Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Последующая настройка порога принятия решений для обучения с учетом стоимости#
После обучения классификатора выход predict метод выводит предсказания меток классов, соответствующие пороговой обработке либо decision_function или predict_proba выход. Для бинарного классификатора порог по умолчанию определяется как оценка апостериорной вероятности 0,5 или оценка решения 0,0.
Однако эта стратегия по умолчанию, скорее всего, не оптимальна для поставленной задачи. Здесь мы используем набор данных "Statlog" по немецким кредитам [1] для иллюстрации примера использования. В этом наборе данных задача состоит в том, чтобы предсказать, имеет ли человек «хороший» или «плохой» кредит. Кроме того, предоставляется матрица затрат, которая определяет стоимость ошибочной классификации. В частности, ошибочная классификация «плохого» кредита как «хорошего» в среднем в пять раз дороже, чем ошибочная классификация «хорошего» кредита как «плохого».
Мы используем TunedThresholdClassifierCV для выбора точки отсечения функции принятия решений, которая минимизирует предоставленную бизнес-стоимость.
Во второй части примера мы дополнительно расширяем этот подход, рассматривая задачу обнаружения мошенничества в транзакциях по кредитным картам: в этом случае бизнес-метрика зависит от суммы каждой отдельной транзакции.
Ссылки
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Обучение с учетом затрат с постоянными выгодами и издержками#
В этом первом разделе мы иллюстрируем использование
TunedThresholdClassifierCV в условиях обучения с учетом стоимости, когда выигрыши и затраты, связанные с каждой записью матрицы ошибок, постоянны. Мы используем проблематику, представленную в [2] используя набор данных "Statlog" по немецким кредитам [1].
Набор данных "Statlog" по кредитам в Германии#
Мы загружаем набор данных German credit из OpenML.
import sklearn
from sklearn.datasets import fetch_openml
sklearn.set_config(transform_output="pandas")
german_credit = fetch_openml(data_id=31, as_frame=True, parser="pandas")
X, y = german_credit.data, german_credit.target
Мы проверяем типы признаков, доступные в X.
X.info()
RangeIndex: 1000 entries, 0 to 999
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 checking_status 1000 non-null category
1 duration 1000 non-null int64
2 credit_history 1000 non-null category
3 purpose 1000 non-null category
4 credit_amount 1000 non-null int64
5 savings_status 1000 non-null category
6 employment 1000 non-null category
7 installment_commitment 1000 non-null int64
8 personal_status 1000 non-null category
9 other_parties 1000 non-null category
10 residence_since 1000 non-null int64
11 property_magnitude 1000 non-null category
12 age 1000 non-null int64
13 other_payment_plans 1000 non-null category
14 housing 1000 non-null category
15 existing_credits 1000 non-null int64
16 job 1000 non-null category
17 num_dependents 1000 non-null int64
18 own_telephone 1000 non-null category
19 foreign_worker 1000 non-null category
dtypes: category(13), int64(7)
memory usage: 69.9 KB
Многие признаки являются категориальными и обычно закодированы строками. Нам нужно закодировать эти категории при разработке нашей прогнозной модели. Проверим целевые переменные.
y.value_counts()
class
good 700
bad 300
Name: count, dtype: int64
Еще одно наблюдение заключается в том, что набор данных несбалансирован. Нам нужно быть осторожными при оценке нашей прогнозной модели и использовать семейство метрик, адаптированных к этой ситуации.
Кроме того, мы наблюдаем, что целевая переменная закодирована строкой. Некоторые метрики (например, точность и полнота) требуют указания метки интереса, также называемой 'положительной меткой'. Здесь мы определяем, что наша цель - предсказать, является ли выборка 'плохим' кредитом.
pos_label, neg_label = "bad", "good"
Для проведения анализа мы разделяем наш набор данных с помощью одного стратифицированного разбиения.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
Мы готовы разработать нашу прогнозную модель и соответствующую стратегию оценки.
Метрики оценки#
В этом разделе мы определяем набор метрик, которые будем использовать далее. Чтобы увидеть эффект настройки точки отсечения, мы оцениваем прогностическую модель с использованием кривой ROC (Receiver Operating Characteristic) и кривой Precision-Recall. Значения, указанные на этих графиках, - это истинно положительная частота (TPR), также известная как полнота или чувствительность, и ложноположительная частота (FPR), также известная как специфичность, для кривой ROC, а также точность и полнота для кривой Precision-Recall.
Из этих четырех метрик scikit-learn не предоставляет оценщик для FPR. Поэтому нам нужно определить небольшую пользовательскую функцию для его вычисления.
from sklearn.metrics import confusion_matrix
def fpr_score(y, y_pred, neg_label, pos_label):
cm = confusion_matrix(y, y_pred, labels=[neg_label, pos_label])
tn, fp, _, _ = cm.ravel()
tnr = tn / (tn + fp)
return 1 - tnr
Эта обученная модель не точна. Действительно, мы не установили параметры ядра и вместо этого использовали значения по умолчанию. Мы можем их проверить.
Поэтому нам нужно определить оценщик scikit-learn с помощью
make_scorer куда передается информация. Мы храним все
пользовательские скореры в словаре. Чтобы использовать их, нам нужно передать обученную модель,
данные и целевую переменную, на которой мы хотим оценить прогностическую модель.
from sklearn.metrics import make_scorer, precision_score, recall_score
tpr_score = recall_score # TPR and recall are the same metric
scoring = {
"precision": make_scorer(precision_score, pos_label=pos_label),
"recall": make_scorer(recall_score, pos_label=pos_label),
"fpr": make_scorer(fpr_score, neg_label=neg_label, pos_label=pos_label),
"tpr": make_scorer(tpr_score, pos_label=pos_label),
}
Кроме того, оригинальное исследование [1] определяет пользовательскую бизнес-метрику. Мы называем "бизнес-метрикой" любую метрическую функцию, которая направлена на количественную оценку того, как предсказания (правильные или ошибочные) могут повлиять на бизнес-ценность развертывания данной модели машинного обучения в конкретном контексте приложения. Для нашей задачи предсказания кредитоспособности авторы предоставляют пользовательскую матрицу затрат, которая кодирует, что классификация "плохого" кредита как "хорошего" в среднем в 5 раз дороже, чем наоборот: для финансового учреждения менее затратно не предоставить кредит потенциальному клиенту, который не допустит дефолта (и, следовательно, упустить хорошего клиента, который в противном случае и вернул бы кредит, и выплатил проценты), чем предоставить кредит клиенту, который допустит дефолт.
Мы определяем функцию на Python, которая взвешивает матрицу ошибок и возвращает общую стоимость. Строки матрицы ошибок содержат количество наблюдаемых классов, а столбцы — количество предсказанных классов. Напомним, что здесь мы рассматриваем «плохой» как положительный класс (вторая строка и столбец). Инструменты выбора модели Scikit-learn ожидают, что мы следуем соглашению, что «выше» означает «лучше», поэтому следующая матрица выигрыша присваивает отрицательные выигрыши (стоимости) двум видам ошибок предсказания:
увеличение на
-1для каждого ложного положительного результата («хороший» кредит, помеченный как «плохой»),увеличение на
-5за каждый ложный отрицательный результат («плохой» кредит, помеченный как «хороший»),a
0выигрыш для истинно положительных и истинно отрицательных случаев.
Обратите внимание, что теоретически, учитывая, что наша модель откалибрована, а наш набор данных репрезентативен и достаточно велик, нам не нужно настраивать порог, но можно безопасно установить его на 1/5 от соотношения затрат, как указано в уравнении (2) в статье Элкана [2].
import numpy as np
def credit_gain_score(y, y_pred, neg_label, pos_label):
cm = confusion_matrix(y, y_pred, labels=[neg_label, pos_label])
gain_matrix = np.array(
[
[0, -1], # -1 gain for false positives
[-5, 0], # -5 gain for false negatives
]
)
return np.sum(cm * gain_matrix)
scoring["credit_gain"] = make_scorer(
credit_gain_score, neg_label=neg_label, pos_label=pos_label
)
Базовая прогнозная модель#
Мы используем HistGradientBoostingClassifier как прогнозная модель,
которая изначально обрабатывает категориальные признаки и пропущенные значения.
from sklearn.ensemble import HistGradientBoostingClassifier
model = HistGradientBoostingClassifier(
categorical_features="from_dtype", random_state=0
).fit(X_train, y_train)
model
Мы оцениваем производительность нашей прогнозной модели с помощью кривых ROC и Precision-Recall.
import matplotlib.pyplot as plt
from sklearn.metrics import PrecisionRecallDisplay, RocCurveDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(14, 6))
PrecisionRecallDisplay.from_estimator(
model, X_test, y_test, pos_label=pos_label, ax=axs[0], name="GBDT"
)
axs[0].plot(
scoring["recall"](model, X_test, y_test),
scoring["precision"](model, X_test, y_test),
marker="o",
markersize=10,
color="tab:blue",
label="Default cut-off point at a probability of 0.5",
)
axs[0].set_title("Precision-Recall curve")
axs[0].legend()
RocCurveDisplay.from_estimator(
model,
X_test,
y_test,
pos_label=pos_label,
ax=axs[1],
name="GBDT",
plot_chance_level=True,
)
axs[1].plot(
scoring["fpr"](model, X_test, y_test),
scoring["tpr"](model, X_test, y_test),
marker="o",
markersize=10,
color="tab:blue",
label="Default cut-off point at a probability of 0.5",
)
axs[1].set_title("ROC curve")
axs[1].legend()
_ = fig.suptitle("Evaluation of the vanilla GBDT model")

Напомним, что эти кривые дают представление о статистической производительности прогнозной модели для различных пороговых точек. Для кривой Precision-Recall сообщаемыми метриками являются точность и полнота, а для ROC-кривой — TPR (та же, что и полнота) и FPR.
Здесь различные точки отсечения соответствуют разным уровням оценок апостериорной вероятности в диапазоне от 0 до 1. По умолчанию, model.predict использует
точку отсечения при оценке вероятности 0.5. Метрики для такой точки отсечения
приведены с синей точкой на кривых: это соответствует статистической
производительности модели при использовании model.predict.
Однако мы помним, что первоначальной целью было минимизировать стоимость (или максимизировать выгоду), как определено бизнес-метрикой. Мы можем вычислить значение бизнес- метрики:
print(f"Business defined metric: {scoring['credit_gain'](model, X_test, y_test)}")
Business defined metric: -232
На этом этапе мы не знаем, может ли другой порог привести к большему выигрышу. Чтобы найти оптимальный, нужно вычислить соотношение затрат и выгод, используя бизнес-метрику для всех возможных точек отсечения, и выбрать лучшую. Эта стратегия может быть довольно утомительной для реализации вручную, но
TunedThresholdClassifierCV класс здесь, чтобы помочь нам.
Он автоматически вычисляет соотношение затрат и выгод для всех возможных точек отсечения и оптимизирует для scoring.
Настройка точки отсечения#
Мы используем TunedThresholdClassifierCV для настройки порогового значения. Нам нужно предоставить бизнес-метрику для оптимизации, а также положительный класс. Внутренне оптимальное пороговое значение выбирается так, чтобы максимизировать бизнес-метрику с помощью перекрестной проверки. По умолчанию используется 5-кратная стратифицированная перекрестная проверка.
from sklearn.model_selection import TunedThresholdClassifierCV
tuned_model = TunedThresholdClassifierCV(
estimator=model,
scoring=scoring["credit_gain"],
store_cv_results=True, # necessary to inspect all results
)
tuned_model.fit(X_train, y_train)
print(f"{tuned_model.best_threshold_=:0.2f}")
tuned_model.best_threshold_=0.02
Мы строим кривые ROC и Precision-Recall для базовой модели и настроенной модели. Также мы строим точки отсечения, которые будут использоваться каждой моделью. Поскольку мы повторно используем тот же код позже, мы определяем функцию, которая генерирует графики.
def plot_roc_pr_curves(vanilla_model, tuned_model, *, title):
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(21, 6))
linestyles = ("dashed", "dotted")
markerstyles = ("o", ">")
colors = ("tab:blue", "tab:orange")
names = ("Vanilla GBDT", "Tuned GBDT")
for idx, (est, linestyle, marker, color, name) in enumerate(
zip((vanilla_model, tuned_model), linestyles, markerstyles, colors, names)
):
decision_threshold = getattr(est, "best_threshold_", 0.5)
PrecisionRecallDisplay.from_estimator(
est,
X_test,
y_test,
pos_label=pos_label,
linestyle=linestyle,
color=color,
ax=axs[0],
name=name,
)
axs[0].plot(
scoring["recall"](est, X_test, y_test),
scoring["precision"](est, X_test, y_test),
marker,
markersize=10,
color=color,
label=f"Cut-off point at probability of {decision_threshold:.2f}",
)
RocCurveDisplay.from_estimator(
est,
X_test,
y_test,
pos_label=pos_label,
curve_kwargs=dict(linestyle=linestyle, color=color),
ax=axs[1],
name=name,
plot_chance_level=idx == 1,
)
axs[1].plot(
scoring["fpr"](est, X_test, y_test),
scoring["tpr"](est, X_test, y_test),
marker,
markersize=10,
color=color,
label=f"Cut-off point at probability of {decision_threshold:.2f}",
)
axs[0].set_title("Precision-Recall curve")
axs[0].legend()
axs[1].set_title("ROC curve")
axs[1].legend()
axs[2].plot(
tuned_model.cv_results_["thresholds"],
tuned_model.cv_results_["scores"],
color="tab:orange",
)
axs[2].plot(
tuned_model.best_threshold_,
tuned_model.best_score_,
"o",
markersize=10,
color="tab:orange",
label="Optimal cut-off point for the business metric",
)
axs[2].legend()
axs[2].set_xlabel("Decision threshold (probability)")
axs[2].set_ylabel("Objective score (using cost-matrix)")
axs[2].set_title("Objective score as a function of the decision threshold")
fig.suptitle(title)
title = "Comparison of the cut-off point for the vanilla and tuned GBDT model"
plot_roc_pr_curves(model, tuned_model, title=title)

Первое замечание заключается в том, что оба классификатора имеют точно такие же ROC и Precision-Recall кривые. Это ожидаемо, потому что по умолчанию классификатор обучается на одних и тех же тренировочных данных. В следующем разделе мы более подробно обсудим доступные опции относительно переобучения модели и перекрестной проверки.
Второе замечание заключается в том, что точки отсечения базовой и настроенной моделей различны. Чтобы понять, почему настроенная модель выбрала эту точку отсечения, мы можем посмотреть на правый график, который отображает целевую оценку, точно соответствующую нашей бизнес-метрике. Мы видим, что оптимальный порог соответствует максимуму целевой оценки. Этот максимум достигается при пороге принятия решений значительно ниже 0.5: настроенная модель имеет гораздо более высокую полноту за счёт значительно более низкой точности: настроенная модель гораздо охотнее предсказывает метку класса "плохой" для большей доли индивидуумов.
Теперь мы можем проверить, приводит ли выбор этой точки отсечения к лучшей оценке на тестовом наборе:
print(f"Business defined metric: {scoring['credit_gain'](tuned_model, X_test, y_test)}")
Business defined metric: -134
Мы наблюдаем, что настройка порога принятия решения почти удваивает наши бизнес-выгоды.
Соображения относительно переобучения модели и перекрестной проверки#
В приведенном выше эксперименте мы использовали настройки по умолчанию для
TunedThresholdClassifierCV. В частности,
точка отсечения настраивается с использованием 5-кратной стратифицированной перекрестной проверки. Также,
базовая прогностическая модель переобучается на всех обучающих данных после выбора точки
отсечения.
Эти две стратегии могут быть изменены путем предоставления refit и cv параметры.
Например, можно предоставить обученный estimator и установить cv="prefit", в этом случае точка отсечения находится на всем наборе данных, предоставленном во время обучения.
Также, базовый классификатор не переобучается установкой refit=False. Здесь мы
можем попробовать провести такой эксперимент.
model.fit(X_train, y_train)
tuned_model.set_params(cv="prefit", refit=False).fit(X_train, y_train)
print(f"{tuned_model.best_threshold_=:0.2f}")
tuned_model.best_threshold_=0.28
Затем мы оцениваем нашу модель тем же подходом, что и ранее:
title = "Tuned GBDT model without refitting and using the entire dataset"
plot_roc_pr_curves(model, tuned_model, title=title)

Мы наблюдаем, что оптимальная точка отсечения отличается от найденной в предыдущем эксперименте. Если посмотреть на график справа, мы видим, что бизнес-выгода имеет большое плато почти оптимальной нулевой выгоды для большого диапазона порогов решений. Это поведение симптоматично для переобучения. Поскольку мы отключили перекрестную проверку, мы настроили точку отсечения на том же наборе, на котором обучалась модель, и это причина наблюдаемого переобучения.
Поэтому эту опцию следует использовать с осторожностью. Необходимо убедиться, что данные, предоставленные во время подгонки к
TunedThresholdClassifierCV не совпадает с данными, использованными для обучения базового классификатора. Это может иногда происходить, когда идея состоит просто в настройке прогнозной модели на совершенно новом валидационном наборе без затратной полной переобучения.
Когда перекрестная проверка слишком затратна, потенциальной альтернативой является использование одного разделения на обучающую и тестовую выборки, указав число с плавающей точкой в диапазоне [0, 1] в cv
параметр. Он разделяет данные на обучающую и тестовую выборки. Давайте рассмотрим эту
опцию:
tuned_model.set_params(cv=0.75).fit(X_train, y_train)
title = "Tuned GBDT model without refitting and using the entire dataset"
plot_roc_pr_curves(model, tuned_model, title=title)
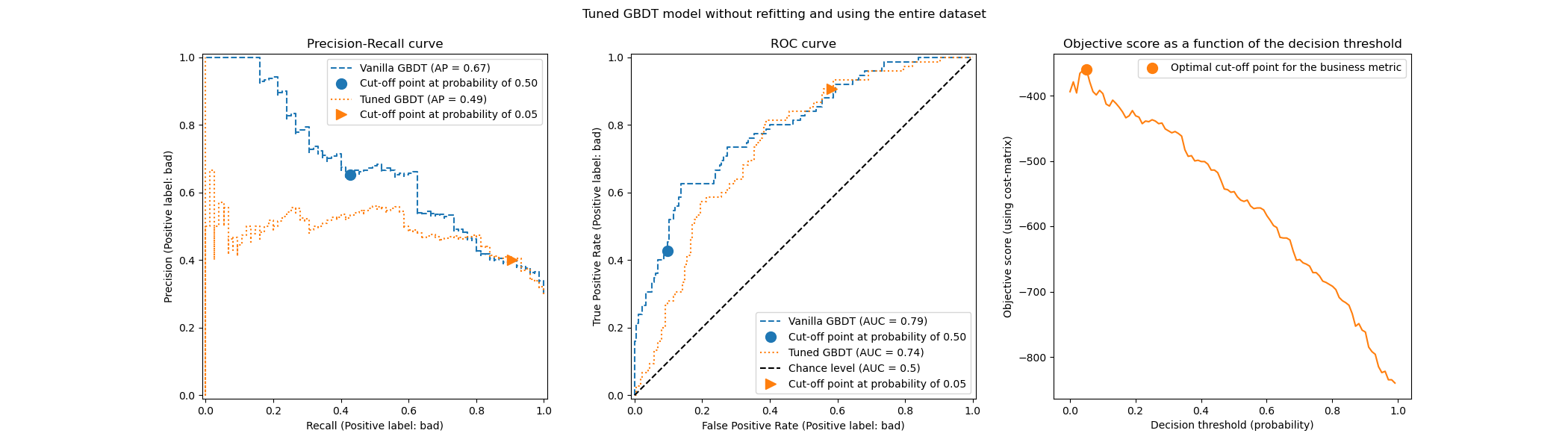
Что касается точки отсечения, мы наблюдаем, что оптимум аналогичен случаю многократной повторной перекрестной проверки. Однако учтите, что единичное разбиение не учитывает изменчивость процесса обучения/прогнозирования, поэтому мы не можем знать, есть ли дисперсия в точке отсечения. Повторная перекрестная проверка усредняет этот эффект.
Еще одно наблюдение касается кривых ROC и Precision-Recall настроенной модели. Как и ожидалось, эти кривые отличаются от кривых базовой модели, учитывая, что мы обучали базовый классификатор на подмножестве данных, предоставленных во время обучения, и оставили проверочный набор для настройки точки отсечения.
Обучение с учетом стоимости, когда выгоды и затраты не постоянны#
Как указано в [2], выгоды и затраты обычно не постоянны в реальных задачах. В этом разделе мы используем пример, аналогичный приведенному в [2] для задачи обнаружения мошенничества в записях транзакций по кредитным картам.
Набор данных кредитных карт#
credit_card = fetch_openml(data_id=1597, as_frame=True, parser="pandas")
credit_card.frame.info()
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V1 284807 non-null float64
1 V2 284807 non-null float64
2 V3 284807 non-null float64
3 V4 284807 non-null float64
4 V5 284807 non-null float64
5 V6 284807 non-null float64
6 V7 284807 non-null float64
7 V8 284807 non-null float64
8 V9 284807 non-null float64
9 V10 284807 non-null float64
10 V11 284807 non-null float64
11 V12 284807 non-null float64
12 V13 284807 non-null float64
13 V14 284807 non-null float64
14 V15 284807 non-null float64
15 V16 284807 non-null float64
16 V17 284807 non-null float64
17 V18 284807 non-null float64
18 V19 284807 non-null float64
19 V20 284807 non-null float64
20 V21 284807 non-null float64
21 V22 284807 non-null float64
22 V23 284807 non-null float64
23 V24 284807 non-null float64
24 V25 284807 non-null float64
25 V26 284807 non-null float64
26 V27 284807 non-null float64
27 V28 284807 non-null float64
28 Amount 284807 non-null float64
29 Class 284807 non-null category
dtypes: category(1), float64(29)
memory usage: 63.3 MB
Набор данных содержит информацию о записях кредитных карт, среди которых некоторые являются мошенническими, а другие — законными. Цель состоит в том, чтобы предсказать, является ли запись кредитной карты мошеннической или нет.
columns_to_drop = ["Class"]
data = credit_card.frame.drop(columns=columns_to_drop)
target = credit_card.frame["Class"].astype(int)
Сначала мы проверяем распределение классов в наборах данных.
target.value_counts(normalize=True)
Class
0 0.998273
1 0.001727
Name: proportion, dtype: float64
Набор данных сильно несбалансирован, при этом мошеннические транзакции составляют всего 0,17% данных. Поскольку мы заинтересованы в обучении модели машинного обучения, мы также должны убедиться, что у нас достаточно образцов в миноритарном классе для обучения модели.
target.value_counts()
Class
0 284315
1 492
Name: count, dtype: int64
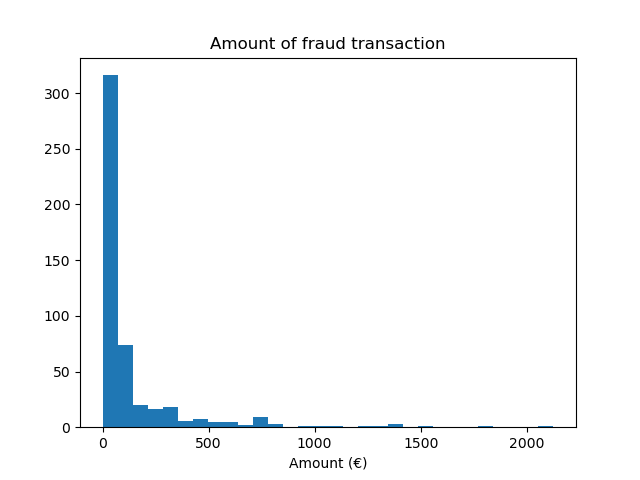
Мы наблюдаем, что у нас около 500 выборок, что находится на нижней границе количества выборок, необходимых для обучения модели машинного обучения. В дополнение к распределению целевой переменной мы проверяем распределение количества мошеннических транзакций.
fraud = target == 1
amount_fraud = data["Amount"][fraud]
_, ax = plt.subplots()
ax.hist(amount_fraud, bins=30)
ax.set_title("Amount of fraud transaction")
_ = ax.set_xlabel("Amount (€)")
Решение проблемы с бизнес-метрикой#
Теперь создадим бизнес-метрику, которая зависит от суммы каждой транзакции. Мы определяем матрицу затрат аналогично [2]. Принятие легитимной транзакции дает выигрыш в размере 2% от суммы транзакции. Однако принятие мошеннической транзакции приводит к потере суммы транзакции. Как указано в [2], выигрыш и потери, связанные с отказами (от мошеннических и легитимных транзакций), не тривиальны для определения. Здесь мы определяем, что отказ от легитимной транзакции оценивается как потеря 5€, а отказ от мошеннической транзакции оценивается как выигрыш 50€. Поэтому мы определяем следующую функцию для вычисления общей выгоды от данного решения:
def business_metric(y_true, y_pred, amount):
mask_true_positive = (y_true == 1) & (y_pred == 1)
mask_true_negative = (y_true == 0) & (y_pred == 0)
mask_false_positive = (y_true == 0) & (y_pred == 1)
mask_false_negative = (y_true == 1) & (y_pred == 0)
fraudulent_refuse = mask_true_positive.sum() * 50
fraudulent_accept = -amount[mask_false_negative].sum()
legitimate_refuse = mask_false_positive.sum() * -5
legitimate_accept = (amount[mask_true_negative] * 0.02).sum()
return fraudulent_refuse + fraudulent_accept + legitimate_refuse + legitimate_accept
Из этой бизнес-метрики мы создаём scikit-learn scorer, который для обученного классификатора и тестового набора вычисляет бизнес-метрику. В этом отношении мы используем make_scorer фабрика. Переменная amount является дополнительными метаданными, которые нужно передать оценщику, и мы должны использовать
маршрутизация метаданных чтобы учесть эту информацию.
sklearn.set_config(enable_metadata_routing=True)
business_scorer = make_scorer(business_metric).set_score_request(amount=True)
Таким образом, на этом этапе мы наблюдаем, что сумма транзакции используется дважды: один раз как признак для обучения нашей прогнозной модели и один раз как метаданные для вычисления бизнес-метрики и, следовательно, статистической производительности нашей модели. При использовании в качестве признака нам требуется только столбец в data который содержит сумму каждой транзакции. Чтобы использовать эту информацию как метаданные, нам нужна внешняя переменная, которую мы можем передать в скорер или модель, которая внутренне направляет эти метаданные в скорер. Давайте создадим эту переменную.
amount = credit_card.frame["Amount"].to_numpy()
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test, amount_train, amount_test = (
train_test_split(
data, target, amount, stratify=target, test_size=0.5, random_state=42
)
)
Сначала мы оцениваем некоторые базовые политики в качестве эталона. Напомним, что класс «0» — это законный класс, а класс «1» — мошеннический класс.
from sklearn.dummy import DummyClassifier
always_accept_policy = DummyClassifier(strategy="constant", constant=0)
always_accept_policy.fit(data_train, target_train)
benefit = business_scorer(
always_accept_policy, data_test, target_test, amount=amount_test
)
print(f"Benefit of the 'always accept' policy: {benefit:,.2f}€")
Benefit of the 'always accept' policy: 221,445.07€
Политика, которая считает все транзакции легитимными, принесла бы прибыль около 220 000€. Мы проводим такую же оценку для классификатора, который предсказывает все транзакции как мошеннические.
always_reject_policy = DummyClassifier(strategy="constant", constant=1)
always_reject_policy.fit(data_train, target_train)
benefit = business_scorer(
always_reject_policy, data_test, target_test, amount=amount_test
)
print(f"Benefit of the 'always reject' policy: {benefit:,.2f}€")
Benefit of the 'always reject' policy: -698,490.00€
Такая политика повлечёт катастрофические потери: около 670 000€. Это ожидаемо, поскольку подавляющее большинство транзакций являются законными, и политика отклонит их с нетривиальными затратами.
Прогнозирующая модель, которая адаптирует решения о принятии/отклонении для каждой транзакции, в идеале должна позволять нам получать прибыль, превышающую 220 000€ лучшей из наших постоянных базовых политик.
Мы начинаем с модели логистической регрессии с порогом принятия решений по умолчанию 0.5. Здесь мы настраиваем гиперпараметр C логистической регрессии с
правильным правилом оценки (логарифмической потерей), чтобы гарантировать, что вероятностные
предсказания модели, возвращаемые её predict_proba метод являются максимально точными независимо от выбора значения порога принятия решения.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
logistic_regression = make_pipeline(StandardScaler(), LogisticRegression())
param_grid = {"logisticregression__C": np.logspace(-6, 6, 13)}
model = GridSearchCV(logistic_regression, param_grid, scoring="neg_log_loss").fit(
data_train, target_train
)
model
print(
"Benefit of logistic regression with default threshold: "
f"{business_scorer(model, data_test, target_test, amount=amount_test):,.2f}€"
)
Benefit of logistic regression with default threshold: 244,919.87€
Бизнес-метрика показывает, что наша прогнозная модель с порогом решения по умолчанию уже превосходит базовый уровень с точки зрения прибыли, и уже было бы выгодно использовать ее для принятия или отклонения транзакций вместо принятия всех транзакций.
Настройка порога принятия решения#
Теперь вопрос: оптимальна ли наша модель для типа решения, которое мы хотим принять?
До сих пор мы не оптимизировали порог принятия решения. Мы используем
TunedThresholdClassifierCV для оптимизации решения с учетом нашего бизнес-скоринга. Чтобы избежать вложенной кросс-валидации, мы будем использовать лучший оценщик, найденный в ходе предыдущего поиска по сетке.
tuned_model = TunedThresholdClassifierCV(
estimator=model.best_estimator_,
scoring=business_scorer,
thresholds=100,
n_jobs=2,
)
Поскольку наш бизнес-скоринг требует сумму каждой транзакции, нам необходимо передать эту информацию в fit метод. Метод
TunedThresholdClassifierCV отвечает за автоматическую передачу этих метаданных нижележащему скореру.
tuned_model.fit(data_train, target_train, amount=amount_train)
Мы наблюдаем, что настроенный порог принятия решения сильно отличается от стандартного 0.5:
print(f"Tuned decision threshold: {tuned_model.best_threshold_:.2f}")
Tuned decision threshold: 0.03
print(
"Benefit of logistic regression with a tuned threshold: "
f"{business_scorer(tuned_model, data_test, target_test, amount=amount_test):,.2f}€"
)
Benefit of logistic regression with a tuned threshold: 249,433.39€
Мы наблюдаем, что настройка порога принятия решений увеличивает ожидаемую прибыль при развёртывании нашей модели — как указано бизнес-метрикой. Поэтому ценно, когда это возможно, оптимизировать порог принятия решений относительно бизнес-метрики.
Ручная установка порога принятия решений вместо его настройки#
В предыдущем примере мы использовали
TunedThresholdClassifierCV чтобы найти оптимальный
порог принятия решения. Однако в некоторых случаях у нас может быть предварительное знание о
рассматриваемой проблеме, и мы можем быть готовы установить порог принятия решения вручную.
Класс FixedThresholdClassifier позволяет нам вручную установить порог принятия решения. Во время предсказания он ведет себя как предыдущая настроенная модель, но поиск не выполняется в процессе обучения. Обратите внимание, что здесь мы используем FrozenEstimator для обертывания прогнозной модели, чтобы избежать повторного обучения.
Здесь мы повторно используем порог принятия решения, найденный в предыдущем разделе, чтобы создать новую модель и проверить, что она дает те же результаты.
from sklearn.frozen import FrozenEstimator
from sklearn.model_selection import FixedThresholdClassifier
model_fixed_threshold = FixedThresholdClassifier(
estimator=FrozenEstimator(model), threshold=tuned_model.best_threshold_
)
business_score = business_scorer(
model_fixed_threshold, data_test, target_test, amount=amount_test
)
print(f"Benefit of logistic regression with a tuned threshold: {business_score:,.2f}€")
Benefit of logistic regression with a tuned threshold: 249,433.39€
Мы видим, что получили точно такие же результаты, но процесс подгонки был намного быстрее, поскольку мы не выполняли поиск гиперпараметров.
Наконец, оценка (средней) бизнес-метрики сама по себе может быть ненадежной, в частности, когда количество точек данных в миноритарном классе очень мало. Любое влияние на бизнес, оцененное с помощью перекрестной проверки бизнес-метрики на исторических данных (офлайн-оценка), в идеале должно подтверждаться A/B-тестированием на живых данных (онлайн-оценка). Однако обратите внимание, что A/B-тестирование моделей выходит за рамки самой библиотеки scikit-learn.
В конце мы отключаем флаг конфигурации для маршрутизации метаданных:
.. GENERATED FROM PYTHON SOURCE LINES 694-695
sklearn.set_config(enable_metadata_routing=False)
Общее время выполнения скрипта: (0 минут 33.020 секунд)
Связанные примеры
Пост-фактумная настройка точки отсечения функции принятия решений

Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией