Birch#
- класс sklearn.cluster.Birch(*, порог=0.5, branching_factor=50, n_clusters=3, compute_labels=True)[источник]#
Реализует алгоритм кластеризации BIRCH.
Это эффективный по памяти алгоритм онлайн-обучения, предоставляемый как альтернатива
MiniBatchKMeans. Он строит древовидную структуру данных, где центроиды кластеров считываются с листьев. Они могут быть либо конечными центроидами кластеров, либо могут быть предоставлены как входные данные для другого алгоритма кластеризации, такого какAgglomerativeClustering.Подробнее в Руководство пользователя.
Добавлено в версии 0.16.
- Параметры:
- порогfloat, по умолчанию=0.5
Радиус подкластера, полученного путем объединения нового образца и ближайшего подкластера, должен быть меньше порога. В противном случае создается новый подкластер. Установка очень низкого значения способствует разделению и наоборот.
- branching_factorint, по умолчанию=50
Максимальное количество CF подкластеров в каждом узле. Если новый образец входит так, что количество подкластеров превышает branching_factor, то этот узел разделяется на два узла с перераспределением подкластеров в каждом. Родительский подкластер этого узла удаляется, и два новых подкластера добавляются как родители двух разделенных узлов.
- n_clustersint, экземпляр модели sklearn.cluster или None, по умолчанию=3
Количество кластеров после финального шага кластеризации, который рассматривает подкластеры из листьев как новые образцы.
None: финальный шаг кластеризации не выполняется, и подкластеры возвращаются как есть.sklearn.clusterEstimator: если предоставлена модель, модель обучается, рассматривая подкластеры как новые образцы, а исходные данные отображаются на метку ближайшего подкластера.int: модель обученаAgglomerativeClusteringсn_clustersустановлен равным целому числу.
- compute_labelsbool, по умолчанию=True
Вычислять ли метки для каждого обучения.
- Атрибуты:
- root__CFNode
Корень CFTree.
- dummy_leaf__CFNode
Начальный указатель на все листья.
- subcluster_centers_ndarray
Центроиды всех подкластеров, считанные непосредственно из листьев.
- subcluster_labels_ndarray
Метки, назначенные центроидам подкластеров после их глобальной кластеризации.
- labels_ndarray формы (n_samples,)
Массив меток, присвоенных входным данным. если используется partial_fit вместо fit, они присваиваются последнему пакету данных.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
MiniBatchKMeansАльтернативная реализация, которая выполняет инкрементальные обновления позиций центров с использованием мини-пакетов.
Примечания
Структура данных дерева состоит из узлов, где каждый узел содержит несколько подкластеров. Максимальное количество подкластеров в узле определяется коэффициентом ветвления. Каждый подкластер хранит линейную сумму, квадратичную сумму и количество образцов в этом подкластере. Кроме того, каждый подкластер также может иметь узел в качестве своего потомка, если подкластер не является членом листового узла.
Для новой точки, входящей в корень, она объединяется с подкластером, ближайшим к ней, и линейная сумма, квадратичная сумма и количество выборок этого подкластера обновляются. Это выполняется рекурсивно до обновления свойств листового узла.
См. Сравнение BIRCH и MiniBatchKMeans для сравнения с
MiniBatchKMeans.Ссылки
Tian Zhang, Raghu Ramakrishnan, Maron Livny BIRCH: An efficient data clustering method for large databases. https://www.cs.sfu.ca/CourseCentral/459/han/papers/zhang96.pdf
Роберто Пердиси JBirch — Java-реализация алгоритма кластеризации BIRCH https://code.google.com/archive/p/jbirch
Примеры
>>> from sklearn.cluster import Birch >>> X = [[0, 1], [0.3, 1], [-0.3, 1], [0, -1], [0.3, -1], [-0.3, -1]] >>> brc = Birch(n_clusters=None) >>> brc.fit(X) Birch(n_clusters=None) >>> brc.predict(X) array([0, 0, 0, 1, 1, 1])
Для сравнения алгоритма кластеризации BIRCH с другими алгоритмами кластеризации, см. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
- fit(X, y=None)[источник]#
Постройте CF-дерево для входных данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- self
Обученный оценщик.
- fit_predict(X, y=None, **kwargs)[источник]#
Выполнить кластеризацию на
Xи возвращает метки кластеров.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **kwargsdict
Аргументы, передаваемые в
fit.Добавлено в версии 1.4.
- Возвращает:
- меткиndarray формы (n_samples,), dtype=np.int64
Метки кластеров.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X=None, y=None)[источник]#
Онлайн-обучение. Предотвращает перестроение CFTree с нуля.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features), default=None
Входные данные. Если X не предоставлен, выполняется только шаг глобальной кластеризации.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- self
Обученный оценщик.
- predict(X)[источник]#
Предсказать данные с помощью
centroids_подкластеров.Избегать вычисления норм строк X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- Возвращает:
- меткиndarray формы (n_samples,)
Размеченные данные.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать X в размерность центроидов подкластеров.
Каждое измерение представляет расстояние от точки образца до каждого центроида кластера.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- Возвращает:
- X_trans{array-like, sparse matrix} формы (n_samples, n_clusters)
Преобразованные данные.
Примеры галереи#
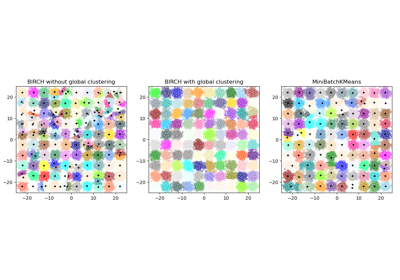
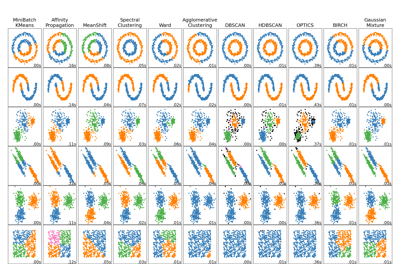
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных