roc_auc_score#
- sklearn.metrics.roc_auc_score(y_true, y_score, *, среднее='macro', sample_weight=None, max_fpr=None, multi_class='raise', метки=None)[источник]#
Вычисление площади под кривой рабочих характеристик приемника (ROC AUC) по прогнозным оценкам.
Примечание: эта реализация может использоваться с бинарный, многоклассовый и многометочный классификация, но применяются некоторые ограничения (см. Параметры).
Подробнее в Руководство пользователя.
- Параметры:
- y_trueмассивоподобный формы (n_samples,) или (n_samples, n_classes)
Истинные метки или бинарные индикаторы меток. В бинарном и многоклассовом случаях ожидаются метки формы (n_samples,), тогда как в многометочном случае ожидаются бинарные индикаторы меток формы (n_samples, n_classes).
- y_scoreмассивоподобный формы (n_samples,) или (n_samples, n_classes)
Целевые оценки.
В бинарный случай, соответствует массиву формы
(n_samples,). Могут быть предоставлены как вероятностные оценки, так и непороговые значения решений. Вероятностные оценки соответствуют вероятность класса с большей меткой, т.е.estimator.classes_[1]и, следовательно,estimator.predict_proba(X, y)[:, 1]. Решающие значения соответствуют выходуestimator.decision_function(X, y). См. дополнительную информацию в Руководство пользователя;В многоклассовый случай, соответствует массиву формы
(n_samples, n_classes)оценок вероятности, предоставляемыхpredict_probaметодом. Оценки вероятности должен суммируются до 1 по возможным классам. Кроме того, порядок оценок классов должен соответствовать порядкуlabels, если предоставлено, или же в числовом или лексикографическом порядке меток вy_true. Более подробную информацию см. в Руководство пользователя;В многометочный случай, соответствует массиву формы
(n_samples, n_classes). Вероятностные оценки предоставляютсяpredict_probaметод и не пороговые значения решенийdecision_functionметод. Вероятностные оценки соответствуют вероятность класса с большей меткой для каждого выхода классификатора. Подробнее см. в Руководство пользователя.
- среднее{'micro', 'macro', 'samples', 'weighted'} или None, по умолчанию='macro'
Если
None, оценки для каждого класса возвращаются. В противном случае это определяет тип усреднения, выполняемого над данными. Примечание: многоклассовый ROC AUC в настоящее время обрабатывает только усреднения 'macro' и 'weighted'. Для многоклассовых целей,average=Noneреализован только дляmulti_class='ovr'иaverage='micro'реализован только дляmulti_class='ovr'.'micro':Вычислите метрики глобально, рассматривая каждый элемент индикаторной матрицы меток как метку.
'macro':Вычислить метрики для каждой метки и найти их невзвешенное среднее. Это не учитывает дисбаланс меток.
'weighted':Рассчитать метрики для каждой метки и найти их среднее, взвешенное по поддержке (количество истинных экземпляров для каждой метки).
'samples':Вычислить метрики для каждого экземпляра и найти их среднее значение.
Будет игнорироваться, когда
y_trueявляется бинарным.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- max_fprfloat > 0 и <= 1, по умолчанию=None
Если не
None, стандартизированная частичная AUC [2] по диапазону [0, max_fpr] возвращается. Для многоклассового случаяmax_fpr, должно быть либо равноNoneили1.0так как частичное вычисление AUC ROC в настоящее время не поддерживается для многоклассовой классификации.- multi_class{‘raise’, ‘ovr’, ‘ovo’}, по умолчанию=’raise’
Используется только для многоклассовых целей. Определяет тип конфигурации для использования. Значение по умолчанию вызывает ошибку, поэтому либо
'ovr'или'ovo'должен быть передан явно.'ovr':Обозначает One-vs-rest. Вычисляет AUC каждого класса против остальных [3] [4]. Это обрабатывает многоклассовый случай так же, как многометочный случай. Чувствителен к дисбалансу классов, даже когда
average == 'macro', потому что дисбаланс классов влияет на состав каждой из группировок 'остальных'.'ovo':Обозначает "Один против одного". Вычисляет среднее значение AUC всех возможных попарных комбинаций классов [5]. Нечувствителен к дисбалансу классов, когда
average == 'macro'.
- меткиarray-like формы (n_classes,), по умолчанию=None
Используется только для многоклассовых целей. Список меток, индексирующих классы в
y_score. ЕслиNone, численный или лексикографический порядок меток вy_trueиспользуется.
- Возвращает:
- aucfloat
Оценка площади под кривой.
Смотрите также
average_precision_scoreПлощадь под кривой точности-полноты.
roc_curveВычислить кривую рабочих характеристик приемника (ROC).
RocCurveDisplay.from_estimatorПостроение кривой рабочей характеристики приёмника (ROC) для заданного оценщика и некоторых данных.
RocCurveDisplay.from_predictionsПостроить кривую рабочих характеристик приемника (ROC) по истинным и предсказанным значениям.
Примечания
Коэффициент Джини — это сводная мера ранжирующей способности бинарных классификаторов. Он выражается с использованием площади под ROC следующим образом:
G = 2 * AUC - 1
Где G - коэффициент Джини, а AUC - оценка ROC-AUC. Эта нормализация гарантирует, что случайное угадывание даст ожидаемую оценку 0, и она ограничена сверху 1.
Ссылки
[3]Provost, F., Domingos, P. (2000). Well-trained PETs: Improving probability estimation trees (Section 6.2), CeDER Working Paper #IS-00-04, Stern School of Business, New York University.
[4]Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861-874.
[5]Примеры
Бинарный случай:
>>> from sklearn.datasets import load_breast_cancer >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.metrics import roc_auc_score >>> X, y = load_breast_cancer(return_X_y=True) >>> clf = LogisticRegression(solver="newton-cholesky", random_state=0).fit(X, y) >>> roc_auc_score(y, clf.predict_proba(X)[:, 1]) 0.99 >>> roc_auc_score(y, clf.decision_function(X)) 0.99
Многоклассовый случай:
>>> from sklearn.datasets import load_iris >>> X, y = load_iris(return_X_y=True) >>> clf = LogisticRegression(solver="newton-cholesky").fit(X, y) >>> roc_auc_score(y, clf.predict_proba(X), multi_class='ovr') 0.99
Многометочный случай:
>>> import numpy as np >>> from sklearn.datasets import make_multilabel_classification >>> from sklearn.multioutput import MultiOutputClassifier >>> X, y = make_multilabel_classification(random_state=0) >>> clf = MultiOutputClassifier(clf).fit(X, y) >>> # get a list of n_output containing probability arrays of shape >>> # (n_samples, n_classes) >>> y_score = clf.predict_proba(X) >>> # extract the positive columns for each output >>> y_score = np.transpose([score[:, 1] for score in y_score]) >>> roc_auc_score(y, y_score, average=None) array([0.828, 0.852, 0.94, 0.869, 0.95]) >>> from sklearn.linear_model import RidgeClassifierCV >>> clf = RidgeClassifierCV().fit(X, y) >>> roc_auc_score(y, clf.decision_function(X), average=None) array([0.82, 0.847, 0.93, 0.872, 0.944])
Примеры галереи#
Основанный на модели и последовательный отбор признаков
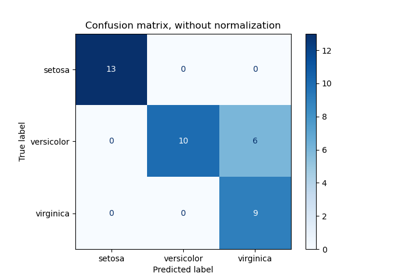
Оценить производительность классификатора с помощью матрицы ошибок
Статистическое сравнение моделей с использованием поиска по сетке
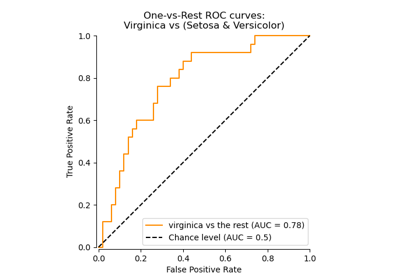
Многоклассовая рабочая характеристика приемника (ROC)