Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Выбор уменьшения размерности с помощью Pipeline и GridSearchCV#
Этот пример строит конвейер, который выполняет уменьшение размерности, за которым следует предсказание с классификатором на основе метода опорных векторов. Он демонстрирует использование GridSearchCV и
Pipeline для оптимизации по различным классам оценщиков в одном запуске CV – неконтролируемый PCA и NMF снижения размерности
сравниваются с одномерным отбором признаков во время
поиска по сетке.
Дополнительно, Pipeline может быть создан с помощью memory
аргумент для мемоизации трансформеров внутри конвейера, избегая повторного
обучения одних и тех же трансформеров снова и снова.
Обратите внимание, что использование memory для включения кэширования становится интересным, когда обучение преобразователя является затратным.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Иллюстрация Pipeline и GridSearchCV#
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import NMF, PCA
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
X, y = load_digits(return_X_y=True)
pipe = Pipeline(
[
("scaling", MinMaxScaler()),
# the reduce_dim stage is populated by the param_grid
("reduce_dim", "passthrough"),
("classify", LinearSVC(dual=False, max_iter=10000)),
]
)
N_FEATURES_OPTIONS = [2, 4, 8]
C_OPTIONS = [1, 10, 100, 1000]
param_grid = [
{
"reduce_dim": [PCA(iterated_power=7), NMF(max_iter=1_000)],
"reduce_dim__n_components": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
{
"reduce_dim": [SelectKBest(mutual_info_classif)],
"reduce_dim__k": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
]
reducer_labels = ["PCA", "NMF", "KBest(mutual_info_classif)"]
grid = GridSearchCV(pipe, n_jobs=1, param_grid=param_grid)
grid.fit(X, y)
import pandas as pd
mean_scores = np.array(grid.cv_results_["mean_test_score"])
# scores are in the order of param_grid iteration, which is alphabetical
mean_scores = mean_scores.reshape(len(C_OPTIONS), -1, len(N_FEATURES_OPTIONS))
# select score for best C
mean_scores = mean_scores.max(axis=0)
# create a dataframe to ease plotting
mean_scores = pd.DataFrame(
mean_scores.T, index=N_FEATURES_OPTIONS, columns=reducer_labels
)
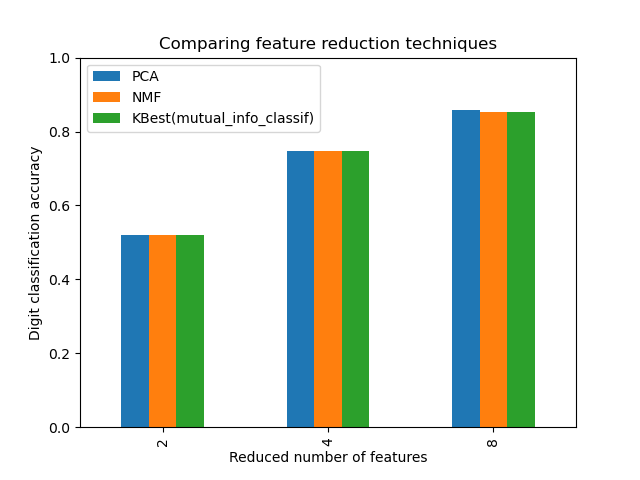
ax = mean_scores.plot.bar()
ax.set_title("Comparing feature reduction techniques")
ax.set_xlabel("Reduced number of features")
ax.set_ylabel("Digit classification accuracy")
ax.set_ylim((0, 1))
ax.legend(loc="upper left")
plt.show()
Кэширование преобразователей внутри Pipeline#
Иногда полезно сохранять состояние конкретного преобразователя,
поскольку его можно использовать снова. Использование конвейера в GridSearchCV вызывает такие ситуации. Поэтому мы используем аргумент memory чтобы включить кэширование.
Предупреждение
Обратите внимание, что этот пример, однако, является лишь иллюстрацией, поскольку для этого
конкретного случая подгонка PCA не обязательно медленнее, чем загрузка
кэша. Поэтому используйте memory параметр конструктора при дорогостоящем обучении
трансформатора.
from shutil import rmtree
from joblib import Memory
# Create a temporary folder to store the transformers of the pipeline
location = "cachedir"
memory = Memory(location=location, verbose=10)
cached_pipe = Pipeline(
[("reduce_dim", PCA()), ("classify", LinearSVC(dual=False, max_iter=10000))],
memory=memory,
)
# This time, a cached pipeline will be used within the grid search
# Delete the temporary cache before exiting
memory.clear(warn=False)
rmtree(location)
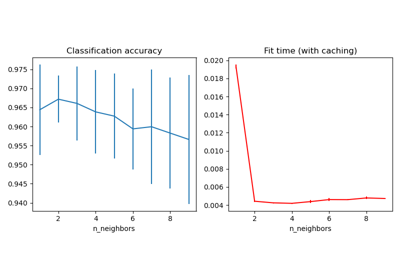
The PCA обучение вычисляется только при оценке первой
конфигурации C параметр LinearSVC классификатор. Другие
конфигурации C вызовет загрузку кэшированного PCA
данные оценщика, что позволяет сэкономить время обработки. Поэтому использование
кэширования конвейера с помощью memory очень полезно, когда подгонка трансформера затратна.
Общее время выполнения скрипта: (0 минут 43.733 секунды)
Связанные примеры


Объединение нескольких методов извлечения признаков