make_pipeline#
- sklearn.pipeline.make_pipeline(*шаги, память=None, transform_input=None, verbose=False)[источник]#
Создать
Pipelineиз заданных оценщиков.Это сокращение для
Pipelineконструктор; он не требует и не разрешает именовать оценщики. Вместо этого их имена будут автоматически установлены в нижний регистр их типов.- Параметры:
- *stepsсписок объектов Estimator
Список оценщиков scikit-learn, соединённых в цепочку.
- памятьstr или объект с интерфейсом joblib.Memory, по умолчанию=None
Используется для кэширования обученных трансформеров конвейера. Последний шаг никогда не кэшируется, даже если это трансформер. По умолчанию кэширование не выполняется. Если указана строка, это путь к директории кэширования. Включение кэширования вызывает клонирование трансформеров перед обучением. Поэтому экземпляр трансформера, переданный в конвейер, нельзя напрямую инспектировать. Используйте атрибут
named_stepsилиstepsдля проверки оценщиков в конвейере. Кэширование преобразователей выгодно, когда подгонка занимает много времени.- transform_inputсписок str, по умолчанию=None
Это позволяет преобразовывать некоторые входные аргументы в
fit(кромеX) для преобразования шагами конвейера до шага, который требует их. Требование определяется через маршрутизация метаданныхЭто можно использовать, например, для передачи набора валидации через конвейер.Это можно установить только если включена маршрутизация метаданных, которую можно включить с помощью
sklearn.set_config(enable_metadata_routing=True).Добавлено в версии 1.6.
- verbosebool, по умолчанию=False
Если True, затраченное время на подгонку каждого шага будет выводиться по мере завершения.
- Возвращает:
- pPipeline
Возвращает scikit-learn
Pipelineобъект.
Смотрите также
PipelineКласс для создания конвейера преобразований с финальным оценщиком.
Примеры
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.pipeline import make_pipeline >>> make_pipeline(StandardScaler(), GaussianNB(priors=None)) Pipeline(steps=[('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())])
Примеры галереи#


Демонстрация кластеризации K-Means на данных рукописных цифр
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов
Поддержка категориальных признаков в градиентном бустинге

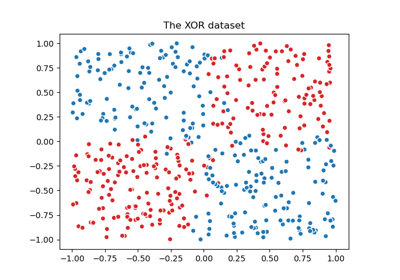
Визуализация вероятностных предсказаний VotingClassifier
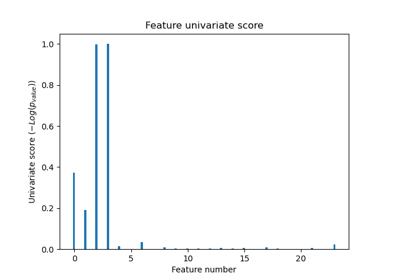

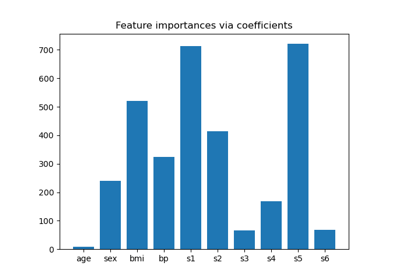
Основанный на модели и последовательный отбор признаков
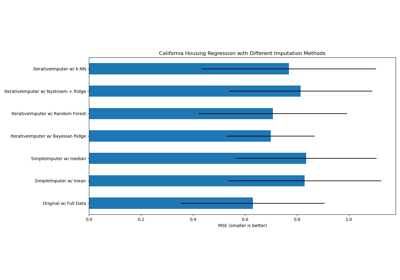
Заполнение пропущенных значений с вариантами IterativeImputer
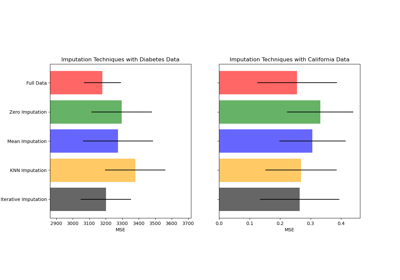
Заполнение пропущенных значений перед построением оценщика

Распространённые ошибки в интерпретации коэффициентов линейных моделей
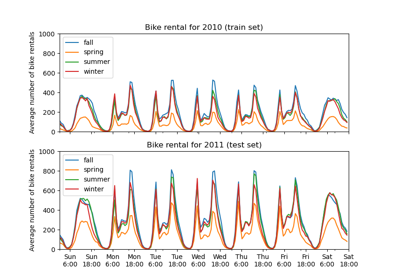
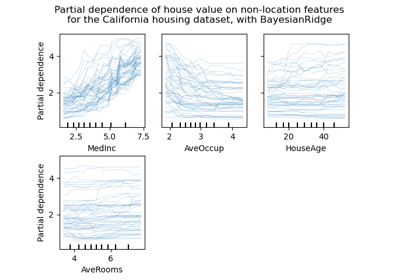
Графики частичной зависимости и индивидуального условного ожидания

Масштабируемое обучение с полиномиальной аппроксимацией ядра
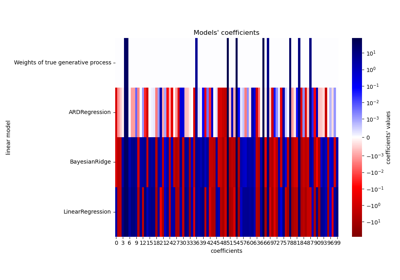
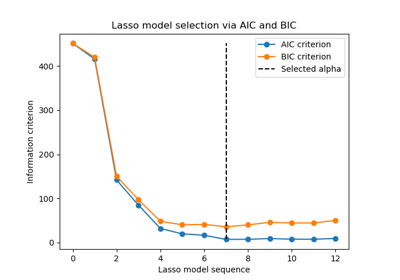
Выбор модели Lasso с помощью информационных критериев
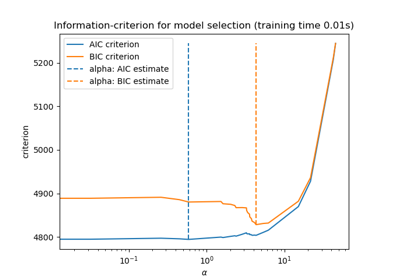
Выбор модели Lasso: AIC-BIC / перекрёстная проверка
One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных



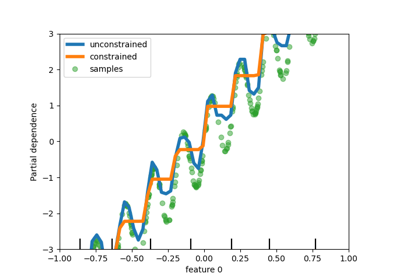
Расширенное построение графиков с частичной зависимостью

Последующая настройка порога принятия решений для обучения с учетом стоимости
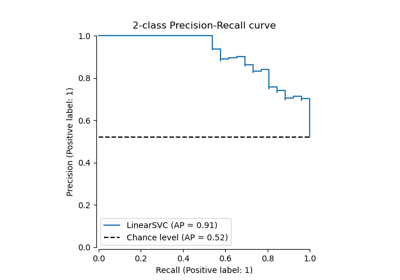
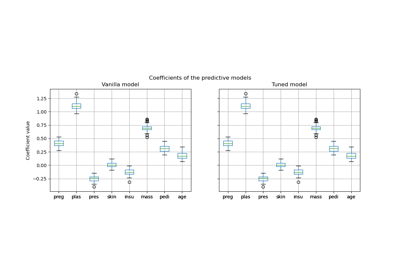
Пост-фактумная настройка точки отсечения функции принятия решений

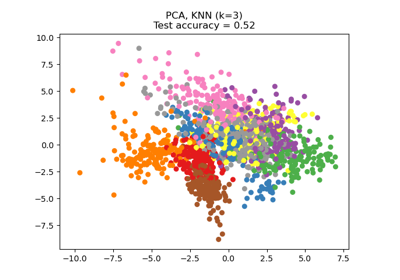
Снижение размерности с помощью анализа компонентов соседства
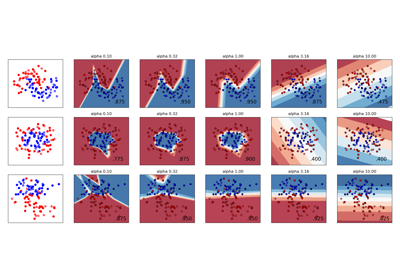
Изменение регуляризации в многослойном перцептроне
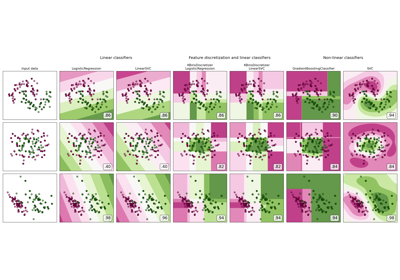
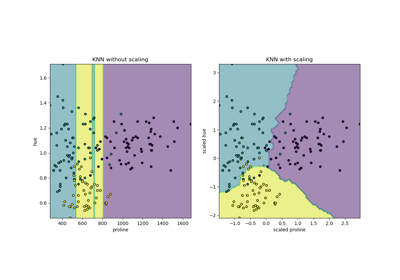
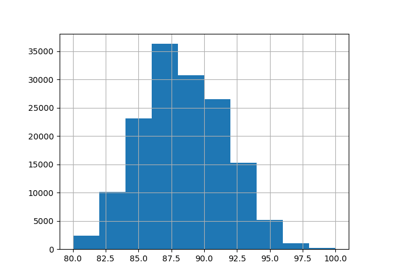
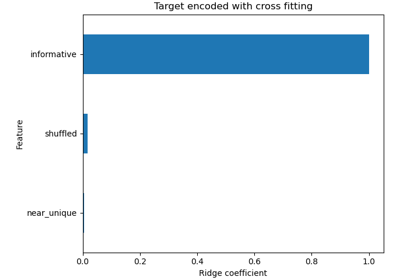


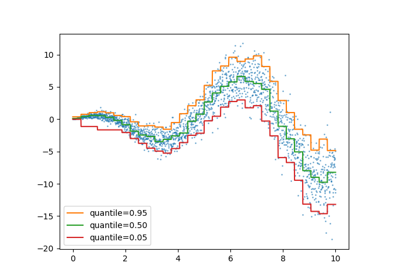
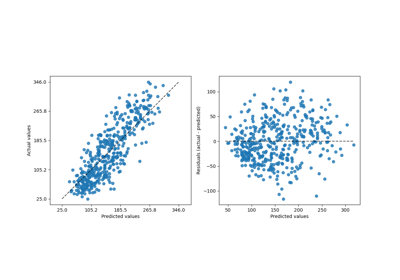
Кластеризация текстовых документов с использованием k-means