Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Классификация текстовых документов с использованием разреженных признаков#
Это пример, показывающий, как scikit-learn можно использовать для классификации документов по темам с помощью Bag of Words approach. В этом примере используется разреженная матрица документ-термин с взвешиванием Tf-idf для кодирования признаков и демонстрируются различные классификаторы, которые могут эффективно работать с разреженными матрицами.
Для анализа документов через неконтролируемый подход обучения, см. пример скрипт Кластеризация текстовых документов с использованием k-means.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузка и векторизация текстового набора данных 20 newsgroups#
которая является индикатором для класса Текстовый набор данных 20 новостных групп, который включает около 18 000 постов новостных групп по 20 темам, разделенных на два подмножества: одно для обучения (или разработки) и другое для тестирования (или оценки производительности). Обратите внимание, что по умолчанию текстовые образцы содержат некоторую метаинформацию сообщения, такую как 'headers', 'footers' (сигнатуры) и 'quotes'
к другим постам. fetch_20newsgroups {array-like, sparse matrix} формы (n_samples_a, n_samples_a), если metric == "precomputed", или (n_samples_a, n_features) в противном случае remove для попытки удалить такую информацию, которая может сделать задачу классификации «слишком лёгкой». Это достигается с помощью простых эвристик, которые не являются ни совершенными, ни стандартными, поэтому по умолчанию отключены.
from time import time
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
def size_mb(docs):
return sum(len(s.encode("utf-8")) for s in docs) / 1e6
def load_dataset(verbose=False, remove=()):
"""Load and vectorize the 20 newsgroups dataset."""
data_train = fetch_20newsgroups(
subset="train",
categories=categories,
shuffle=True,
random_state=42,
remove=remove,
)
data_test = fetch_20newsgroups(
subset="test",
categories=categories,
shuffle=True,
random_state=42,
remove=remove,
)
# order of labels in `target_names` can be different from `categories`
target_names = data_train.target_names
# split target in a training set and a test set
y_train, y_test = data_train.target, data_test.target
# Extracting features from the training data using a sparse vectorizer
t0 = time()
vectorizer = TfidfVectorizer(
sublinear_tf=True, max_df=0.5, min_df=5, stop_words="english"
)
X_train = vectorizer.fit_transform(data_train.data)
duration_train = time() - t0
# Extracting features from the test data using the same vectorizer
t0 = time()
X_test = vectorizer.transform(data_test.data)
duration_test = time() - t0
feature_names = vectorizer.get_feature_names_out()
if verbose:
# compute size of loaded data
data_train_size_mb = size_mb(data_train.data)
data_test_size_mb = size_mb(data_test.data)
print(
f"{len(data_train.data)} documents - "
f"{data_train_size_mb:.2f}MB (training set)"
)
print(f"{len(data_test.data)} documents - {data_test_size_mb:.2f}MB (test set)")
print(f"{len(target_names)} categories")
print(
f"vectorize training done in {duration_train:.3f}s "
f"at {data_train_size_mb / duration_train:.3f}MB/s"
)
print(f"n_samples: {X_train.shape[0]}, n_features: {X_train.shape[1]}")
print(
f"vectorize testing done in {duration_test:.3f}s "
f"at {data_test_size_mb / duration_test:.3f}MB/s"
)
print(f"n_samples: {X_test.shape[0]}, n_features: {X_test.shape[1]}")
return X_train, X_test, y_train, y_test, feature_names, target_names
Анализ классификатора документов на основе мешка слов#
Теперь мы обучим классификатор дважды: один раз на текстовых выборках, включая метаданные, и один раз после удаления метаданных. В обоих случаях мы проанализируем ошибки классификации на тестовом наборе с использованием матрицы ошибок и исследуем коэффициенты, определяющие функцию классификации обученных моделей.
Модель без удаления метаданных#
Мы начинаем с использования пользовательской функции load_dataset для загрузки данных без
удаления метаданных.
X_train, X_test, y_train, y_test, feature_names, target_names = load_dataset(
verbose=True
)
2034 documents - 3.98MB (training set)
1353 documents - 2.87MB (test set)
4 categories
vectorize training done in 0.344s at 11.577MB/s
n_samples: 2034, n_features: 7831
vectorize testing done in 0.222s at 12.907MB/s
n_samples: 1353, n_features: 7831
Наша первая модель является экземпляром
RidgeClassifier класс. Это линейная модель классификации, которая использует среднеквадратичную ошибку на целях, закодированных как {-1, 1}, по одному для каждого возможного класса. В отличие от
LogisticRegression,
RidgeClassifier не предоставляет вероятностные предсказания (нет predict_proba метод),
но часто обучение происходит быстрее.
from sklearn.linear_model import RidgeClassifier
clf = RidgeClassifier(tol=1e-2, solver="sparse_cg")
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
Мы строим матрицу ошибок этого классификатора, чтобы выяснить, есть ли закономерность в ошибках классификации.
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
fig, ax = plt.subplots(figsize=(10, 5))
ConfusionMatrixDisplay.from_predictions(y_test, pred, ax=ax)
ax.xaxis.set_ticklabels(target_names)
ax.yaxis.set_ticklabels(target_names)
_ = ax.set_title(
f"Confusion Matrix for {clf.__class__.__name__}\non the original documents"
)
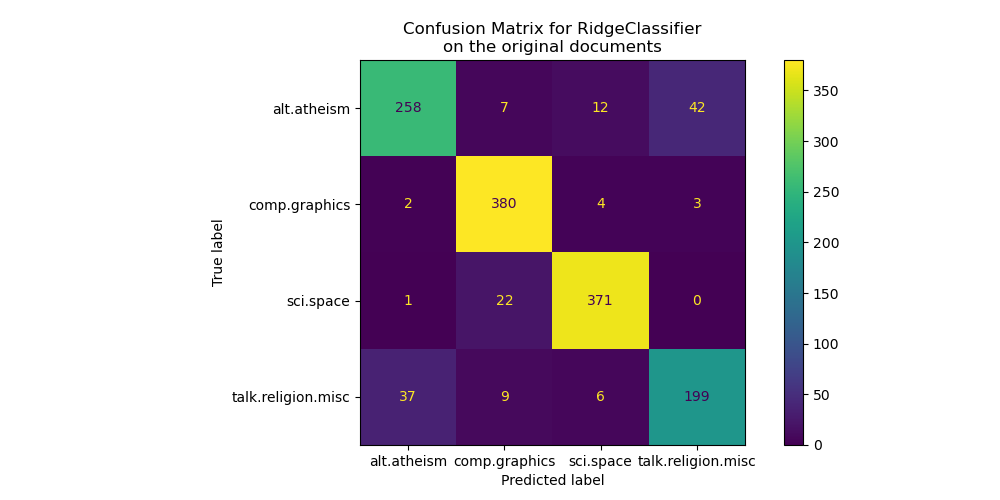
Матрица ошибок показывает, что документы alt.atheism класс часто путают с документами класса talk.religion.misc класс и
наоборот, что ожидаемо, поскольку темы семантически связаны.
Мы также наблюдаем, что некоторые документы sci.space класс может быть ошибочно классифицирован как
comp.graphics в то время как обратное встречается гораздо реже. Ручная проверка этих
плохо классифицированных документов потребуется для получения информации об этой
асимметрии. Возможно, что словарь темы космоса может
быть более специфичным, чем словарь для компьютерной графики.
Мы можем получить более глубокое понимание того, как этот классификатор принимает решения, посмотрев на слова с наибольшим средним влиянием признаков:
import numpy as np
import pandas as pd
def plot_feature_effects():
# learned coefficients weighted by frequency of appearance
average_feature_effects = clf.coef_ * np.asarray(X_train.mean(axis=0)).ravel()
for i, label in enumerate(target_names):
top5 = np.argsort(average_feature_effects[i])[-5:][::-1]
if i == 0:
top = pd.DataFrame(feature_names[top5], columns=[label])
top_indices = top5
else:
top[label] = feature_names[top5]
top_indices = np.concatenate((top_indices, top5), axis=None)
top_indices = np.unique(top_indices)
predictive_words = feature_names[top_indices]
# plot feature effects
bar_size = 0.25
padding = 0.75
y_locs = np.arange(len(top_indices)) * (4 * bar_size + padding)
fig, ax = plt.subplots(figsize=(10, 8))
for i, label in enumerate(target_names):
ax.barh(
y_locs + (i - 2) * bar_size,
average_feature_effects[i, top_indices],
height=bar_size,
label=label,
)
ax.set(
yticks=y_locs,
yticklabels=predictive_words,
ylim=[
0 - 4 * bar_size,
len(top_indices) * (4 * bar_size + padding) - 4 * bar_size,
],
)
ax.legend(loc="lower right")
print("top 5 keywords per class:")
print(top)
return ax
_ = plot_feature_effects().set_title("Average feature effect on the original data")
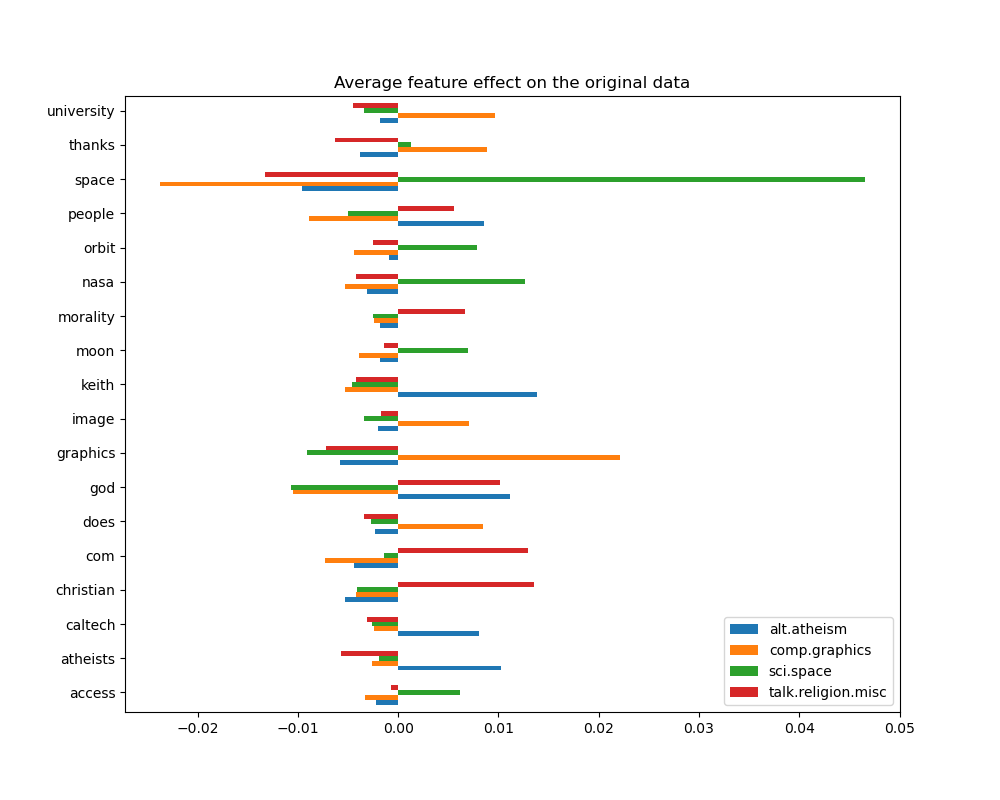
top 5 keywords per class:
alt.atheism comp.graphics sci.space talk.religion.misc
0 keith graphics space christian
1 god university nasa com
2 atheists thanks orbit god
3 people does moon morality
4 caltech image access people
Мы можем наблюдать, что наиболее предсказательные слова часто сильно положительно
связаны с одним классом и отрицательно связаны со всеми другими
классами. Большинство этих положительных связей довольно легко интерпретировать.
Однако некоторые слова, такие как "god" и "people" положительно связаны с
обоими "talk.misc.religion" и "alt.atheism" поскольку эти два класса, как ожидается,
имеют некоторую общую лексику. Однако обратите внимание, что есть также слова, такие как
"christian" и "morality" которые только положительно связаны с
"talk.misc.religion". Кроме того, в этой версии набора данных слово
"caltech" является одним из лучших прогнозных признаков для атеизма из-за загрязнения
в наборе данных, происходящего от какого-то метаданных, таких как адреса электронной почты
отправителя предыдущих писем в обсуждении, как видно ниже:
data_train = fetch_20newsgroups(
subset="train", categories=categories, shuffle=True, random_state=42
)
for doc in data_train.data:
if "caltech" in doc:
print(doc)
break
From: livesey@solntze.wpd.sgi.com (Jon Livesey)
Subject: Re: Morality? (was Re: , keith@cco.caltech.edu (Keith Allan Schneider) writes:
|> livesey@solntze.wpd.sgi.com (Jon Livesey) writes:
|>
|> >>>Explain to me
|> >>>how instinctive acts can be moral acts, and I am happy to listen.
|> >>For example, if it were instinctive not to murder...
|> >
|> >Then not murdering would have no moral significance, since there
|> >would be nothing voluntary about it.
|>
|> See, there you go again, saying that a moral act is only significant
|> if it is "voluntary." Why do you think this?
If you force me to do something, am I morally responsible for it?
|>
|> And anyway, humans have the ability to disregard some of their instincts.
Well, make up your mind. Is it to be "instinctive not to murder"
or not?
|>
|> >>So, only intelligent beings can be moral, even if the bahavior of other
|> >>beings mimics theirs?
|> >
|> >You are starting to get the point. Mimicry is not necessarily the
|> >same as the action being imitated. A Parrot saying "Pretty Polly"
|> >isn't necessarily commenting on the pulchritude of Polly.
|>
|> You are attaching too many things to the term "moral," I think.
|> Let's try this: is it "good" that animals of the same species
|> don't kill each other. Or, do you think this is right?
It's not even correct. Animals of the same species do kill
one another.
|>
|> Or do you think that animals are machines, and that nothing they do
|> is either right nor wrong?
Sigh. I wonder how many times we have been round this loop.
I think that instinctive bahaviour has no moral significance.
I am quite prepared to believe that higher animals, such as
primates, have the beginnings of a moral sense, since they seem
to exhibit self-awareness.
|>
|>
|> >>Animals of the same species could kill each other arbitarily, but
|> >>they don't.
|> >
|> >They do. I and other posters have given you many examples of exactly
|> >this, but you seem to have a very short memory.
|>
|> Those weren't arbitrary killings. They were slayings related to some
|> sort of mating ritual or whatnot.
So what? Are you trying to say that some killing in animals
has a moral significance and some does not? Is this your
natural morality>
|>
|> >>Are you trying to say that this isn't an act of morality because
|> >>most animals aren't intelligent enough to think like we do?
|> >
|> >I'm saying:
|> > "There must be the possibility that the organism - it's not
|> > just people we are talking about - can consider alternatives."
|> >
|> >It's right there in the posting you are replying to.
|>
|> Yes it was, but I still don't understand your distinctions. What
|> do you mean by "consider?" Can a small child be moral? How about
|> a gorilla? A dolphin? A platypus? Where is the line drawn? Does
|> the being need to be self aware?
Are you blind? What do you think that this sentence means?
"There must be the possibility that the organism - it's not
just people we are talking about - can consider alternatives."
What would that imply?
|>
|> What *do* you call the mechanism which seems to prevent animals of
|> the same species from (arbitrarily) killing each other? Don't
|> you find the fact that they don't at all significant?
I find the fact that they do to be significant.
jon.
Такие заголовки, подписи внизу (и цитируемые метаданные из предыдущих сообщений) можно рассматривать как побочную информацию, которая искусственно раскрывает новостную группу, идентифицируя зарегистрированных участников, и хотелось бы, чтобы наш классификатор текста обучался только на «основном содержании» каждого текстового документа, а не полагался на раскрытую идентификацию авторов.
Модель с удалением метаданных#
The remove опция загрузчика набора данных 20 newsgroups в scikit-learn позволяет
эвристически пытаться отфильтровать часть нежелательных метаданных, которые
делают задачу классификации искусственно проще. Учтите, что такая
фильтрация текстового содержимого далека от совершенства.
Попробуем использовать эту опцию для обучения текстового классификатора, который не слишком полагается на этот вид метаданных для принятия решений:
(
X_train,
X_test,
y_train,
y_test,
feature_names,
target_names,
) = load_dataset(remove=("headers", "footers", "quotes"))
clf = RidgeClassifier(tol=1e-2, solver="sparse_cg")
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
fig, ax = plt.subplots(figsize=(10, 5))
ConfusionMatrixDisplay.from_predictions(y_test, pred, ax=ax)
ax.xaxis.set_ticklabels(target_names)
ax.yaxis.set_ticklabels(target_names)
_ = ax.set_title(
f"Confusion Matrix for {clf.__class__.__name__}\non filtered documents"
)
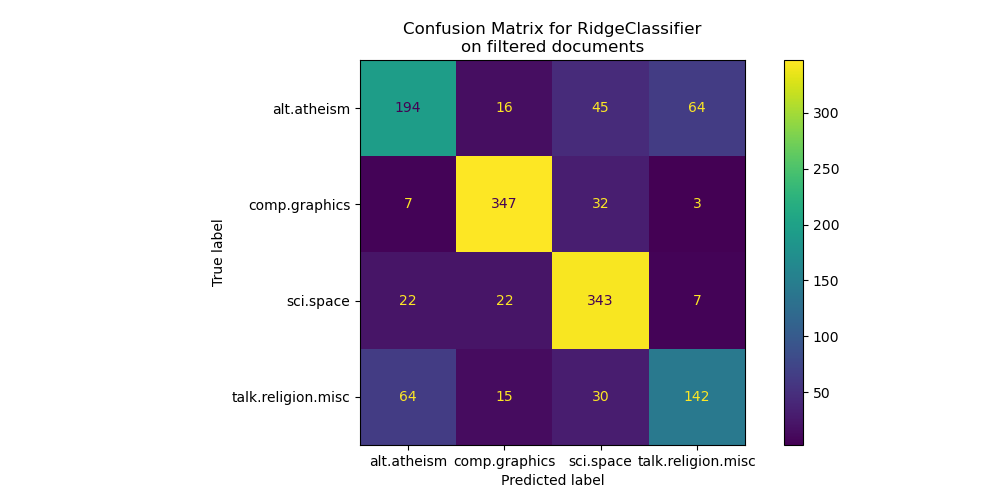
Глядя на матрицу ошибок, становится более очевидным, что оценки модели, обученной с метаданными, были излишне оптимистичными. Задача классификации без доступа к метаданным менее точна, но более репрезентативна для предполагаемой задачи классификации текста.
_ = plot_feature_effects().set_title("Average feature effects on filtered documents")
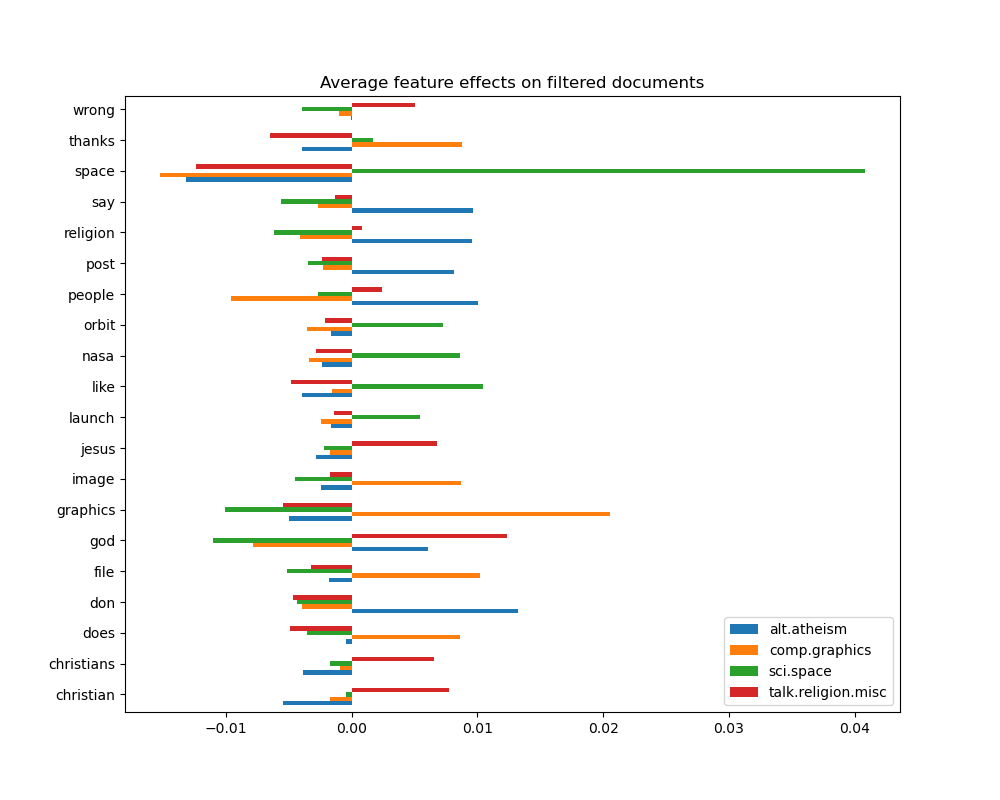
top 5 keywords per class:
alt.atheism comp.graphics sci.space talk.religion.misc
0 don graphics space god
1 people file like christian
2 say thanks nasa jesus
3 religion image orbit christians
4 post does launch wrong
В следующем разделе мы оставляем набор данных без метаданных для сравнения нескольких классификаторов.
Бенчмаркинг классификаторов#
Scikit-learn предоставляет множество различных алгоритмов классификации. В этом разделе мы обучим выбор этих классификаторов на одной и той же задаче классификации текста и измерим как их обобщающую производительность (точность на тестовом наборе), так и вычислительную производительность (скорость) как во время обучения, так и во время тестирования. Для этой цели мы определяем следующие утилиты бенчмаркинга:
from sklearn import metrics
from sklearn.utils.extmath import density
def benchmark(clf, custom_name=False):
print("_" * 80)
print("Training: ")
print(clf)
t0 = time()
clf.fit(X_train, y_train)
train_time = time() - t0
print(f"train time: {train_time:.3}s")
t0 = time()
pred = clf.predict(X_test)
test_time = time() - t0
print(f"test time: {test_time:.3}s")
score = metrics.accuracy_score(y_test, pred)
print(f"accuracy: {score:.3}")
if hasattr(clf, "coef_"):
print(f"dimensionality: {clf.coef_.shape[1]}")
print(f"density: {density(clf.coef_)}")
print()
print()
if custom_name:
clf_descr = str(custom_name)
else:
clf_descr = clf.__class__.__name__
return clf_descr, score, train_time, test_time
Теперь мы обучаем и тестируем наборы данных с 8 различными моделями классификации и получаем результаты производительности для каждой модели. Цель этого исследования — подчеркнуть компромиссы между вычислительной сложностью и точностью различных типов классификаторов для такой многоклассовой задачи классификации текстов.
Обратите внимание, что наиболее важные значения гиперпараметров были настроены с помощью процедуры поиска по сетке, не показанной в этой записной книжке для простоты. Смотрите пример скрипта Примерный пайплайн для извлечения и оценки текстовых признаков для демонстрации того, как можно выполнить такую настройку.
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.naive_bayes import ComplementNB
from sklearn.neighbors import KNeighborsClassifier, NearestCentroid
from sklearn.svm import LinearSVC
results = []
for clf, name in (
(LogisticRegression(C=5, max_iter=1000), "Logistic Regression"),
(RidgeClassifier(alpha=1.0, solver="sparse_cg"), "Ridge Classifier"),
(KNeighborsClassifier(n_neighbors=100), "kNN"),
(RandomForestClassifier(), "Random Forest"),
# L2 penalty Linear SVC
(LinearSVC(C=0.1, dual=False, max_iter=1000), "Linear SVC"),
# L2 penalty Linear SGD
(
SGDClassifier(
loss="log_loss", alpha=1e-4, n_iter_no_change=3, early_stopping=True
),
"log-loss SGD",
),
# NearestCentroid (aka Rocchio classifier)
(NearestCentroid(), "NearestCentroid"),
# Sparse naive Bayes classifier
(ComplementNB(alpha=0.1), "Complement naive Bayes"),
):
print("=" * 80)
print(name)
results.append(benchmark(clf, name))
================================================================================
Logistic Regression
________________________________________________________________________________
Training:
LogisticRegression(C=5, max_iter=1000)
train time: 0.196s
test time: 0.000608s
accuracy: 0.772
dimensionality: 5316
density: 1.0
================================================================================
Ridge Classifier
________________________________________________________________________________
Training:
RidgeClassifier(solver='sparse_cg')
train time: 0.0297s
test time: 0.00057s
accuracy: 0.76
dimensionality: 5316
density: 1.0
================================================================================
kNN
________________________________________________________________________________
Training:
KNeighborsClassifier(n_neighbors=100)
train time: 0.000942s
test time: 0.0373s
accuracy: 0.752
================================================================================
Random Forest
________________________________________________________________________________
Training:
RandomForestClassifier()
train time: 1.59s
test time: 0.0638s
accuracy: 0.7
================================================================================
Linear SVC
________________________________________________________________________________
Training:
LinearSVC(C=0.1, dual=False)
train time: 0.0303s
test time: 0.000609s
accuracy: 0.752
dimensionality: 5316
density: 1.0
================================================================================
log-loss SGD
________________________________________________________________________________
Training:
SGDClassifier(early_stopping=True, loss='log_loss', n_iter_no_change=3)
train time: 0.0347s
test time: 0.00058s
accuracy: 0.764
dimensionality: 5316
density: 1.0
================================================================================
NearestCentroid
________________________________________________________________________________
Training:
NearestCentroid()
train time: 0.158s
test time: 0.00156s
accuracy: 0.748
================================================================================
Complement naive Bayes
________________________________________________________________________________
Training:
ComplementNB(alpha=0.1)
train time: 0.00218s
test time: 0.000543s
accuracy: 0.779
Построить график точности, времени обучения и тестирования каждого классификатора#
Диаграммы рассеяния показывают компромисс между точностью тестирования и временем обучения и тестирования каждого классификатора.
indices = np.arange(len(results))
results = [[x[i] for x in results] for i in range(4)]
clf_names, score, training_time, test_time = results
training_time = np.array(training_time)
test_time = np.array(test_time)
fig, ax1 = plt.subplots(figsize=(10, 8))
ax1.scatter(score, training_time, s=60)
ax1.set(
title="Score-training time trade-off",
yscale="log",
xlabel="test accuracy",
ylabel="training time (s)",
)
fig, ax2 = plt.subplots(figsize=(10, 8))
ax2.scatter(score, test_time, s=60)
ax2.set(
title="Score-test time trade-off",
yscale="log",
xlabel="test accuracy",
ylabel="test time (s)",
)
for i, txt in enumerate(clf_names):
ax1.annotate(txt, (score[i], training_time[i]))
ax2.annotate(txt, (score[i], test_time[i]))
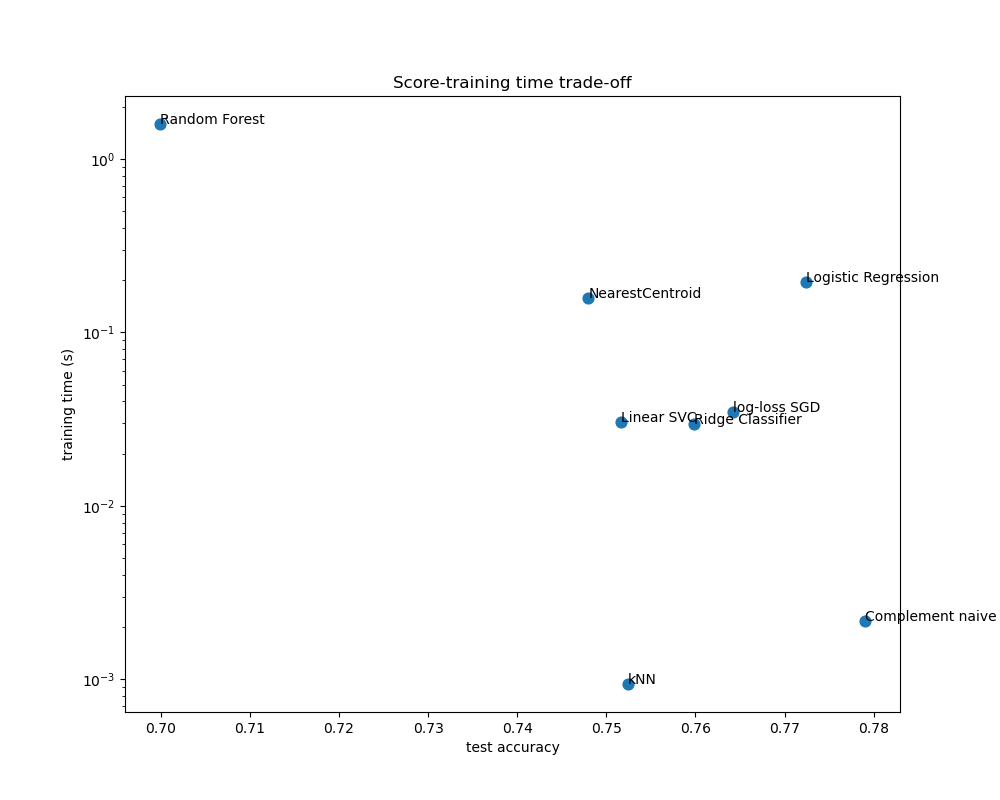
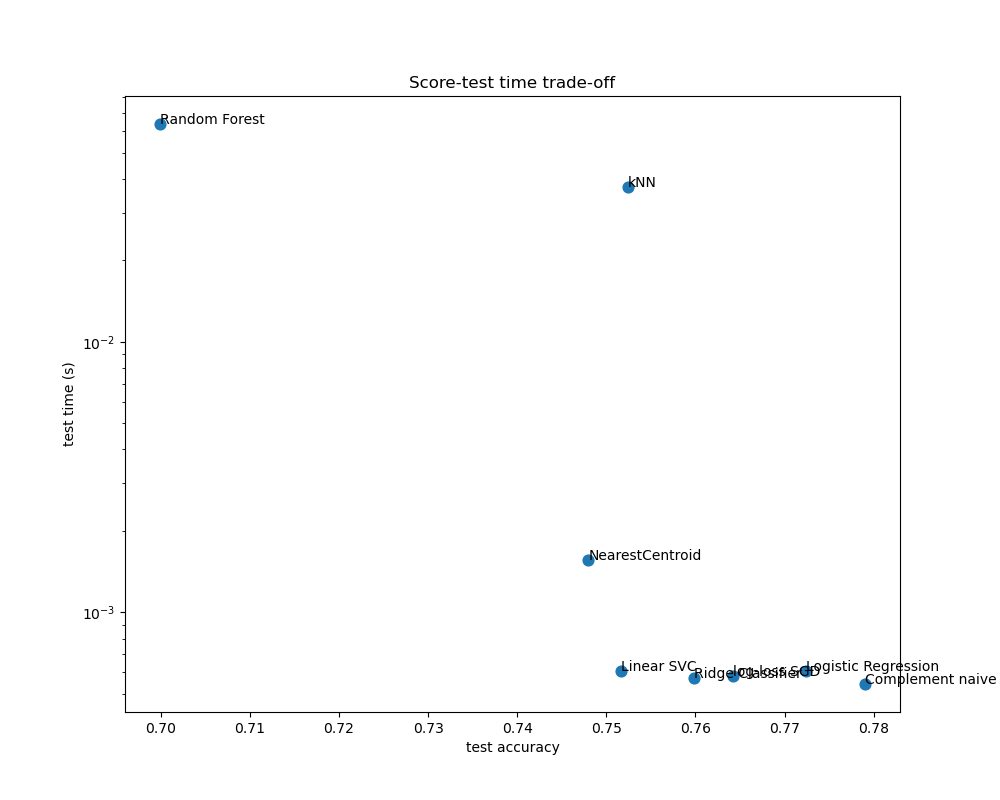
Наивная байесовская модель имеет наилучший компромисс между оценкой и временем обучения/тестирования, в то время как Random Forest медленно обучается, требует больших затрат на предсказание и имеет сравнительно низкую точность. Это ожидаемо: для задач прогнозирования высокой размерности линейные модели часто лучше подходят, так как большинство проблем становятся линейно разделимыми, когда пространство признаков имеет 10 000 измерений или более.
Разница в скорости обучения и точности линейных моделей может быть объяснена выбором функции потерь, которую они оптимизируют, и типом регуляризации, которую они используют. Учтите, что некоторые линейные модели с той же функцией потерь, но с другим решателем или конфигурацией регуляризации могут давать разное время подгонки и точность тестирования. Мы можем наблюдать на втором графике, что после обучения все линейные модели имеют примерно одинаковую скорость предсказания, что ожидаемо, потому что все они реализуют одну и ту же функцию предсказания.
KNeighborsClassifier имеет относительно низкую точность и самое большое время тестирования. Длительное время предсказания также ожидаемо: для каждого предсказания модель должна вычислять попарные расстояния между тестовым образцом и каждым документом в обучающем наборе, что вычислительно затратно. Более того, «проклятие размерности» снижает способность этой модели достигать конкурентоспособной точности в высокоразмерном пространстве признаков задач классификации текста.
Общее время выполнения скрипта: (0 минут 6.393 секунды)
Связанные примеры

Примерный пайплайн для извлечения и оценки текстовых признаков

Бикластеризация документов с помощью алгоритма спектральной совместной кластеризации
Кластеризация текстовых документов с использованием k-means
