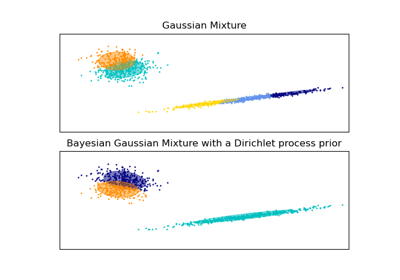
BayesianGaussianMixture#
- класс sklearn.mixture.BayesianGaussianMixture(*, n_components=1, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weight_concentration_prior_type='dirichlet_process', weight_concentration_prior=None, mean_precision_prior=None, mean_prior=None, degrees_of_freedom_prior=None, covariance_prior=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[источник]#
Вариационный байесовский метод оценки гауссовой смеси.
Этот класс позволяет вывести приближенное апостериорное распределение по параметрам распределения гауссовой смеси. Эффективное количество компонентов может быть выведено из данных.
Этот класс реализует два типа априорного распределения для распределения весов: модель конечной смеси с распределением Дирихле и модель бесконечной смеси с процессом Дирихле. На практике алгоритм вывода процесса Дирихле аппроксимируется и использует усеченное распределение с фиксированным максимальным числом компонентов (называемое представлением ломаной палочки). Количество фактически используемых компонентов почти всегда зависит от данных.
Добавлено в версии 0.18.
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, по умолчанию=1
Количество компонент смеси. В зависимости от данных и значения
weight_concentration_priorмодель может решить не использовать все компоненты, установив некоторые компонентыweights_к значениям, очень близким к нулю. Количество эффективных компонентов, следовательно, меньше, чем n_components.- covariance_type{‘full’, ‘tied’, ‘diag’, ‘spherical’}, по умолчанию=’full’
Строка, описывающая тип параметров ковариации для использования. Должна быть одной из:
‘full’ (каждый компонент имеет свою общую ковариационную матрицу),
‘tied’ (все компоненты используют одну и ту же общую ковариационную матрицу),
'diag' (каждый компонент имеет свою собственную диагональную ковариационную матрицу),
‘spherical’ (каждый компонент имеет свою собственную единичную дисперсию).
- tolfloat, по умолчанию=1e-3
Порог сходимости. Итерации EM остановятся, когда средний прирост нижней границы правдоподобия (обучающих данных относительно модели) опустится ниже этого порога.
- reg_covarfloat, по умолчанию=1e-6
Неотрицательная регуляризация, добавленная к диагонали ковариации. Позволяет гарантировать, что ковариационные матрицы являются положительно определенными.
- max_iterint, по умолчанию=100
Количество итераций EM для выполнения.
- n_initint, по умолчанию=1
Количество инициализаций для выполнения. Сохраняется результат с наибольшим нижним пределом значения правдоподобия.
- init_params{‘kmeans’, ‘k-means++’, ‘random’, ‘random_from_data’}, по умолчанию=’kmeans’
Метод, используемый для инициализации весов, средних значений и ковариаций. Строка должна быть одной из:
‘kmeans’: ответственности инициализируются с помощью kmeans.
'k-means++': используйте метод k-means++ для инициализации.
'random': ответственности инициализируются случайным образом.
'random_from_data': начальные средние значения случайно выбираются из точек данных.
Изменено в версии v1.1:
init_paramsтеперь принимает 'random_from_data' и 'k-means++' в качестве методов инициализации.- weight_concentration_prior_type{'dirichlet_process', 'dirichlet_distribution'}, по умолчанию='dirichlet_process'
Строка, описывающая тип априорного распределения концентрации весов.
- weight_concentration_priorfloat или None, default=None
Концентрация Дирихле каждого компонента в распределении весов (Дирихле). Это обычно называется гамма в литературе. Более высокая концентрация сосредотачивает больше массы в центре и приведет к большей активности компонентов, в то время как более низкий параметр концентрации приведет к большей массе на краю симплекса весов смеси. Значение параметра должно быть больше 0. Если оно равно None, устанавливается в
1. / n_components.- mean_precision_priorfloat или None, default=None
Априорная точность распределения средних (Гауссово). Контролирует область, где могут располагаться средние. Большие значения концентрируют средние кластеров вокруг
mean_prior. Значение параметра должно быть больше 0. Если None, устанавливается в 1.- mean_priorarray-like, форма (n_features,), по умолчанию=None
Априорное распределение на среднее распределение (Гауссово). Если оно None, устанавливается в среднее значение X.
- degrees_of_freedom_priorfloat или None, default=None
Априорное распределение числа степеней свободы для ковариационных распределений (Вишарта). Если None, устанавливается в
n_features.- covariance_priorfloat или array-like, по умолчанию=None
Априорное распределение ковариации (Вишарта). Если оно None, эмпирический априор ковариации инициализируется с использованием ковариации X. Форма зависит от
covariance_type:(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет случайным начальным числом, передаваемым выбранному методу для инициализации параметров (см.
init_params). Кроме того, он управляет генерацией случайных выборок из подобранного распределения (см. методsample). Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.- warm_startbool, по умолчанию=False
Если ‘warm_start’ установлен в True, решение последнего обучения используется как инициализация для следующего вызова fit(). Это может ускорить сходимость, когда fit вызывается несколько раз на схожих задачах. См. Глоссарий.
- verboseint, по умолчанию=0
Включить подробный вывод. Если 1, то выводится текущая инициализация и каждый шаг итерации. Если больше 1, то также выводятся логарифмическая вероятность и время, необходимое для каждого шага.
- verbose_intervalint, по умолчанию=10
Количество итераций, выполненных перед следующим выводом.
- Атрибуты:
- weights_массивоподобный формы (n_components,)
Веса каждой компоненты смеси.
- means_array-like формы (n_components, n_features)
Среднее значение каждой компоненты смеси.
- covariances_array-like
Ковариация каждой компоненты смеси. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_array-like
Матрицы точности для каждого компонента в смеси. Матрица точности - это обратная матрица ковариации. Матрица ковариации симметрична и положительно определена, поэтому смесь Гауссовых распределений может быть эквивалентно параметризована матрицами точности. Хранение матриц точности вместо матриц ковариации делает вычисление логарифма правдоподобия новых образцов на этапе тестирования более эффективным. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_cholesky_array-like
Разложение Холецкого матриц точности каждой компоненты смеси. Матрица точности является обратной ковариационной матрице. Ковариационная матрица симметрична и положительно определена, поэтому смесь Гауссовых распределений может быть эквивалентно параметризована матрицами точности. Хранение матриц точности вместо ковариационных матриц делает вычисление логарифма правдоподобия новых выборок при тестировании более эффективным. Форма зависит от
covariance_type:(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- converged_. Это приводит к другому графику при вызовеbool
True, когда была достигнута сходимость наилучшего соответствия вывода, False в противном случае.
- n_iter_int
Количество шагов, использованных лучшей подгонкой вывода для достижения сходимости.
- lower_bound_float
Нижняя граница значения свидетельства модели (обучающих данных) наилучшего соответствия вывода.
- lower_bounds_array-like формы (
n_iter_,) Список значений нижней границы для модели свидетельства из каждой итерации наилучшей подгонки вывода.
- weight_concentration_prior_кортеж или float
Концентрация Дирихле каждого компонента в распределении весов (Дирихле). Тип зависит от
weight_concentration_prior_type:(float, float) if 'dirichlet_process' (Beta parameters), float if 'dirichlet_distribution' (Dirichlet parameters).
Более высокая концентрация сосредотачивает больше массы в центре и приведет к большей активности компонентов, в то время как более низкий параметр концентрации приведет к большей массе на краю симплекса.
- weight_concentration_массивоподобный формы (n_components,)
Концентрация Дирихле каждого компонента в распределении весов (Дирихле).
- mean_precision_prior_float
Априорная точность распределения средних (гауссовского). Контролирует область, где могут располагаться средние. Большие значения концентрируют средние кластеров вокруг
mean_prior. Если mean_precision_prior установлен в None,mean_precision_prior_установлен в 1.- mean_precision_массивоподобный формы (n_components,)
Точность каждого компонента на среднем распределении (Гауссовом).
- mean_prior_массивоподобный формы (n_features,)
Априорное распределение на среднее распределение (Гауссово).
- degrees_of_freedom_prior_float
Априорное распределение числа степеней свободы для ковариационных распределений (Вишарта).
- degrees_of_freedom_массивоподобный формы (n_components,)
Количество степеней свободы каждого компонента в модели.
- covariance_prior_float или array-like
Априорное распределение ковариации (Вишарта). Форма зависит от
covariance_type:(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
GaussianMixtureКонечная гауссовская смесь, подобранная с помощью EM.
Ссылки
Примеры
>>> import numpy as np >>> from sklearn.mixture import BayesianGaussianMixture >>> X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [12, 4], [10, 7]]) >>> bgm = BayesianGaussianMixture(n_components=2, random_state=42).fit(X) >>> bgm.means_ array([[2.49 , 2.29], [8.45, 4.52 ]]) >>> bgm.predict([[0, 0], [9, 3]]) array([0, 1])
- fit(X, y=None)[источник]#
Оценить параметры модели с помощью алгоритма EM.
Метод обучает модель
n_initраз и устанавливает параметры, с которыми модель имеет наибольшую вероятность или нижнюю границу. В каждом испытании метод чередует E-шаг и M-шаг дляmax_iterраз, пока изменение правдоподобия или нижней границы не станет меньшеtol, в противном случае,ConvergenceWarningвызывается. Еслиwarm_startявляетсяTrue, затемn_initигнорируется, и единичная инициализация выполняется при первом вызове. При последующих вызовах обучение продолжается с того места, где оно остановилось.- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Подобранная смесь.
- fit_predict(X, y=None)[источник]#
Оценить параметры модели с использованием X и предсказать метки для X.
Метод обучает модель
n_initраз и устанавливает параметры, с которыми модель имеет наибольшую вероятность или нижнюю границу. В каждом испытании метод чередует E-шаг и M-шаг дляmax_iterраз, пока изменение правдоподобия или нижней границы не станет меньшеtol, в противном случае,ConvergenceWarningвызывается. После подгонки он предсказывает наиболее вероятную метку для входных точек данных.Добавлено в версии 0.20.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- меткимассив, формы (n_samples,)
Метки компонентов.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать метки для образцов данных в X с использованием обученной модели.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- меткимассив, формы (n_samples,)
Метки компонентов.
- predict_proba(X)[источник]#
Оцените плотность компонентов для каждого образца.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- respмассив, форма (n_samples, n_components)
Плотность каждой гауссовской компоненты для каждого образца в X.
- sample(n_samples=1)[источник]#
Генерировать случайные выборки из подобранного гауссовского распределения.
- Параметры:
- n_samplesint, по умолчанию=1
Количество образцов для генерации.
- Возвращает:
- Xмассив, форма (n_samples, n_features)
Случайно сгенерированный образец.
- yмассив, форма (nsamples,)
Метки компонентов.
- score(X, y=None)[источник]#
Вычислить среднее логарифмическое правдоподобие на выборку для данных X.
- Параметры:
- Xarray-like формы (n_samples, n_dimensions)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- логарифмическое правдоподобиеfloat
Логарифмическое правдоподобие
Xв рамках модели гауссовской смеси.
- score_samples(X)[источник]#
Вычислить логарифмическое правдоподобие для каждого образца.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Список n_features-мерных точек данных. Каждая строка соответствует одной точке данных.
- Возвращает:
- log_probмассив, формы (n_samples,)
Логарифм правдоподобия каждого образца в
Xв рамках текущей модели.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
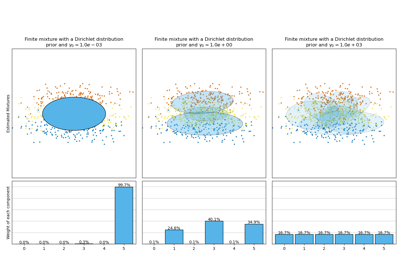
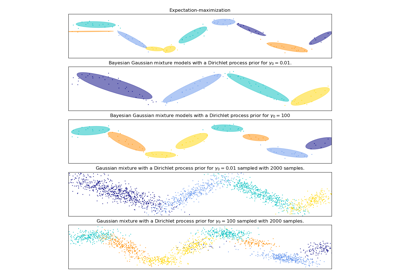
Анализ вариации байесовской гауссовой смеси с априорным типом концентрации