Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Поддержка категориальных признаков в градиентном бустинге#
В этом примере мы сравниваем время обучения и производительность предсказания
HistGradientBoostingRegressor с различными стратегиями кодирования
категориальных признаков. В частности, мы оцениваем:
“Удалено”: удаление категориальных признаков;
“One Hot”: используя
OneHotEncoder;“Ordinal”: используя
OrdinalEncoderи рассматривать категории как упорядоченные, равноудалённые величины;"Target": используя
TargetEncoder;«Native»: полагаясь на поддержка нативных категорий из
HistGradientBoostingRegressorоценщик.
Для этой цели мы используем набор данных Ames Iowa Housing, который состоит из числовых и категориальных признаков, где целевой переменной является цена продажи дома.
См. Признаки в деревьях с градиентным бустингом на гистограммах для примера, демонстрирующего некоторые другие возможности
HistGradientBoostingRegressor.
См. Сравнение Target Encoder с другими кодировщиками для сравнения стратегий кодирования при наличии категориальных признаков с высокой кардинальностью.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузить набор данных Ames Housing#
Сначала мы загружаем данные о жилье в Эймсе как pandas dataframe. Признаки являются либо категориальными, либо числовыми:
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=42165, as_frame=True, return_X_y=True)
# Select only a subset of features of X to make the example faster to run
categorical_columns_subset = [
"BldgType",
"GarageFinish",
"LotConfig",
"Functional",
"MasVnrType",
"HouseStyle",
"FireplaceQu",
"ExterCond",
"ExterQual",
"PoolQC",
]
numerical_columns_subset = [
"3SsnPorch",
"Fireplaces",
"BsmtHalfBath",
"HalfBath",
"GarageCars",
"TotRmsAbvGrd",
"BsmtFinSF1",
"BsmtFinSF2",
"GrLivArea",
"ScreenPorch",
]
X = X[categorical_columns_subset + numerical_columns_subset]
X[categorical_columns_subset] = X[categorical_columns_subset].astype("category")
categorical_columns = X.select_dtypes(include="category").columns
n_categorical_features = len(categorical_columns)
n_numerical_features = X.select_dtypes(include="number").shape[1]
print(f"Number of samples: {X.shape[0]}")
print(f"Number of features: {X.shape[1]}")
print(f"Number of categorical features: {n_categorical_features}")
print(f"Number of numerical features: {n_numerical_features}")
Number of samples: 1460
Number of features: 20
Number of categorical features: 10
Number of numerical features: 10
Оценщик градиентного бустинга с отброшенными категориальными признаками#
В качестве базового уровня мы создаём оценщик, в котором категориальные признаки удаляются:
from sklearn.compose import make_column_selector, make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
dropper = make_column_transformer(
("drop", make_column_selector(dtype_include="category")), remainder="passthrough"
)
hist_dropped = make_pipeline(dropper, HistGradientBoostingRegressor(random_state=42))
hist_dropped
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('drop', 'drop',
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
drop
passthrough
Параметры
Оценщик градиентного бустинга с one-hot кодированием#
Далее мы создаём конвейер для one-hot кодирования категориальных признаков, оставляя остальные признаки "passthrough" без изменений:
from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, handle_unknown="ignore"),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_one_hot = make_pipeline(
one_hot_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_one_hot
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('onehotencoder',
OneHotEncoder(handle_unknown='ignore',
sparse_output=False),
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
passthrough
Параметры
Оценщик градиентного бустинга с порядковым кодированием#
Далее мы создаем конвейер, который обрабатывает категориальные признаки как упорядоченные величины, т.е. категории кодируются как 0, 1, 2 и т.д. и рассматриваются как непрерывные признаки.
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = make_column_transformer(
(
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=np.nan),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_ordinal = make_pipeline(
ordinal_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_ordinal
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('ordinalencoder',
OrdinalEncoder(handle_unknown='use_encoded_value',
unknown_value=nan),
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
passthrough
Параметры
Оценщик градиентного бустинга с кодированием целевой переменной#
Другая возможность - использовать TargetEncoder, который кодирует категории, вычисленные из среднего значения целевой переменной (обучающей), вычисленного с использованием сглаженного np.mean(y, axis=0) т.е.:
в регрессии используется среднее значение
y;в бинарной классификации, частота положительного класса;
в многоклассовой задаче, вектор частот классов (по одному на класс).
Для каждой категории он вычисляет эти средние значения целевой переменной, используя кросс фиттинг, что означает, что обучающие данные разбиваются на фолды: в каждом фолде средние значения вычисляются только на подмножестве данных, а затем применяются к удерживаемой части. Таким образом, каждый образец кодируется с использованием статистики из данных, частью которых он не был, предотвращая утечку информации от целевой переменной.
from sklearn.preprocessing import TargetEncoder
target_encoder = make_column_transformer(
(
TargetEncoder(target_type="continuous", random_state=42),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_target = make_pipeline(
target_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_target
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('targetencoder',
TargetEncoder(random_state=42,
target_type='continuous'),
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
passthrough
Параметры
Оценщик градиентного бустинга с нативной поддержкой категориальных признаков#
Теперь мы создаем HistGradientBoostingRegressor оценщик, который может изначально обрабатывать категориальные признаки без явного кодирования. Такая функциональность может быть включена установкой categorical_features="from_dtype",
который автоматически обнаруживает признаки с категориальными типами данных, или более явно
с помощью categorical_features=categorical_columns_subset.
В отличие от предыдущих подходов к кодированию, оценщик изначально работает с категориальными признаками. На каждом разбиении он разделяет категории такого признака на непересекающиеся множества с помощью эвристики, которая сортирует их по их влиянию на целевую переменную, см. Поиск разбиений с категориальными признаками подробности.
Хотя порядковое кодирование может хорошо работать для признаков с низкой кардинальностью, даже если категории не имеют естественного порядка, достижение значимых разделений требует более глубоких деревьев с увеличением кардинальности. Нативная поддержка категориальных признаков избегает этого, работая напрямую с неупорядоченными категориями. Преимущество перед one-hot кодированием заключается в отсутствии предварительной обработки и более быстром времени обучения и предсказания.
hist_native = HistGradientBoostingRegressor(
random_state=42, categorical_features="from_dtype"
)
hist_native
HistGradientBoostingRegressor(random_state=42)В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту.
На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Сравнение моделей#
Здесь мы используем кросс-валидация для сравнения производительности моделей
в терминах mean_absolute_percentage_error и времена обучения. На предстоящих графиках полосы ошибок представляют 1 стандартное отклонение, вычисленное по разбиениям перекрестной проверки.
from sklearn.model_selection import cross_validate
common_params = {"cv": 5, "scoring": "neg_mean_absolute_percentage_error", "n_jobs": -1}
dropped_result = cross_validate(hist_dropped, X, y, **common_params)
one_hot_result = cross_validate(hist_one_hot, X, y, **common_params)
ordinal_result = cross_validate(hist_ordinal, X, y, **common_params)
target_result = cross_validate(hist_target, X, y, **common_params)
native_result = cross_validate(hist_native, X, y, **common_params)
results = [
("Dropped", dropped_result),
("One Hot", one_hot_result),
("Ordinal", ordinal_result),
("Target", target_result),
("Native", native_result),
]
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def plot_performance_tradeoff(results, title):
fig, ax = plt.subplots()
markers = ["s", "o", "^", "x", "D"]
for idx, (name, result) in enumerate(results):
test_error = -result["test_score"]
mean_fit_time = np.mean(result["fit_time"])
mean_score = np.mean(test_error)
std_fit_time = np.std(result["fit_time"])
std_score = np.std(test_error)
ax.scatter(
result["fit_time"],
test_error,
label=name,
marker=markers[idx],
)
ax.scatter(
mean_fit_time,
mean_score,
color="k",
marker=markers[idx],
)
ax.errorbar(
x=mean_fit_time,
y=mean_score,
yerr=std_score,
c="k",
capsize=2,
)
ax.errorbar(
x=mean_fit_time,
y=mean_score,
xerr=std_fit_time,
c="k",
capsize=2,
)
ax.set_xscale("log")
nticks = 7
x0, x1 = np.log10(ax.get_xlim())
ticks = np.logspace(x0, x1, nticks)
ax.set_xticks(ticks)
ax.xaxis.set_major_formatter(ticker.FormatStrFormatter("%1.1e"))
ax.minorticks_off()
ax.annotate(
" best\nmodels",
xy=(0.04, 0.04),
xycoords="axes fraction",
xytext=(0.09, 0.14),
textcoords="axes fraction",
arrowprops=dict(arrowstyle="->", lw=1.5),
)
ax.set_xlabel("Time to fit (seconds)")
ax.set_ylabel("Mean Absolute Percentage Error")
ax.set_title(title)
ax.legend()
plt.show()
plot_performance_tradeoff(results, "Gradient Boosting on Ames Housing")
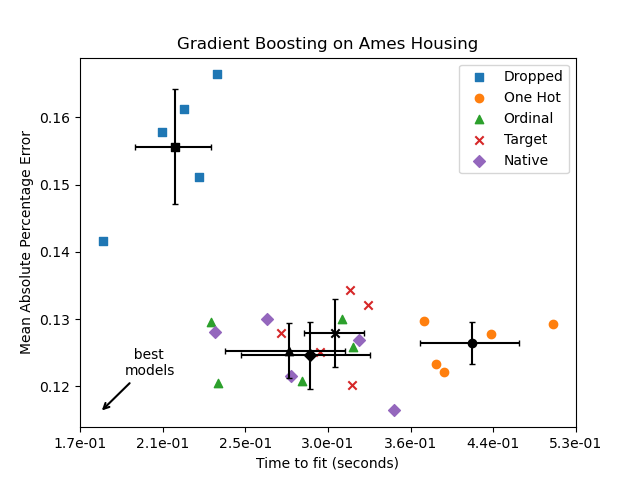
На графике выше «лучшие модели» — те, что ближе к нижнему левому углу, как показано стрелкой. Эти модели действительно соответствуют более быстрому обучению и меньшей ошибке.
Модель, использующая one-hot кодированные данные, самая медленная. Это ожидаемо, так как one-hot кодирование создаёт дополнительный признак для каждого категориального значения каждого категориального признака, значительно увеличивая количество кандидатов на разбиение во время обучения. Теоретически мы ожидаем, что нативная обработка категориальных признаков будет немного медленнее, чем обработка категорий как упорядоченных величин ('Ordinal'), поскольку нативная обработка требует сортировки категорий. Однако время обучения должно быть близким, когда количество категорий мало, и это не всегда отражается на практике.
Время, необходимое для обучения при использовании TargetEncoder зависит от параметра перекрёстной подгонки cv, так как добавление разбиений требует вычислительных затрат.
С точки зрения производительности предсказания, удаление категориальных признаков приводит к наихудшей производительности. Четыре модели, которые используют категориальные признаки, имеют сопоставимые показатели ошибок, с небольшим преимуществом для нативной обработки.
Ограничение количества разбиений#
В целом, можно ожидать худших прогнозов от данных с one-hot-кодированием, особенно когда глубина деревьев или количество узлов ограничены: с данными с one-hot-кодированием требуется больше точек разделения, т.е. больше глубины, чтобы восстановить эквивалентное разделение, которое можно получить в одной точке разделения при нативной обработке.
Это также верно, когда категории рассматриваются как порядковые величины: если
категории A..F и лучшее разделение - это ACF - BDE модель one-hot-encoder потребовала бы 3 точки разделения (по одной на категорию в левом узле), а порядковая неродная модель потребовала бы 4 разделения: 1 разделение для изоляции A, 1 разделение
для изоляции F, и 2 разделения для изоляции C из BCDE.
Насколько сильно производительность моделей отличается на практике, зависит от набора данных и гибкости деревьев.
Чтобы увидеть это, давайте повторно запустим тот же анализ с недообученными моделями, где мы искусственно ограничиваем общее количество разбиений, ограничивая как количество деревьев, так и глубину каждого дерева.
for pipe in (hist_dropped, hist_one_hot, hist_ordinal, hist_target, hist_native):
if pipe is hist_native:
# The native model does not use a pipeline so, we can set the parameters
# directly.
pipe.set_params(max_depth=3, max_iter=15)
else:
pipe.set_params(
histgradientboostingregressor__max_depth=3,
histgradientboostingregressor__max_iter=15,
)
dropped_result = cross_validate(hist_dropped, X, y, **common_params)
one_hot_result = cross_validate(hist_one_hot, X, y, **common_params)
ordinal_result = cross_validate(hist_ordinal, X, y, **common_params)
target_result = cross_validate(hist_target, X, y, **common_params)
native_result = cross_validate(hist_native, X, y, **common_params)
results_underfit = [
("Dropped", dropped_result),
("One Hot", one_hot_result),
("Ordinal", ordinal_result),
("Target", target_result),
("Native", native_result),
]
plot_performance_tradeoff(
results_underfit, "Gradient Boosting on Ames Housing (few and shallow trees)"
)
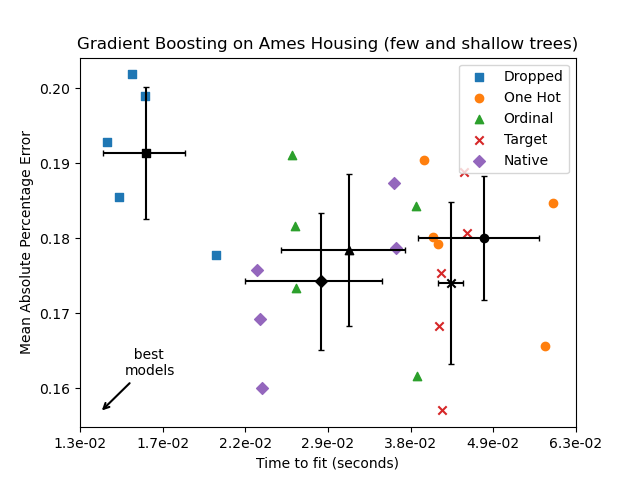
Результаты для этих недообученных моделей подтверждают нашу предыдущую интуицию: стратегия нативной обработки категорий работает лучше всего, когда бюджет разделения ограничен. Три стратегии явного кодирования (one-hot, порядковое и таргет-кодирование) приводят к немного большим ошибкам, чем нативная обработка оценщика, но все же работают лучше, чем базовая модель, которая просто удалила категориальные признаки.
Общее время выполнения скрипта: (0 минут 5.532 секунд)
Связанные примеры