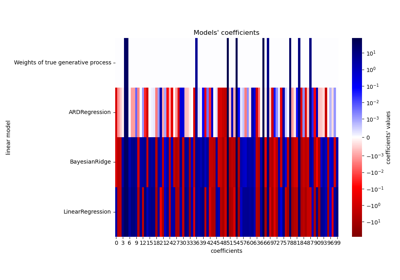
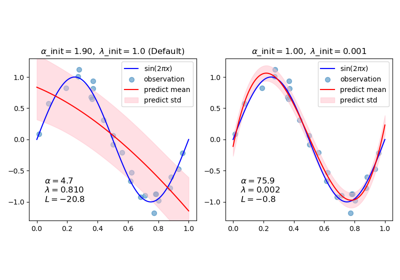
Аппроксимация кривой с использованием байесовской гребневой регрессии