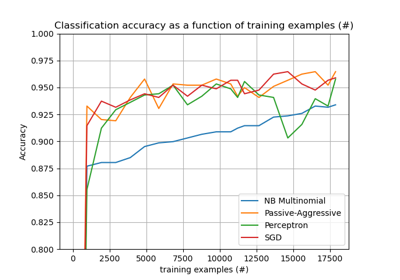
MultinomialNB#
- класс sklearn.naive_bayes.MultinomialNB(*, alpha=1.0, force_alpha=True, fit_prior=True, class_prior=None)[источник]#
Наивный байесовский классификатор для мультиномиальных моделей.
Мультиномиальный наивный байесовский классификатор подходит для классификации с дискретными признаками (например, подсчет слов для классификации текстов). Мультиномиальное распределение обычно требует целочисленных подсчетов признаков. Однако, на практике дробные подсчеты, такие как tf-idf, также могут работать.
Подробнее в Руководство пользователя.
- Параметры:
- alphafloat или array-like формы (n_features,), по умолчанию=1.0
Аддитивный параметр сглаживания (Лапласа/Лидстоуна) (установите alpha=0 и force_alpha=True для отключения сглаживания).
- force_alphabool, по умолчанию=True
Если False и alpha меньше 1e-10, он установит alpha в 1e-10. Если True, alpha останется неизменным. Это может вызвать числовые ошибки, если alpha слишком близок к 0.
Добавлено в версии 1.2.
Изменено в версии 1.4: Значение по умолчанию для
force_alphaизменено наTrue.- fit_priorbool, по умолчанию=True
Следует ли изучать априорные вероятности классов. Если false, будет использоваться равномерное априорное распределение.
- class_priorarray-like формы (n_classes,), по умолчанию=None
Априорные вероятности классов. Если указаны, априорные вероятности не корректируются в соответствии с данными.
- Атрибуты:
- class_count_ndarray формы (n_classes,)
Количество выборок, встреченных для каждого класса во время подгонки. Это значение взвешивается по весу выборки, если он предоставлен.
- class_log_prior_ndarray формы (n_classes,)
Сглаженная эмпирическая логарифмическая вероятность для каждого класса.
- classes_ndarray формы (n_classes,)
Метки классов, известные классификатору
- feature_count_ndarray формы (n_classes, n_features)
Количество образцов, встреченных для каждой (класс, признак) во время обучения. Это значение взвешивается по весу образца, если он предоставлен.
- feature_log_prob_ndarray формы (n_classes, n_features)
Эмпирическая логарифмическая вероятность признаков при заданном классе,
P(x_i|y).- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
BernoulliNBНаивный байесовский классификатор для многомерных моделей Бернулли.
CategoricalNBНаивный байесовский классификатор для категориальных признаков.
ComplementNBКомплементарный наивный байесовский классификатор.
GaussianNBНаивный байесовский классификатор Гаусса.
Ссылки
C.D. Manning, P. Raghavan и H. Schuetze (2008). Introduction to Information Retrieval. Cambridge University Press, стр. 234-265. https://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html
Примеры
>>> import numpy as np >>> rng = np.random.RandomState(1) >>> X = rng.randint(5, size=(6, 100)) >>> y = np.array([1, 2, 3, 4, 5, 6]) >>> from sklearn.naive_bayes import MultinomialNB >>> clf = MultinomialNB() >>> clf.fit(X, y) MultinomialNB() >>> print(clf.predict(X[2:3])) [3]
- fit(X, y, sample_weight=None)[источник]#
Обучает классификатор наивного Байеса по X, y.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса, применяемые к отдельным образцам (1. для невзвешенных).
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y, классы=None, sample_weight=None)[источник]#
Инкрементное обучение на пакете образцов.
Этот метод предназначен для многократного последовательного вызова на различных частях набора данных для реализации внеядерного или онлайн-обучения.
Это особенно полезно, когда весь набор данных слишком велик, чтобы поместиться в память сразу.
Этот метод имеет некоторую производительную нагрузку, поэтому лучше вызывать partial_fit на блоках данных, которые как можно больше (при условии, что они помещаются в память), чтобы скрыть нагрузку.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения.
- классыarray-like формы (n_classes,), по умолчанию=None
Список всех классов, которые могут появиться в векторе y.
Должен быть предоставлен при первом вызове partial_fit, может быть опущен в последующих вызовах.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса, применяемые к отдельным образцам (1. для невзвешенных).
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- predict(X)[источник]#
Выполнить классификацию на массиве тестовых векторов X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Cndarray формы (n_samples,)
Предсказанные целевые значения для X.
- predict_joint_log_proba(X)[источник]#
Возвращает совместные оценки логарифмической вероятности для тестового вектора X.
Для каждой строки x из X и класса y совместная логарифмическая вероятность задается как
log P(x, y) = log P(y) + log P(x|y),гдеlog P(y)является априорной вероятностью класса иlog P(x|y)является условной вероятностью класса.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Cndarray формы (n_samples, n_classes)
Возвращает совместную логарифмическую вероятность выборок для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- predict_log_proba(X)[источник]#
Возвращает оценки логарифмической вероятности для тестового вектора X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Carray-like формы (n_samples, n_classes)
Возвращает логарифм вероятности образцов для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- predict_proba(X)[источник]#
Возвращает оценки вероятности для тестового вектора X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Carray-like формы (n_samples, n_classes)
Возвращает вероятность выборок для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MultinomialNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, классы: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') MultinomialNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- классыstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
classesпараметр вpartial_fit.- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MultinomialNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.