Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Представляем set_output API#
Этот пример продемонстрирует set_output API для настройки преобразователей на
вывод pandas DataFrames. set_output может быть настроен для каждого оценщика путем вызова
метода set_output методом или глобально, установив set_config(transform_output="pandas").
Подробности см. в
SLEP018.
Сначала мы загружаем набор данных iris как DataFrame, чтобы продемонстрировать set_output API.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
X_train.head()
Чтобы настроить оценщик, такой как preprocessing.StandardScaler для возврата
DataFrame, вызовите set_output. Эта функция требует установки pandas.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().set_output(transform="pandas")
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled.head()
set_output может быть вызван после fit для настройки transform после факта.
scaler2 = StandardScaler()
scaler2.fit(X_train)
X_test_np = scaler2.transform(X_test)
print(f"Default output type: {type(X_test_np).__name__}")
scaler2.set_output(transform="pandas")
X_test_df = scaler2.transform(X_test)
print(f"Configured pandas output type: {type(X_test_df).__name__}")
Default output type: ndarray
Configured pandas output type: DataFrame
В pipeline.Pipeline, set_output настраивает все шаги на вывод DataFrames.
from sklearn.feature_selection import SelectPercentile
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
clf = make_pipeline(
StandardScaler(), SelectPercentile(percentile=75), LogisticRegression()
)
clf.set_output(transform="pandas")
clf.fit(X_train, y_train)
Каждый трансформер в конвейере настроен на возврат DataFrames. Это означает, что финальный шаг логистической регрессии содержит имена признаков входных данных.
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
Примечание
Если использовать метод set_params, преобразователь будет заменен новым с форматом вывода по умолчанию.
clf.set_params(standardscaler=StandardScaler())
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['x0', 'x2', 'x3'], dtype=object)
Для сохранения ожидаемого поведения используйте set_output на новом преобразователе заранее
scaler = StandardScaler().set_output(transform="pandas")
clf.set_params(standardscaler=scaler)
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
Далее мы загружаем набор данных Titanic, чтобы продемонстрировать set_output с
compose.ColumnTransformer и разнородные данные.
from sklearn.datasets import fetch_openml
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
The set_output API может быть настроен глобально с помощью set_config и установка transform_output to "pandas".
from sklearn import set_config
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
set_config(transform_output="pandas")
num_pipe = make_pipeline(SimpleImputer(), StandardScaler())
num_cols = ["age", "fare"]
ct = ColumnTransformer(
(
("numerical", num_pipe, num_cols),
(
"categorical",
OneHotEncoder(
sparse_output=False, drop="if_binary", handle_unknown="ignore"
),
["embarked", "sex", "pclass"],
),
),
verbose_feature_names_out=False,
)
clf = make_pipeline(ct, SelectPercentile(percentile=50), LogisticRegression())
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
0.7621951219512195
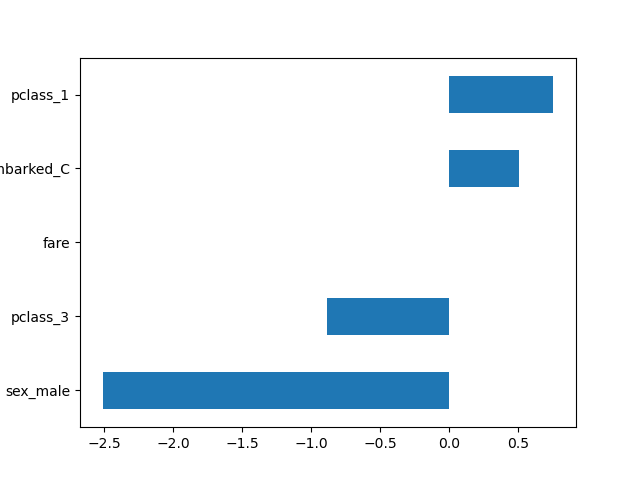
С глобальной конфигурацией все трансформеры выводят DataFrames. Это позволяет нам легко строить графики коэффициентов логистической регрессии с соответствующими именами признаков.
import pandas as pd
log_reg = clf[-1]
coef = pd.Series(log_reg.coef_.ravel(), index=log_reg.feature_names_in_)
_ = coef.sort_values().plot.barh()
Чтобы продемонстрировать config_context функциональность ниже, давайте
сначала сбросим transform_output к значению по умолчанию.
set_config(transform_output="default")
При настройке типа вывода с помощью config_context конфигурация в момент, когда transform или fit_transform вызываются - вот что имеет значение. Установка этих параметров только при создании или обучении трансформера не имеет эффекта.
from sklearn import config_context
scaler = StandardScaler()
scaler.fit(X_train[num_cols])
with config_context(transform_output="pandas"):
# the output of transform will be a Pandas DataFrame
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled.head()
вне контекстного менеджера вывод будет массивом NumPy
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled[:5]
array([[-0.04400864, -0.12532481],
[-0.88023923, -0.47146783],
[-1.71646982, -0.12479447],
[-0.04400864, -0.45625688],
[-0.67118158, -0.34289311]])
Общее время выполнения скрипта: (0 минут 0.127 секунд)
Связанные примеры