MiniBatchKMeans#
- класс sklearn.cluster.MiniBatchKMeans(n_clusters=8, *, init='k-means++', max_iter=100, batch_size=1024, verbose=0, compute_labels=True, random_state=None, tol=0.0, max_no_improvement=10, init_size=None, n_init='auto', reassignment_ratio=0.01)[источник]#
Кластеризация Mini-Batch K-Means.
Подробнее в Руководство пользователя.
- Параметры:
- n_clustersint, по умолчанию=8
Количество кластеров для формирования, а также количество центроидов для генерации.
- init{‘k-means++’, ‘random’}, вызываемый объект или массив формы (n_clusters, n_features), по умолчанию=’k-means++’
Метод инициализации:
‘k-means++’ : выбирает начальные центроиды кластеров с использованием выборки на основе эмпирического распределения вероятностей вклада точек в общую инерцию. Этот метод ускоряет сходимость. Реализованный алгоритм - "жадный k-means++". Он отличается от ванильного k-means++ тем, что делает несколько попыток на каждом шаге выборки и выбирает лучший центроид среди них.
‘random’: выбирать
n_clustersнаблюдения (строки) случайным образом из данных для начальных центроидов.Если передается массив, он должен иметь форму (n_clusters, n_features) и задавать начальные центры.
Если передается вызываемый объект, он должен принимать аргументы X, n_clusters и случайное состояние и возвращать инициализацию.
Для оценки влияния инициализации см. пример Эмпирическая оценка влияния инициализации k-means.
- max_iterint, по умолчанию=100
Максимальное количество итераций по полному набору данных перед остановкой независимо от любых эвристик критерия ранней остановки.
- batch_sizeint, default=1024
Размер мини-пакетов. Для более быстрых вычислений можно установить
batch_size > 256 * number_of_coresвключить параллелизм на всех ядрах.Изменено в версии 1.0:
batch_sizeзначение по умолчанию изменено с 100 на 1024.- verboseint, по умолчанию=0
Режим подробности.
- compute_labelsbool, по умолчанию=True
Вычисление назначения меток и инерции для полного набора данных после сходимости оптимизации мини-пакетов в fit.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для инициализации центроидов и случайного перераспределения. Используйте целое число, чтобы сделать случайность детерминированной. См. Глоссарий.
- tolfloat, по умолчанию=0.0
Управление ранней остановкой на основе относительных изменений центров, измеряемых сглаженной, нормализованной по дисперсии средней квадратичной позиции изменений центров. Эта эвристика ранней остановки ближе к той, что используется для пакетного варианта алгоритмов, но вызывает небольшие вычислительные и затраты памяти по сравнению с эвристикой инерции.
Чтобы отключить обнаружение сходимости на основе нормализованного изменения центров, установите tol в 0.0 (по умолчанию).
- max_no_improvementint, по умолчанию=10
Контроль ранней остановки на основе последовательного количества мини-пакетов, которые не дают улучшения сглаженной инерции.
Чтобы отключить обнаружение сходимости на основе инерции, установите max_no_improvement в None.
- init_sizeint, default=None
Количество образцов для случайной выборки с целью ускорения инициализации (иногда в ущерб точности): единственный алгоритм инициализируется запуском пакетного KMeans на случайном подмножестве данных. Это должно быть больше, чем n_clusters.
Если
None, эвристикаinit_size = 3 * batch_sizeif3 * batch_size < n_clusters, иначеinit_size = 3 * n_clusters.- n_init‘auto’ или int, по умолчанию="auto"
Количество случайных инициализаций, которые пробуются. В отличие от KMeans, алгоритм запускается только один раз, используя лучшую из
n_initинициализаций, измеренных по инерции. Для разреженных многомерных задач рекомендуется несколько запусков (см. Кластеризация разреженных данных с помощью k-средних).Когда
n_init='auto', количество запусков зависит от значения init: 3, если используетсяinit='random'илиinitявляется вызываемым объектом; 1, если используетсяinit='k-means++'илиinitявляется array-like.Добавлено в версии 1.2: Добавлена опция 'auto' для
n_init.Изменено в версии 1.4: Значение по умолчанию для
n_initизменено на'auto'в версии.- reassignment_ratiofloat, по умолчанию=0.01
Управление долей максимального количества подсчетов для центра, чтобы быть переназначенным. Более высокое значение означает, что центры с низким подсчетом легче переназначаются, что означает, что модель будет дольше сходиться, но должна сойтись к лучшей кластеризации. Однако слишком высокое значение может вызвать проблемы со сходимостью, особенно при небольшом размере пакета.
- Атрибуты:
- cluster_centers_ndarray формы (n_clusters, n_features)
Координаты центров кластеров.
- labels_ndarray формы (n_samples,)
Метки каждой точки (если compute_labels установлено в True).
- inertia_float
Значение критерия инерции, связанное с выбранным разбиением, если compute_labels установлен в True. Если compute_labels установлен в False, это приближение инерции на основе экспоненциально взвешенного среднего пакетных инерций. Инерция определяется как сумма квадратов расстояний выборок до их центров кластеров, взвешенная по весам выборок, если они предоставлены.
- n_iter_int
Количество итераций по полному набору данных.
- n_steps_int
Количество обработанных мини-пакетов.
Добавлено в версии 1.0.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
KMeansКлассическая реализация метода кластеризации на основе алгоритма Ллойда. Он потребляет весь набор входных данных на каждой итерации.
Примечания
См. https://www.eecs.tufts.edu/~dsculley/papers/fastkmeans.pdf
Когда в наборе данных слишком мало точек, некоторые центры могут дублироваться, что означает, что правильная кластеризация с точки зрения количества запрашиваемых кластеров и количества возвращаемых кластеров не всегда будет совпадать. Одно из решений - установить
reassignment_ratio=0, что предотвращает перераспределение кластеров, которые слишком малы.См. Сравнение BIRCH и MiniBatchKMeans для сравнения с
BIRCH.Примеры
>>> from sklearn.cluster import MiniBatchKMeans >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 0], [4, 4], ... [4, 5], [0, 1], [2, 2], ... [3, 2], [5, 5], [1, -1]]) >>> # manually fit on batches >>> kmeans = MiniBatchKMeans(n_clusters=2, ... random_state=0, ... batch_size=6, ... n_init="auto") >>> kmeans = kmeans.partial_fit(X[0:6,:]) >>> kmeans = kmeans.partial_fit(X[6:12,:]) >>> kmeans.cluster_centers_ array([[3.375, 3. ], [0.75 , 0.5 ]]) >>> kmeans.predict([[0, 0], [4, 4]]) array([1, 0], dtype=int32) >>> # fit on the whole data >>> kmeans = MiniBatchKMeans(n_clusters=2, ... random_state=0, ... batch_size=6, ... max_iter=10, ... n_init="auto").fit(X) >>> kmeans.cluster_centers_ array([[3.55102041, 2.48979592], [1.06896552, 1. ]]) >>> kmeans.predict([[0, 0], [4, 4]]) array([1, 0], dtype=int32)
Для сравнения кластеризации Mini-Batch K-Means с другими алгоритмами кластеризации, см. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
- fit(X, y=None, sample_weight=None)[источник]#
Вычислите центроиды на X, разбивая его на мини-пакеты.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие экземпляры для кластеризации. Следует отметить, что данные будут преобразованы в C-упорядоченный формат, что вызовет копирование в памяти, если предоставленные данные не являются C-непрерывными. Если передана разреженная матрица, будет создана копия, если она не в формате CSR.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
sample_weightне используется во время инициализации, еслиinitявляется вызываемым объектом или предоставленным пользователем массивом.Добавлено в версии 0.20.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_predict(X, y=None, sample_weight=None)[источник]#
Вычислить центры кластеров и предсказать индекс кластера для каждого образца.
Удобный метод; эквивалентен вызову fit(X) с последующим predict(X).
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- меткиndarray формы (n_samples,)
Индекс кластера, к которому принадлежит каждый образец.
- fit_transform(X, y=None, sample_weight=None)[источник]#
Выполнить кластеризацию и преобразовать X в пространство расстояний до кластеров.
Эквивалентно fit(X).transform(X), но реализовано более эффективно.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- X_newndarray формы (n_samples, n_clusters)
X преобразован в новое пространство.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y=None, sample_weight=None)[источник]#
Обновление оценки k-средних на одном мини-батче X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие экземпляры для кластеризации. Следует отметить, что данные будут преобразованы в C-упорядоченный формат, что вызовет копирование в памяти, если предоставленные данные не являются C-непрерывными. Если передана разреженная матрица, будет создана копия, если она не в формате CSR.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
sample_weightне используется во время инициализации, еслиinitявляется вызываемым объектом или предоставленным пользователем массивом.
- Возвращает:
- selfobject
Вернуть обновленный оценщик.
- predict(X)[источник]#
Предсказывает ближайший кластер, к которому принадлежит каждый образец в X.
В литературе по векторному квантованию,
cluster_centers_называется кодовая книга, и каждое значение, возвращаемоеpredictявляется индексом ближайшего кода в кодовой книге.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для предсказания.
- Возвращает:
- меткиndarray формы (n_samples,)
Индекс кластера, к которому принадлежит каждый образец.
- score(X, y=None, sample_weight=None)[источник]#
Противоположное значение X по целевой функции K-средних.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого наблюдения в X. Если None, всем наблюдениям присваивается равный вес.
- Возвращает:
- scorefloat
Противоположное значение X по целевой функции K-средних.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X)[источник]#
Преобразовать X в пространство расстояний до кластеров.
В новом пространстве каждое измерение — это расстояние до центров кластеров. Обратите внимание, что даже если X разрежен, массив, возвращаемый
transformобычно будет плотной.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для преобразования.
- Возвращает:
- X_newndarray формы (n_samples, n_clusters)
X преобразован в новое пространство.
Примеры галереи#

Бикластеризация документов с помощью алгоритма спектральной совместной кластеризации
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных

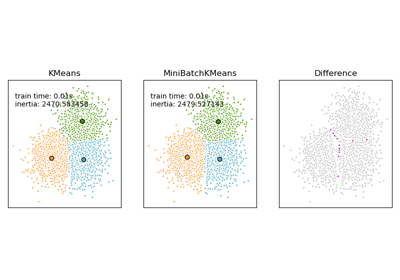
Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans

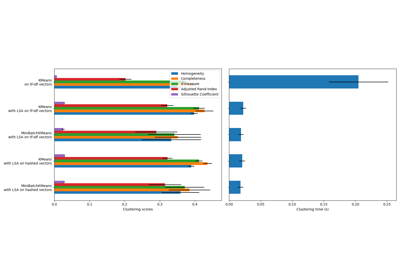
Кластеризация текстовых документов с использованием k-means