Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Полу-контролируемая классификация на текстовом наборе данных#
Этот пример демонстрирует эффективность полуконтролируемого обучения для классификации текста на TF-IDF признаки, когда размеченных данных
мало. Для этой цели мы сравниваем четыре различных подхода:
Обучение с учителем с использованием 100% меток в обучающем наборе (наилучший сценарий)
Использует
SGDClassifierс полным контролемПредставляет наилучшую возможную производительность при наличии большого количества размеченных данных
Обучение с учителем с использованием 20% меток в обучающей выборке (базовый уровень)
Та же модель, что и в наилучшем сценарии, но обученная на случайном подмножестве 20% размеченных обучающих данных
Показывает ухудшение производительности полностью контролируемой модели из-за ограниченных размеченных данных
SelfTrainingClassifier(полу-контролируемое)Использует 20% размеченных данных + 80% неразмеченных данных для обучения
Итеративно предсказывает метки для неразмеченных данных
Демонстрирует, как самообучение может улучшить производительность
LabelSpreading(полу-контролируемое)Использует 20% размеченных данных + 80% неразмеченных данных для обучения
Распространяет метки через многообразие данных
Показывает, как методы на основе графов могут использовать неразмеченные данные
Пример использует набор данных 20 newsgroups, фокусируясь на пяти категориях. Результаты демонстрируют, как полуконтролируемые методы могут достигать лучшей производительности, чем контролируемое обучение с ограниченными размеченными данными, эффективно используя неразмеченные образцы.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.semi_supervised import LabelSpreading, SelfTrainingClassifier
# Loading dataset containing first five categories
data = fetch_20newsgroups(
subset="train",
categories=[
"alt.atheism",
"comp.graphics",
"comp.os.ms-windows.misc",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
],
)
# Parameters
sdg_params = dict(alpha=1e-5, penalty="l2", loss="log_loss")
vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8)
# Supervised Pipeline
pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SGDClassifier(**sdg_params)),
]
)
# SelfTraining Pipeline
st_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SelfTrainingClassifier(SGDClassifier(**sdg_params))),
]
)
# LabelSpreading Pipeline
ls_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", LabelSpreading()),
]
)
def eval_and_get_f1(clf, X_train, y_train, X_test, y_test):
"""Evaluate model performance and return F1 score"""
print(f" Number of training samples: {len(X_train)}")
print(f" Unlabeled samples in training set: {sum(1 for x in y_train if x == -1)}")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
f1 = f1_score(y_test, y_pred, average="micro")
print(f" Micro-averaged F1 score on test set: {f1:.3f}")
print("\n")
return f1
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
1. Оценить контролируемый SGDClassifier, используя 100% размеченного обучающего набора. Это представляет наилучшую производительность, когда модель имеет полный доступ ко всем размеченным примерам.
f1_scores = {}
print("1. Supervised SGDClassifier on 100% of the data:")
f1_scores["Supervised (100%)"] = eval_and_get_f1(
pipeline, X_train, y_train, X_test, y_test
)
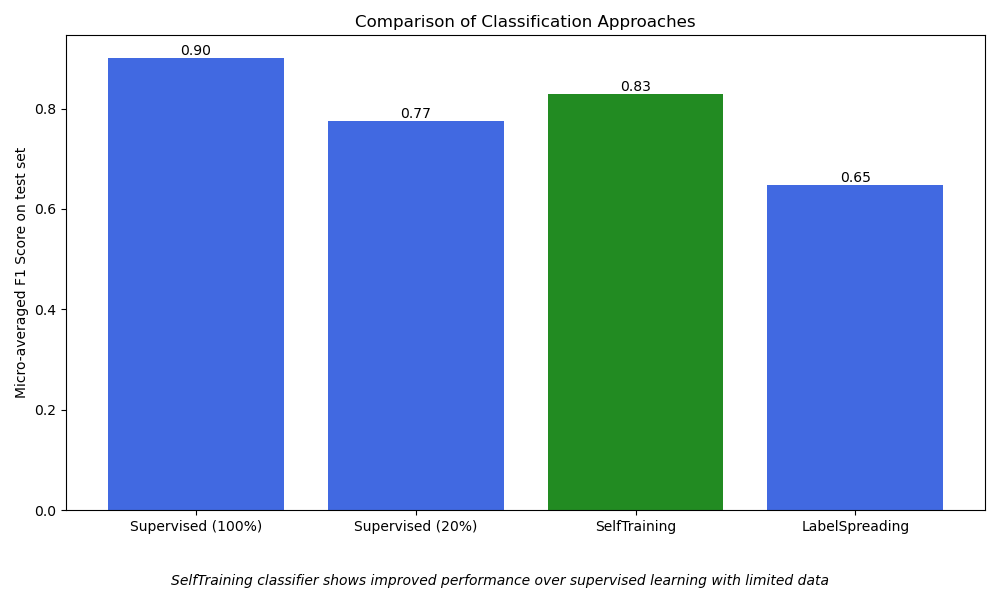
1. Supervised SGDClassifier on 100% of the data:
Number of training samples: 2117
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.901
2. Оцените обученный SGDClassifier с учителем на только 20% данных. Это служит базовой линией для иллюстрации снижения производительности из-за ограничения обучающих выборок.
import numpy as np
print("2. Supervised SGDClassifier on 20% of the training data:")
rng = np.random.default_rng(42)
y_mask = rng.random(len(y_train)) < 0.2
# X_20 and y_20 are the subset of the train dataset indicated by the mask
X_20, y_20 = map(list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m)))
f1_scores["Supervised (20%)"] = eval_and_get_f1(pipeline, X_20, y_20, X_test, y_test)
2. Supervised SGDClassifier on 20% of the training data:
Number of training samples: 434
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.775
3. Оцените полуконтролируемый SelfTrainingClassifier, используя 20% размеченных и 80% неразмеченных данных. Оставшиеся 80% меток обучения маскируются как неразмеченные (-1), позволяя модели итеративно маркировать и обучаться на них.
print(
"3. SelfTrainingClassifier (semi-supervised) using 20% labeled "
"+ 80% unlabeled data):"
)
y_train_semi = y_train.copy()
y_train_semi[~y_mask] = -1
f1_scores["SelfTraining"] = eval_and_get_f1(
st_pipeline, X_train, y_train_semi, X_test, y_test
)
3. SelfTrainingClassifier (semi-supervised) using 20% labeled + 80% unlabeled data):
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.829
4. Оцените полуконтролируемую модель LabelSpreading, используя 20% размеченных и 80% неразмеченных данных. Как и SelfTraining, модель выводит метки для неразмеченной части данных для улучшения производительности.
print("4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:")
f1_scores["LabelSpreading"] = eval_and_get_f1(
ls_pipeline, X_train, y_train_semi, X_test, y_test
)
4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.647
Построить результаты#
Визуализируйте производительность различных подходов классификации с помощью столбчатой диаграммы.
Это помогает сравнить, как каждый метод работает на основе микроусредненного f1_score.
Микроусреднение вычисляет метрики глобально по всем классам,
что дает единую общую меру производительности и позволяет справедливо сравнивать
различные подходы, даже при наличии дисбаланса классов.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
models = list(f1_scores.keys())
scores = list(f1_scores.values())
colors = ["royalblue", "royalblue", "forestgreen", "royalblue"]
bars = plt.bar(models, scores, color=colors)
plt.title("Comparison of Classification Approaches")
plt.ylabel("Micro-averaged F1 Score on test set")
plt.xticks()
for bar in bars:
height = bar.get_height()
plt.text(
bar.get_x() + bar.get_width() / 2.0,
height,
f"{height:.2f}",
ha="center",
va="bottom",
)
plt.figtext(
0.5,
0.02,
"SelfTraining classifier shows improved performance over "
"supervised learning with limited data",
ha="center",
va="bottom",
fontsize=10,
style="italic",
)
plt.tight_layout()
plt.subplots_adjust(bottom=0.15)
plt.show()
Общее время выполнения скрипта: (0 минут 5.164 секунд)
Связанные примеры
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris
Распространение меток на цифрах: Демонстрация производительности