HistGradientBoostingClassifier#
- класс sklearn.ensemble.HistGradientBoostingClassifier(потеря='log_loss', *, learning_rate=0.1, max_iter=100, max_leaf_nodes=31, max_depth=None, min_samples_leaf=20, l2_regularization=0.0, max_features=1.0, max_bins=255, categorical_features='from_dtype', monotonic_cst=None, interaction_cst=None, warm_start=False, early_stopping='auto', оценка='loss', validation_fraction=0.1, n_iter_no_change=10, tol=1e-07, verbose=0, random_state=None, class_weight=None)[источник]#
Гистограммный градиентный бустинг для классификационных деревьев.
Этот оценщик намного быстрее, чем
GradientBoostingClassifierдля больших наборов данных (n_samples >= 10 000).Этот оценщик имеет встроенную поддержку пропущенных значений (NaN). Во время обучения алгоритм построения дерева изучает на каждой точке разделения, должны ли образцы с пропущенными значениями идти в левого или правого потомка, основываясь на потенциальном выигрыше. При прогнозировании образцы с пропущенными значениями назначаются левому или правому потомку соответственно. Если для данного признака во время обучения не встречались пропущенные значения, то образцы с пропущенными значениями направляются к тому потомку, у которого больше всего образцов.
Эта реализация вдохновлена LightGBM.
Подробнее в Руководство пользователя.
Добавлено в версии 0.21.
- Параметры:
- потеря{‘log_loss’}, по умолчанию=’log_loss’
Функция потерь для использования в процессе бустинга.
Для задач бинарной классификации 'log_loss' также известен как логистическая потеря, биномиальное отклонение или бинарная перекрестная энтропия. Внутренне модель обучает одно дерево за итерацию бустинга и использует логистическую сигмоидную функцию (expit) в качестве обратной функции связи для вычисления предсказанной вероятности положительного класса.
Для задач многоклассовой классификации 'log_loss' также известен как полиномиальное отклонение или категориальная кросс-энтропия. Внутренне модель обучает одно дерево за итерацию бустинга и за класс и использует функцию softmax как обратную функцию связи для вычисления предсказанных вероятностей классов.
- learning_ratefloat, по умолчанию=0.1
Скорость обучения, также известная как сжатие. Это используется как мультипликативный фактор для значений листьев. Используйте
1для отсутствия сжатия.- max_iterint, по умолчанию=100
Максимальное количество итераций процесса бустинга, т.е. максимальное количество деревьев для бинарной классификации. Для многоклассовой классификации,
n_classesдеревья строятся на каждой итерации.- max_leaf_nodesint или None, по умолчанию=31
Максимальное количество листьев для каждого дерева. Должно быть строго больше чем 1. Если None, максимального ограничения нет.
- max_depthint или None, по умолчанию=None
Максимальная глубина каждого дерева. Глубина дерева - это количество ребер от корня до самого глубокого листа. Глубина по умолчанию не ограничена.
- min_samples_leafint, по умолчанию=20
Минимальное количество образцов на лист. Для небольших наборов данных с менее чем несколькими сотнями образцов рекомендуется снизить это значение, поскольку будут построены только очень неглубокие деревья.
- l2_regularizationfloat, по умолчанию=0
Параметр регуляризации L2, штрафующий листья с малыми гессианами. Используйте
0для отсутствия регуляризации (по умолчанию).- max_featuresfloat, по умолчанию=1.0
Доля случайно выбранных признаков в каждом разделении узла. Это форма регуляризации, меньшие значения делают деревья более слабыми учениками и могут предотвратить переобучение. Если ограничения взаимодействия из
interaction_cstприсутствуют, только разрешённые признаки учитываются для субдискретизации.Добавлено в версии 1.4.
- max_binsint, по умолчанию=255
Максимальное количество бинов для использования с не пропущенными значениями. Перед обучением каждый признак входного массива
Xразбивается на целочисленные бины, что позволяет значительно ускорить этап обучения. Признаки с небольшим количеством уникальных значений могут использовать менееmax_binsбины. В дополнение кmax_binsбинов, всегда резервируется один дополнительный бин для пропущенных значений. Не должно быть больше 255.- categorical_featuresмассивоподобный из {bool, int, str} формы (n_features) или формы (n_categorical_features,), по умолчанию='from_dtype'
Указывает категориальные признаки.
None : никакой признак не будет считаться категориальным.
boolean array-like : логическая маска, указывающая категориальные признаки.
целочисленный массивоподобный : целочисленные индексы, указывающие категориальные признаки.
str array-like: имена категориальных признаков (предполагается, что обучающие данные имеют имена признаков).
"from_dtype": столбцы датафрейма с типом данных “category” считаются категориальными признаками. Входные данные должны быть объектом, предоставляющим__dataframe__метод, такой как pandas или polars DataFrames, чтобы использовать эту функцию.
Для каждой категориальной характеристики должно быть не более
max_binsуникальные категории. Отрицательные значения для категориальных признаков, закодированных как числовые dtypes, обрабатываются как пропущенные значения. Все категориальные значения преобразуются в числа с плавающей точкой. Это означает, что категориальные значения 1.0 и 1 обрабатываются как одна и та же категория.Подробнее в Руководство пользователя.
Добавлено в версии 0.24.
Изменено в версии 1.2: Добавлена поддержка имён признаков.
Изменено в версии 1.4: Добавлен
"from_dtype"опция.Изменено в версии 1.6: Значение по умолчанию изменилось с
Noneto"from_dtype".- monotonic_cstмассивоподобный из int формы (n_features) или dict, по умолчанию=None
Монотонные ограничения, применяемые к каждому признаку, задаются с помощью следующих целочисленных значений:
1: монотонное возрастание
0: без ограничений
-1: монотонное уменьшение
Если словарь со строковыми ключами, сопоставляет признаки с монотонными ограничениями по имени. Если массив, признаки сопоставляются с ограничениями по позиции. См. Использование имен признаков для указания монотонных ограничений для примера использования.
Ограничения действительны только для бинарной классификации и выполняются для вероятности положительного класса. Подробнее в Руководство пользователя.
Добавлено в версии 0.23.
Изменено в версии 1.2: Принимает словарь ограничений с именами признаков в качестве ключей.
- interaction_cst{“pairwise”, “no_interactions”} или последовательность списков/кортежей/множеств int, по умолчанию=None
Укажите ограничения взаимодействия, наборы признаков, которые могут взаимодействовать друг с другом при разделениях дочерних узлов.
Каждый элемент задает набор индексов признаков, которым разрешено взаимодействовать друг с другом. Если признаков больше, чем указано в этих ограничениях, они обрабатываются так, как если бы были указаны в дополнительном наборе.
Строки "pairwise" и "no_interactions" являются сокращениями для разрешения только попарных или отсутствия взаимодействий соответственно.
Например, с 5 признаками в общей сложности,
interaction_cst=[{0, 1}]эквивалентноinteraction_cst=[{0, 1}, {2, 3, 4}], и указывает, что каждая ветвь дерева будет разделяться только по признакам 0 и 1 или только по признакам 2, 3 и 4.См. этот пример о том, как использовать
interaction_cst.Добавлено в версии 1.2.
- warm_startbool, по умолчанию=False
При установке значения
True, повторно использовать решение предыдущего вызова fit и добавить больше оценщиков в ансамбль. Для валидности результатов оценщик должен быть переобучен на тех же данных только. См. Глоссарий.- early_stopping‘auto’ или bool, по умолчанию=’auto’
Если ‘auto’, ранняя остановка включается, если размер выборки больше 10000 или если
X_valиy_valпередаются вfit. Если True, ранняя остановка включена, в противном случае ранняя остановка отключена.Добавлено в версии 0.23.
- оценкаstr или callable или None, по умолчанию='loss'
Метод оценки для использования при ранней остановке. Используется только если
early_stoppingвключено. Опции:str: см. Строковые имена скореров для опций.
callable: вызываемый объект scorer (например, функция) с сигнатурой
scorer(estimator, X, y). См. Вызываемые скореры подробности.None: точность используется.'loss': ранняя остановка проверяется относительно значения потерь.
- validation_fractionint или float или None, по умолчанию=0.1
Доля (или абсолютный размер) обучающих данных, которые следует отложить в качестве проверочных данных для ранней остановки. Если None, ранняя остановка выполняется на обучающих данных. Значение игнорируется, если ранняя остановка не выполняется, например,
early_stopping=False, или еслиX_valиy_valпередаются в fit.- n_iter_no_changeint, по умолчанию=10
Используется для определения, когда "остановиться раньше". Процесс обучения останавливается, когда ни один из последних
n_iter_no_changeоценки лучше чемn_iter_no_change - 1-й с конца, с некоторой допускаемой погрешностью. Используется только при ранней остановке.- tolfloat, по умолчанию=1e-7
Абсолютный допуск при сравнении оценок. Чем выше допуск, тем вероятнее ранняя остановка: более высокий допуск означает, что последующим итерациям будет сложнее считаться улучшением по сравнению с эталонной оценкой.
- verboseint, по умолчанию=0
Уровень детализации. Если не ноль, выводит некоторую информацию о процессе обучения.
1выводит только сводную информацию,2выводит информацию на каждой итерации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Псевдослучайный генератор чисел для управления субдискретизацией в процессе бинирования и разделением данных на обучающую/валидационную выборки, если включена ранняя остановка. Передайте целое число для воспроизводимого результата при многократных вызовах функции. См. Глоссарий.
- class_weightdict или 'balanced', по умолчанию=None
Weights associated with classes in the form
{class_label: weight}. Если не указано, предполагается, что все классы имеют вес один. Режим "balanced" использует значения y для автоматической настройки весов, обратно пропорциональных частотам классов во входных данных, какn_samples / (n_classes * np.bincount(y)). Обратите внимание, что эти веса будут умножены на sample_weight (переданный через метод fit), еслиsample_weightуказан.Добавлено в версии 1.2.
- Атрибуты:
- classes_массив, shape = (n_classes,)
Метки классов.
- do_early_stopping_bool
Указывает, используется ли ранняя остановка во время обучения.
n_iter_intКоличество итераций процесса бустинга.
- n_trees_per_iteration_int
Количество деревьев, которые строятся на каждой итерации. Это равно 1 для бинарной классификации и
n_classesдля многоклассовой классификации.- train_score_ndarray, форма (n_iter_+1,)
Оценки на каждой итерации на обучающих данных. Первая запись - оценка ансамбля до первой итерации. Оценки вычисляются в соответствии с
scoringпараметр. Еслиscoringне является 'loss', оценки вычисляются на подмножестве не более 10 000 примеров. Пусто, если ранняя остановка не применяется.- со своимndarray, форма (n_iter_+1,)
Оценки на каждой итерации на отложенных валидационных данных. Первая запись — это оценка ансамбля до первой итерации. Оценки вычисляются в соответствии с
scoringпараметр. Пусто, если нет ранней остановки или еслиvalidation_fractionравно None.- is_categorical_ndarray, форма (n_features, ) или None
Булева маска для категориальных признаков.
Noneесли нет категориальных признаков.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
GradientBoostingClassifierТочный метод градиентного бустинга, который не так хорошо масштабируется на наборах данных с большим количеством образцов.
sklearn.tree.DecisionTreeClassifierКлассификатор дерева решений.
RandomForestClassifierМета-оценщик, который обучает несколько классификаторов дерева решений на различных подвыборках набора данных и использует усреднение для улучшения прогнозной точности и контроля переобучения.
AdaBoostClassifierМета-оцениватель, который начинает с обучения классификатора на исходном наборе данных, а затем обучает дополнительные копии классификатора на том же наборе данных, где веса неправильно классифицированных экземпляров корректируются так, чтобы последующие классификаторы больше фокусировались на сложных случаях.
Примеры
>>> from sklearn.ensemble import HistGradientBoostingClassifier >>> from sklearn.datasets import load_iris >>> X, y = load_iris(return_X_y=True) >>> clf = HistGradientBoostingClassifier().fit(X, y) >>> clf.score(X, y) 1.0
- decision_function(X)[источник]#
Вычислить решающую функцию
X.- Параметры:
- Xarray-like, shape (n_samples, n_features)
Входные образцы.
- Возвращает:
- decisionndarray, форма (n_samples,) или (n_samples, n_trees_per_iteration)
Сырые предсказанные значения (т.е. сумма листьев деревьев) для каждого образца. n_trees_per_iteration равно количеству классов в многоклассовой классификации.
- fit(X, y, sample_weight=None, *, X_val=None, y_val=None, sample_weight_val=None)[источник]#
Обучить модель градиентного бустинга.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- yarray-like формы (n_samples,)
Целевые значения.
- sample_weightarray-like формы (n_samples,) по умолчанию=None
Веса обучающих данных.
Добавлено в версии 0.23.
- X_valarray-like формы (n_val, n_features)
Дополнительная выборка признаков для валидации, используемая в ранней остановке. В
Pipeline,X_valможет быть преобразован таким же образом, какXсPipeline(..., transform_input=["X_val"]).Добавлено в версии 1.7.
- y_valarray-like формы (n_samples,)
Дополнительный образец целевых значений для валидации, используемый в ранней остановке.
Добавлено в версии 1.7.
- sample_weight_valarray-like формы (n_samples,) по умолчанию=None
Дополнительные веса для валидации, используемые при ранней остановке.
Добавлено в версии 1.7.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать классы для X.
- Параметры:
- Xarray-like, shape (n_samples, n_features)
Входные образцы.
- Возвращает:
- yndarray, форма (n_samples,)
Предсказанные классы.
- predict_proba(X)[источник]#
Предсказать вероятности классов для X.
- Параметры:
- Xarray-like, shape (n_samples, n_features)
Входные образцы.
- Возвращает:
- pndarray, форма (n_samples, n_classes)
Вероятности классов входных образцов.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, X_val: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$', sample_weight_val: bool | None | str = '$UNCHANGED$', y_val: bool | None | str = '$UNCHANGED$') HistGradientBoostingClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- X_valstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
X_valпараметр вfit.- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.- sample_weight_valstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weight_valпараметр вfit.- y_valstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
y_valпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') HistGradientBoostingClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
- staged_decision_function(X)[источник]#
Вычислить функцию решения для
Xдля каждой итерации.Этот метод позволяет осуществлять мониторинг (т.е. определять ошибку на тестовом наборе) после каждого этапа.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- decisionгенератор ndarray формы (n_samples,) или (n_samples, n_trees_per_iteration)
Функция принятия решений для входных выборок, которая соответствует сырым значениям, предсказанным из деревьев ансамбля. Классы соответствуют тем, что в атрибуте classes_.
- staged_predict(X)[источник]#
Предсказать классы на каждой итерации.
Этот метод позволяет осуществлять мониторинг (т.е. определять ошибку на тестовом наборе) после каждого этапа.
Добавлено в версии 0.24.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- yгенератор ndarray формы (n_samples,)
Предсказанные классы входных выборок для каждой итерации.
- staged_predict_proba(X)[источник]#
Предсказать вероятности классов на каждой итерации.
Этот метод позволяет осуществлять мониторинг (т.е. определять ошибку на тестовом наборе) после каждого этапа.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- yгенератор ndarray формы (n_samples,)
Предсказанные вероятности классов входных выборок, для каждой итерации.
Примеры галереи#
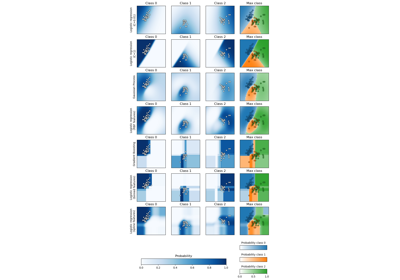

Сравнение моделей случайных лесов и градиентного бустинга на гистограммах
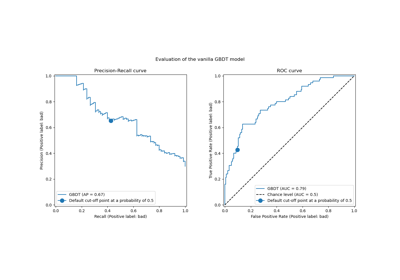
Последующая настройка порога принятия решений для обучения с учетом стоимости