Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Сравнение Target Encoder с другими кодировщиками#
The TargetEncoder использует значение целевой переменной для кодирования каждого категориального признака. В этом примере мы сравним три различных подхода к обработке категориальных признаков: TargetEncoder,
OrdinalEncoder, OneHotEncoder и удаление категории.
Примечание
fit(X, y).transform(X) . Наличие образца fit_transform(X, y) поскольку
используется схема перекрестного обучения в fit_transform для кодирования. См.
Руководство пользователя подробности.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузка данных из OpenML#
Сначала мы загружаем набор данных обзоров вин, где целевой переменной являются баллы, выставленные рецензентом:
from sklearn.datasets import fetch_openml
wine_reviews = fetch_openml(data_id=42074, as_frame=True)
df = wine_reviews.frame
df.head()
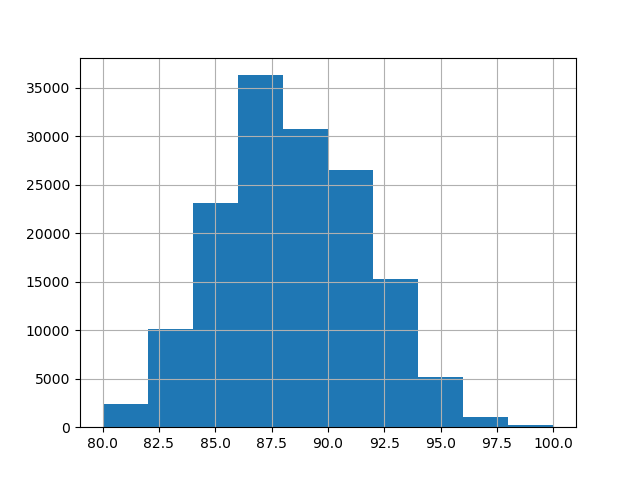
Для этого примера мы используем следующий подмножество числовых и категориальных признаков в данных. Целевая переменная — непрерывные значения от 80 до 100:
numerical_features = ["price"]
categorical_features = [
"country",
"province",
"region_1",
"region_2",
"variety",
"winery",
]
target_name = "points"
X = df[numerical_features + categorical_features]
y = df[target_name]
_ = y.hist()
Обучение и оценка конвейеров с различными кодировщиками#
В этом разделе мы оценим конвейеры с
HistGradientBoostingRegressor с различными стратегиями
кодирования. Сначала перечислим кодировщики, которые будем использовать для предобработки
категориальных признаков:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, TargetEncoder
categorical_preprocessors = [
("drop", "drop"),
("ordinal", OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1)),
(
"one_hot",
OneHotEncoder(handle_unknown="ignore", max_categories=20, sparse_output=False),
),
("target", TargetEncoder(target_type="continuous")),
]
Далее мы оцениваем модели с помощью перекрестной проверки и записываем результаты:
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_validate
from sklearn.pipeline import make_pipeline
n_cv_folds = 3
max_iter = 20
results = []
def evaluate_model_and_store(name, pipe):
result = cross_validate(
pipe,
X,
y,
scoring="neg_root_mean_squared_error",
cv=n_cv_folds,
return_train_score=True,
)
rmse_test_score = -result["test_score"]
rmse_train_score = -result["train_score"]
results.append(
{
"preprocessor": name,
"rmse_test_mean": rmse_test_score.mean(),
"rmse_test_std": rmse_train_score.std(),
"rmse_train_mean": rmse_train_score.mean(),
"rmse_train_std": rmse_train_score.std(),
}
)
for name, categorical_preprocessor in categorical_preprocessors:
preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
("categorical", categorical_preprocessor, categorical_features),
]
)
pipe = make_pipeline(
preprocessor, HistGradientBoostingRegressor(random_state=0, max_iter=max_iter)
)
evaluate_model_and_store(name, pipe)
Нативная поддержка категориальных признаков#
В этом разделе мы строим и оцениваем конвейер, использующий нативную поддержку категориальных признаков в HistGradientBoostingRegressor, которая поддерживает только до 255 уникальных категорий. В нашем наборе данных большинство категориальных признаков имеют более 255 уникальных категорий:
n_unique_categories = df[categorical_features].nunique().sort_values(ascending=False)
n_unique_categories
winery 14810
region_1 1236
variety 632
province 455
country 48
region_2 18
dtype: int64
Чтобы обойти указанное ограничение, мы группируем категориальные признаки на признаки с низкой и высокой кардинальностью. Признаки с высокой кардинальностью будут закодированы через target encoding, а признаки с низкой кардинальностью будут использовать нативную категориальную поддержку в градиентном бустинге.
high_cardinality_features = n_unique_categories[n_unique_categories > 255].index
low_cardinality_features = n_unique_categories[n_unique_categories <= 255].index
mixed_encoded_preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
(
"high_cardinality",
TargetEncoder(target_type="continuous"),
high_cardinality_features,
),
(
"low_cardinality",
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1),
low_cardinality_features,
),
],
verbose_feature_names_out=False,
)
# The output of the of the preprocessor must be set to pandas so the
# gradient boosting model can detect the low cardinality features.
mixed_encoded_preprocessor.set_output(transform="pandas")
mixed_pipe = make_pipeline(
mixed_encoded_preprocessor,
HistGradientBoostingRegressor(
random_state=0, max_iter=max_iter, categorical_features=low_cardinality_features
),
)
mixed_pipe
Наконец, мы оцениваем конвейер с помощью перекрестной проверки и записываем результаты:
evaluate_model_and_store("mixed_target", mixed_pipe)
Построение графиков результатов#
В этом разделе мы отображаем результаты, строя графики оценок тестовой и обучающей выборок:
import matplotlib.pyplot as plt
import pandas as pd
results_df = (
pd.DataFrame(results).set_index("preprocessor").sort_values("rmse_test_mean")
)
fig, (ax1, ax2) = plt.subplots(
1, 2, figsize=(12, 8), sharey=True, constrained_layout=True
)
xticks = range(len(results_df))
name_to_color = dict(
zip((r["preprocessor"] for r in results), ["C0", "C1", "C2", "C3", "C4"])
)
for subset, ax in zip(["test", "train"], [ax1, ax2]):
mean, std = f"rmse_{subset}_mean", f"rmse_{subset}_std"
data = results_df[[mean, std]].sort_values(mean)
ax.bar(
x=xticks,
height=data[mean],
yerr=data[std],
width=0.9,
color=[name_to_color[name] for name in data.index],
)
ax.set(
title=f"RMSE ({subset.title()})",
xlabel="Encoding Scheme",
xticks=xticks,
xticklabels=data.index,
)
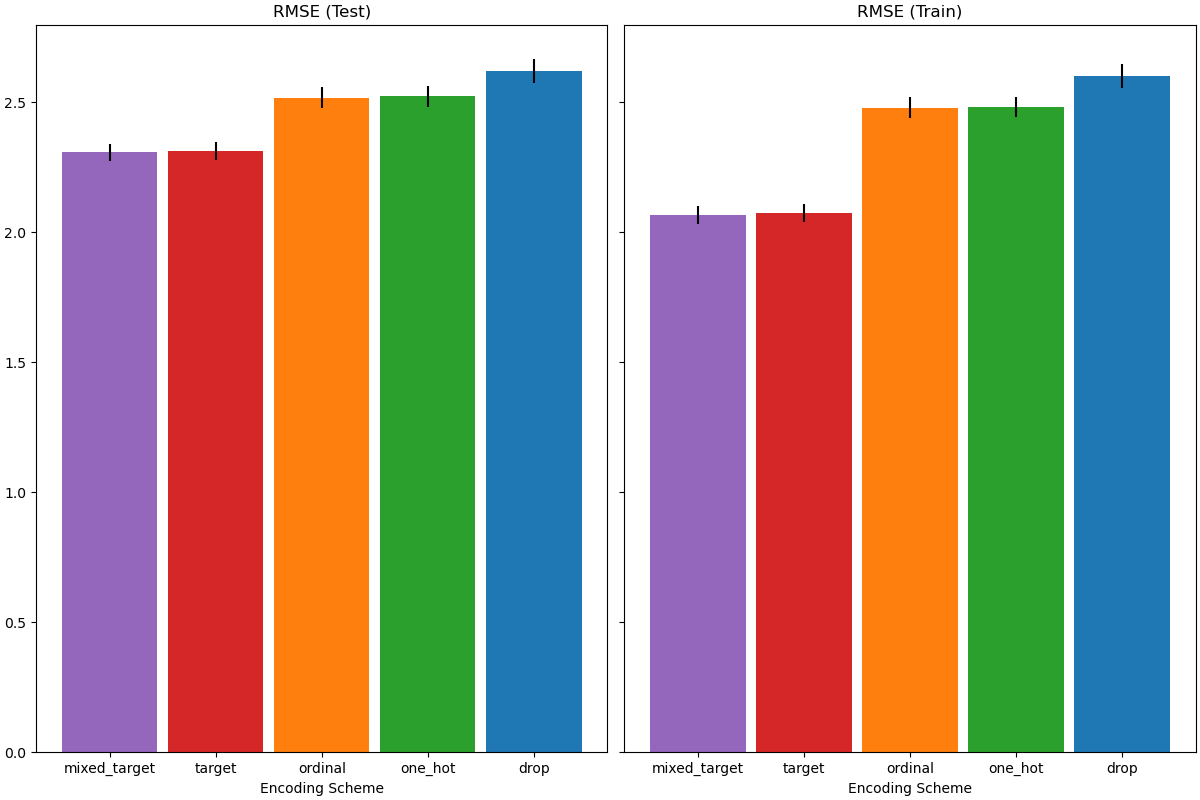
При оценке прогностической производительности на тестовом наборе, удаление категорий показывает наихудшие результаты, а кодировщики целевой переменной — наилучшие. Это можно объяснить следующим образом:
Удаление категориальных признаков делает конвейер менее выразительным и приводит к недообучению;
Из-за высокой кардинальности и для сокращения времени обучения схема one-hot кодирования использует
max_categories=20что предотвращает чрезмерное расширение признаков, которое может привести к недообучению.Если бы мы не установили
max_categories=20, схема one-hot кодирования, вероятно, привела бы к переобучению конвейера, так как количество признаков взрывается с редкими вхождениями категорий, которые коррелируют с целью случайно (только на обучающей выборке);Порядковое кодирование накладывает произвольный порядок на признаки, которые затем обрабатываются как числовые значения с помощью
HistGradientBoostingRegressor. Поскольку эта модель группирует числовые признаки в 256 бинов на признак, многие несвязанные категории могут быть сгруппированы вместе, и в результате весь конвейер может недообучаться;При использовании кодировщика целевой переменной происходит то же самое бинирование, но поскольку закодированные значения статистически упорядочены по маргинальной связи с целевой переменной, бинирование, используемое
HistGradientBoostingRegressorимеет смысл и приводит к хорошим результатам: комбинация сглаженного целевого кодирования и бинирования работает как хорошая стратегия регуляризации против переобучения, не слишком ограничивая выразительность конвейера.
Общее время выполнения скрипта: (0 минут 21.865 секунд)
Связанные примеры
Поддержка категориальных признаков в градиентном бустинге