TruncatedSVD#
- класс sklearn.decomposition.TruncatedSVD(n_components=2, *, алгоритм='randomized', n_iter=5, n_oversamples=10, power_iteration_normalizer='auto', random_state=None, tol=0.0)[источник]#
Снижение размерности с использованием усеченного SVD (также известного как LSA).
Этот преобразователь выполняет линейное снижение размерности с помощью усеченного сингулярного разложения (SVD). В отличие от PCA, этот оценщик не центрирует данные перед вычислением сингулярного разложения. Это означает, что он может эффективно работать с разреженными матрицами.
В частности, усеченное SVD работает с матрицами количества терминов/tf-idf, возвращаемыми векторизаторами в
sklearn.feature_extraction.text. В этом контексте он известен как латентно-семантический анализ (LSA).Этот оценщик поддерживает два алгоритма: быстрый рандомизированный решатель SVD и "наивный" алгоритм, который использует ARPACK в качестве решателя собственных значений на
X * X.TилиX.T * X, в зависимости от того, что эффективнее.Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, по умолчанию=2
Желаемая размерность выходных данных. Если algorithm='arpack', должна быть строго меньше количества признаков. Если algorithm='randomized', должна быть меньше или равна количеству признаков. Значение по умолчанию полезно для визуализации. Для LSA рекомендуется значение 100.
- алгоритм{‘arpack’, ‘randomized’}, по умолчанию=’randomized’
Решатель SVD для использования. Либо "arpack" для оболочки ARPACK в SciPy (scipy.sparse.linalg.svds), либо "randomized" для рандомизированного алгоритма Халко (2009).
- n_iterint, по умолчанию=5
Количество итераций для рандомизированного решателя SVD. Не используется ARPACK. Значение по умолчанию больше, чем по умолчанию в
randomized_svdдля обработки разреженных матриц, которые могут иметь большой медленно затухающий спектр.- n_oversamplesint, по умолчанию=10
Количество перевыборок для рандомизированного решателя SVD. Не используется ARPACK. См.
randomized_svdдля полного описания.Добавлено в версии 1.1.
- power_iteration_normalizer{‘auto’, ‘QR’, ‘LU’, ‘none’}, по умолчанию=’auto’
Нормализатор степенной итерации для рандомизированного решателя SVD. Не используется ARPACK. См.
randomized_svdдля получения дополнительной информации.Добавлено в версии 1.1.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Используется во время рандомизированного SVD. Передайте целое число для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.
- tolfloat, по умолчанию=0.0
Допуск для ARPACK. 0 означает машинную точность. Игнорируется рандомизированным решателем SVD.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Правые сингулярные векторы входных данных.
- explained_variance_ndarray формы (n_components,)
Дисперсия обучающих выборок, преобразованных проекцией на каждый компонент.
- explained_variance_ratio_ndarray формы (n_components,)
Процент дисперсии, объясняемый каждой из выбранных компонент.
- singular_values_ndarray формы (n_components,)
Сингулярные значения, соответствующие каждому из выбранных компонентов. Сингулярные значения равны 2-нормам
n_componentsпеременные в пространстве меньшей размерности.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
DictionaryLearningНайти словарь, который разреженно кодирует данные.
FactorAnalysisПростая линейная генеративная модель с гауссовскими латентными переменными.
IncrementalPCAИнкрементальный анализ главных компонент.
KernelPCAАнализ главных компонентов с ядром.
NMFНеотрицательная матричная факторизация.
PCAМетод главных компонент.
Примечания
SVD страдает от проблемы, называемой "неопределенностью знака", что означает, что знак
components_и выходные данные из transform зависят от алгоритма и случайного состояния. Чтобы обойти это, обучите экземпляры этого класса на данных один раз, затем сохраните экземпляр для выполнения преобразований.Ссылки
Примеры
>>> from sklearn.decomposition import TruncatedSVD >>> from scipy.sparse import csr_matrix >>> import numpy as np >>> np.random.seed(0) >>> X_dense = np.random.rand(100, 100) >>> X_dense[:, 2 * np.arange(50)] = 0 >>> X = csr_matrix(X_dense) >>> svd = TruncatedSVD(n_components=5, n_iter=7, random_state=42) >>> svd.fit(X) TruncatedSVD(n_components=5, n_iter=7, random_state=42) >>> print(svd.explained_variance_ratio_) [0.0157 0.0512 0.0499 0.0479 0.0453] >>> print(svd.explained_variance_ratio_.sum()) 0.2102 >>> print(svd.singular_values_) [35.2410 4.5981 4.5420 4.4486 4.3288]
- fit(X, y=None)[источник]#
Обучить модель на обучающих данных X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает объект трансформера.
- fit_transform(X, y=None)[источник]#
Обучить модель на X и выполнить уменьшение размерности на X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Уменьшенная версия X. Это всегда будет плотный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразование X обратно в исходное пространство.
Возвращает массив X_original, преобразование которого было бы X.
- Параметры:
- Xarray-like формы (n_samples, n_components)
Новые данные.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Обратите внимание, что это всегда плотный массив.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Выполнить уменьшение размерности для X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Уменьшенная версия X. Это всегда будет плотный массив.
Примеры галереи#

Преобразование признаков с хешированием с использованием полностью случайных деревьев

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…
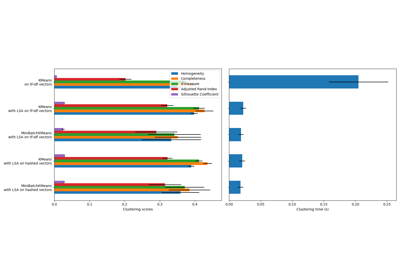
Кластеризация текстовых документов с использованием k-means