Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Ранняя остановка в градиентном бустинге#
Градиентный бустинг — это ансамблевая техника, которая объединяет несколько слабых учеников, обычно деревьев решений, для создания надёжной и мощной прогнозной модели. Это делается итеративно, где каждый новый этап (дерево) исправляет ошибки предыдущих.
Ранняя остановка — это техника в градиентном бустинге, которая позволяет найти оптимальное количество итераций, необходимое для построения модели, которая хорошо обобщается на невидимые данные и избегает переобучения. Концепция проста: мы выделяем часть нашего набора данных в качестве проверочного набора (указывается с помощью
validation_fraction) для оценки производительности модели во время обучения. По мере итеративного построения модели с дополнительными этапами (деревьями) её производительность на валидационном наборе отслеживается в зависимости от количества шагов.
Ранняя остановка становится эффективной, когда производительность модели на
валидационном наборе данных выходит на плато или ухудшается (в пределах отклонений, заданных tol)
в течение определенного количества последовательных этапов (указанных n_iter_no_change).
Это сигнализирует о том, что модель достигла точки, где дальнейшие итерации могут
привести к переобучению, и пора прекращать обучение.
Количество оценщиков (деревьев) в финальной модели, когда применяется ранняя остановка, можно получить с помощью n_estimators_ атрибута. В целом, ранняя остановка — это ценный инструмент для достижения баланса между производительностью модели и эффективностью в градиентном бустинге.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Подготовка данных#
Сначала мы загружаем и подготавливаем набор данных California Housing Prices для обучения и оценки. Он выбирает подмножество набора данных, разделяет его на обучающую и валидационную выборки.
import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X, y = data.data[:600], data.target[:600]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
Обучение и сравнение моделей#
Два GradientBoostingRegressor модели обучаются: одна с ранней остановкой, другая без. Цель — сравнить их производительность. Также рассчитывается время обучения и n_estimators_
используемые обеими моделями.
params = dict(n_estimators=1000, max_depth=5, learning_rate=0.1, random_state=42)
gbm_full = GradientBoostingRegressor(**params)
gbm_early_stopping = GradientBoostingRegressor(
**params,
validation_fraction=0.1,
n_iter_no_change=10,
)
start_time = time.time()
gbm_full.fit(X_train, y_train)
training_time_full = time.time() - start_time
n_estimators_full = gbm_full.n_estimators_
start_time = time.time()
gbm_early_stopping.fit(X_train, y_train)
training_time_early_stopping = time.time() - start_time
estimators_early_stopping = gbm_early_stopping.n_estimators_
Расчет ошибки#
Код вычисляет mean_squared_error для обучающих и валидационных наборов данных для моделей, обученных в предыдущем разделе. Он вычисляет ошибки для каждой итерации бустинга. Цель - оценить производительность и сходимость моделей.
train_errors_without = []
val_errors_without = []
train_errors_with = []
val_errors_with = []
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_full.staged_predict(X_train),
gbm_full.staged_predict(X_val),
)
):
train_errors_without.append(mean_squared_error(y_train, train_pred))
val_errors_without.append(mean_squared_error(y_val, val_pred))
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_early_stopping.staged_predict(X_train),
gbm_early_stopping.staged_predict(X_val),
)
):
train_errors_with.append(mean_squared_error(y_train, train_pred))
val_errors_with.append(mean_squared_error(y_val, val_pred))
Визуализация сравнения#
Он включает три подграфика:
Построение графиков ошибок обучения обеих моделей по итерациям бустинга.
Построение графиков ошибок валидации обеих моделей по итерациям бустинга.
Создание гистограммы для сравнения времени обучения и используемого оценщика моделей с ранней остановкой и без нее.
fig, axes = plt.subplots(ncols=3, figsize=(12, 4))
axes[0].plot(train_errors_without, label="gbm_full")
axes[0].plot(train_errors_with, label="gbm_early_stopping")
axes[0].set_xlabel("Boosting Iterations")
axes[0].set_ylabel("MSE (Training)")
axes[0].set_yscale("log")
axes[0].legend()
axes[0].set_title("Training Error")
axes[1].plot(val_errors_without, label="gbm_full")
axes[1].plot(val_errors_with, label="gbm_early_stopping")
axes[1].set_xlabel("Boosting Iterations")
axes[1].set_ylabel("MSE (Validation)")
axes[1].set_yscale("log")
axes[1].legend()
axes[1].set_title("Validation Error")
training_times = [training_time_full, training_time_early_stopping]
labels = ["gbm_full", "gbm_early_stopping"]
bars = axes[2].bar(labels, training_times)
axes[2].set_ylabel("Training Time (s)")
for bar, n_estimators in zip(bars, [n_estimators_full, estimators_early_stopping]):
height = bar.get_height()
axes[2].text(
bar.get_x() + bar.get_width() / 2,
height + 0.001,
f"Estimators: {n_estimators}",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
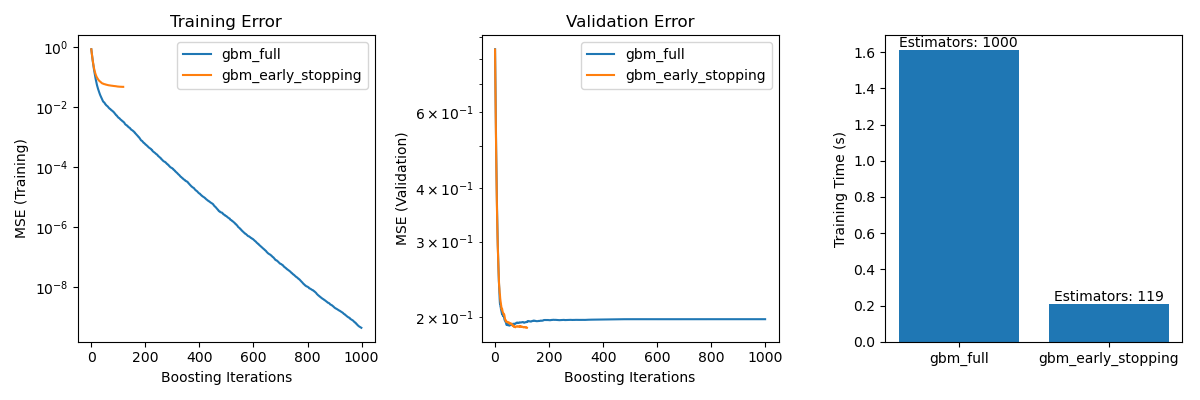
Разница в ошибке обучения между gbm_full и
gbm_early_stopping происходит из-за того, что gbm_early_stopping откладывает validation_fraction обучающих данных в качестве внутреннего набора валидации.
Ранняя остановка определяется на основе этой внутренней оценки валидации.
Сводка#
В нашем примере с GradientBoostingRegressor
модель на наборе данных California Housing Prices, мы продемонстрировали практические преимущества ранней остановки:
Предотвращение переобучения: Мы показали, как ошибка валидации стабилизируется или начинает увеличиваться после определённого момента, что указывает на то, что модель лучше обобщается на невидимые данные. Это достигается путём остановки процесса обучения до возникновения переобучения.
Улучшение эффективности обучения: Мы сравнили время обучения между моделями с ранней остановкой и без нее. Модель с ранней остановкой достигла сопоставимой точности, требуя значительно меньше оценщиков, что привело к более быстрому обучению.
Общее время выполнения скрипта: (0 минут 2.870 секунд)
Связанные примеры
Ранняя остановка стохастического градиентного спуска


Сравнение моделей случайных лесов и градиентного бустинга на гистограммах