TSNE#
- класс sklearn.manifold.TSNE(n_components=2, *, перплексия=30.0, early_exaggeration=12.0, learning_rate='auto', max_iter=1000, n_iter_without_progress=300, min_grad_norm=1e-07, метрика='euclidean', metric_params=None, init='pca', verbose=0, random_state=None, метод='barnes_hut', угол=0.5, n_jobs=None)[источник]#
Стохастическое вложение соседей с t-распределением.
t-SNE [1] — это инструмент для визуализации многомерных данных. Он преобразует сходства между точками данных в совместные вероятности и пытается минимизировать расхождение Кульбака-Лейблера между совместными вероятностями низкоразмерного вложения и многомерных данных. t-SNE имеет функцию стоимости, которая не является выпуклой, т.е. с разными инициализациями мы можем получить разные результаты.
Настоятельно рекомендуется использовать другой метод уменьшения размерности (например, PCA для плотных данных или TruncatedSVD для разреженных данных), чтобы уменьшить количество измерений до разумного количества (например, 50), если количество признаков очень велико. Это подавит некоторый шум и ускорит вычисление попарных расстояний между образцами. Дополнительные советы см. в FAQ Laurens van der Maaten [2].
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, по умолчанию=2
Размерность вложенного пространства.
- перплексияfloat, default=30.0
Перплексия связана с количеством ближайших соседей, используемых в других алгоритмах обучения многообразий. Большие наборы данных обычно требуют большей перплексии. Рассмотрите выбор значения между 5 и 50. Разные значения могут давать значительно разные результаты. Перплексия должна быть меньше количества образцов.
- early_exaggerationfloat, по умолчанию=12.0
Определяет, насколько плотными будут естественные кластеры в исходном пространстве во вложенном пространстве и сколько места будет между ними. Для больших значений пространство между естественными кластерами будет больше во вложенном пространстве. Опять же, выбор этого параметра не является критически важным. Если функция стоимости увеличивается во время начальной оптимизации, коэффициент раннего преувеличения или скорость обучения могут быть слишком высокими.
- learning_ratefloat или "auto", по умолчанию="auto"
Скорость обучения для t-SNE обычно находится в диапазоне [10.0, 1000.0]. Если скорость обучения слишком высока, данные могут выглядеть как "шар", где любая точка примерно равноудалена от своих ближайших соседей. Если скорость обучения слишком низкая, большинство точек могут выглядеть сжатыми в плотном облаке с небольшим количеством выбросов. Если функция стоимости застревает в плохом локальном минимуме, увеличение скорости обучения может помочь. Обратите внимание, что многие другие реализации t-SNE (bhtsne, FIt-SNE, openTSNE, и т.д.) используют определение learning_rate, которое в 4 раза меньше нашего. Таким образом, наш learning_rate=200 соответствует learning_rate=800 в этих других реализациях. Опция 'auto' устанавливает learning_rate равным
max(N / early_exaggeration / 4, 50)где N - размер выборки, следуя [4] и [5].Изменено в версии 1.2: Значение по умолчанию изменилось на
"auto".- max_iterint, по умолчанию=1000
Максимальное количество итераций для оптимизации. Должно быть не менее 250.
Изменено в версии 1.5: Имя параметра изменено с
n_itertomax_iter.- n_iter_without_progressint, по умолчанию=300
Максимальное количество итераций без прогресса перед прерыванием оптимизации, используется после 250 начальных итераций с ранним преувеличением. Обратите внимание, что прогресс проверяется только каждые 50 итераций, поэтому это значение округляется до следующего кратного 50.
Добавлено в версии 0.17: параметр n_iter_without_progress для управления критериями остановки.
- min_grad_normfloat, по умолчанию=1e-7
Если норма градиента ниже этого порога, оптимизация будет остановлена.
- метрикаstr или callable, по умолчанию='euclidean'
Метрика для использования при вычислении расстояния между экземплярами в массиве признаков. Если metric — строка, она должна быть одной из опций, разрешенных scipy.spatial.distance.pdist для параметра metric, или метрикой, перечисленной в pairwise.PAIRWISE_DISTANCE_FUNCTIONS. Если metric — "precomputed", предполагается, что X — матрица расстояний. Альтернативно, если metric — вызываемая функция, она вызывается для каждой пары экземпляров (строк), и полученное значение записывается. Функция должна принимать два массива из X в качестве входных данных и возвращать значение, указывающее расстояние между ними. По умолчанию используется "euclidean", что интерпретируется как квадрат евклидова расстояния.
- metric_paramsdict, по умолчанию=None
Дополнительные именованные аргументы для метрической функции.
Добавлено в версии 1.1.
- init{“random”, “pca”} или ndarray формы (n_samples, n_components), по умолчанию=”pca”
Инициализация вложения. Инициализация PCA не может использоваться с предвычисленными расстояниями и обычно более глобально стабильна, чем случайная инициализация.
Изменено в версии 1.2: Значение по умолчанию изменилось на
"pca".- verboseint, по умолчанию=0
Уровень подробности вывода.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генератор случайных чисел. Передайте целое число для воспроизводимых результатов при множественных вызовах функции. Обратите внимание, что разные инициализации могут приводить к разным локальным минимумам функции стоимости. См. Глоссарий.
- метод{'barnes_hut', 'exact'}, по умолчанию='barnes_hut'
По умолчанию алгоритм вычисления градиента использует аппроксимацию Барнса-Хата, работающую за время O(NlogN). method='exact' запустит более медленный, но точный алгоритм за время O(N^2). Точный алгоритм следует использовать, когда ошибки ближайших соседей должны быть лучше 3%. Однако точный метод не масштабируется до миллионов примеров.
Добавлено в версии 0.17: Приближенная оптимизация метод с помощью метода Барнса-Хата.
- уголfloat, по умолчанию=0.5
Используется только если method=’barnes_hut’ Это компромисс между скоростью и точностью для Barnes-Hut T-SNE. ‘angle’ — угловой размер (обозначаемый как theta в [3]) удалённого узла, измеренный из точки. Если этот размер меньше ‘angle’, то он используется как суммарный узел для всех содержащихся в нём точек. Этот метод не очень чувствителен к изменениям этого параметра в диапазоне 0.2 - 0.8. Угол меньше 0.2 быстро увеличивает время вычислений, а угол больше 0.8 быстро увеличивает ошибку.
- n_jobsint, default=None
Количество параллельных задач для поиска соседей. Этот параметр не влияет, когда
metric="precomputed"или (metric="euclidean"иmethod="exact").Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.Добавлено в версии 0.22.
- Атрибуты:
- embedding_array-like формы (n_samples, n_components)
Хранит векторы вложения.
- kl_divergence_float
Расхождение Кульбака-Лейблера после оптимизации.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- learning_rate_float
Эффективная скорость обучения.
Добавлено в версии 1.2.
- n_iter_int
Количество выполненных итераций.
Смотрите также
sklearn.decomposition.PCAАнализ главных компонент, который является методом линейного снижения размерности.
sklearn.decomposition.KernelPCAНелинейное снижение размерности с использованием ядер и PCA.
MDSМногообразие обучения с использованием многомерного масштабирования.
IsomapОбучение многообразию на основе изометрического отображения.
LocallyLinearEmbeddingОбучение многообразий с использованием локально линейного вложения.
SpectralEmbeddingСпектральное вложение для нелинейного снижения размерности.
Примечания
Первый график визуализирует функцию принятия решений для различных значений параметров на упрощенной задаче классификации, включающей только 2 входных признака и 2 возможных целевых класса (бинарная классификация). Обратите внимание, что такой график невозможно построить для задач с большим количеством признаков или целевых классов.
TSNEв комбинации сKNeighborsTransformerсм. Приближенные ближайшие соседи в TSNE.Ссылки
- [1] van der Maaten, L.J.P.; Hinton, G.E. Visualizing High-Dimensional Data
Использование t-SNE. Journal of Machine Learning Research 9:2579-2605, 2008.
- [2] van der Maaten, L.J.P. t-распределённое стохастическое вложение соседей
- [3] L.J.P. van der Maaten. Accelerating t-SNE using Tree-Based Algorithms.
Journal of Machine Learning Research 15(Oct):3221-3245, 2014. https://lvdmaaten.github.io/publications/papers/JMLR_2014.pdf
- [4] Belkina, A. C., Ciccolella, C. O., Anno, R., Halpert, R., Spidlen, J.,
& Snyder-Cappione, J. E. (2019). Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets. Nature Communications, 10(1), 1-12.
- [5] Kobak, D., & Berens, P. (2019). The art of using t-SNE for single-cell
транскриптомика. Nature Communications, 10(1), 1-14.
Примеры
>>> import numpy as np >>> from sklearn.manifold import TSNE >>> X = np.array([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]]) >>> X_embedded = TSNE(n_components=2, learning_rate='auto', ... init='random', perplexity=3).fit_transform(X) >>> X_embedded.shape (4, 2)
- fit(X, y=None)[источник]#
Преобразование X во встроенное пространство.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Если метрика 'precomputed', X должна быть квадратной матрицей расстояний. В противном случае она содержит выборку в каждой строке. Если метод 'точный', X может быть разреженной матрицей типа 'csr', 'csc' или 'coo'. Если метод 'barnes_hut' и метрика 'precomputed', X может быть предварительно вычисленным разреженным графом.
- yNone
Игнорируется.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_transform(X, y=None)[источник]#
Обучить X во встроенном пространстве и вернуть преобразованный вывод.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Если метрика 'precomputed', X должна быть квадратной матрицей расстояний. В противном случае она содержит выборку в каждой строке. Если метод 'точный', X может быть разреженной матрицей типа 'csr', 'csc' или 'coo'. Если метод 'barnes_hut' и метрика 'precomputed', X может быть предварительно вычисленным разреженным графом.
- yNone
Игнорируется.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Встраивание обучающих данных в пространство низкой размерности.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#

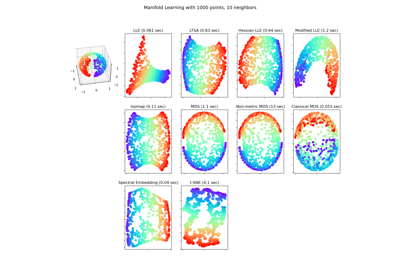
Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…
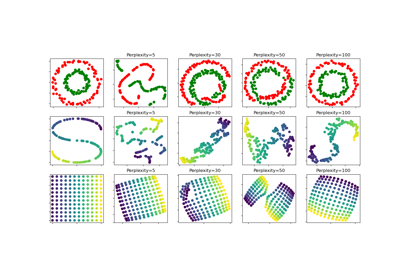
t-SNE: Влияние различных значений perplexity на форму
