Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Сравнение линейных байесовских регрессоров#
Этот пример сравнивает два различных байесовских регрессора:
атрибут данного класса. Автоматическое определение релевантности - ARD
В первой части мы используем Метод наименьших квадратов (OLS) модель в качестве базовой для сравнения коэффициентов моделей с истинными коэффициентами. Затем мы показываем, что оценка таких моделей выполняется путем итеративного максимизации маргинального логарифма правдоподобия наблюдений.
В последнем разделе мы строим графики прогнозов и неопределенностей для регрессий ARD и Байесовского гребня, используя полиномиальное расширение признаков для подгонки нелинейной зависимости между X и y.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Устойчивость моделей к восстановлению истинных весов#
Сгенерировать синтетический набор данных#
Мы генерируем набор данных, где X и y линейно связаны: 10 из
признаков X будет использоваться для генерации y. Остальные признаки не полезны для предсказания y. Кроме того, мы генерируем набор данных, где n_samples
== n_featuresТакая настройка является сложной для модели OLS и может привести к произвольно большим весам. Наличие априорного распределения на веса и штрафа смягчает проблему. В конце добавляется гауссов шум.
from sklearn.datasets import make_regression
X, y, true_weights = make_regression(
n_samples=100,
n_features=100,
n_informative=10,
noise=8,
coef=True,
random_state=42,
)
Обучить регрессоры#
Теперь мы обучаем обе байесовские модели и OLS, чтобы позже сравнить коэффициенты моделей.
import pandas as pd
from sklearn.linear_model import ARDRegression, BayesianRidge, LinearRegression
olr = LinearRegression().fit(X, y)
brr = BayesianRidge(compute_score=True, max_iter=30).fit(X, y)
ard = ARDRegression(compute_score=True, max_iter=30).fit(X, y)
df = pd.DataFrame(
{
"Weights of true generative process": true_weights,
"ARDRegression": ard.coef_,
"BayesianRidge": brr.coef_,
"LinearRegression": olr.coef_,
}
)
Постройте график истинных и оценённых коэффициентов#
Теперь мы сравниваем коэффициенты каждой модели с весами истинной порождающей модели.
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.colors import SymLogNorm
plt.figure(figsize=(10, 6))
ax = sns.heatmap(
df.T,
norm=SymLogNorm(linthresh=10e-4, vmin=-80, vmax=80),
cbar_kws={"label": "coefficients' values"},
cmap="seismic_r",
)
plt.ylabel("linear model")
plt.xlabel("coefficients")
plt.tight_layout(rect=(0, 0, 1, 0.95))
_ = plt.title("Models' coefficients")
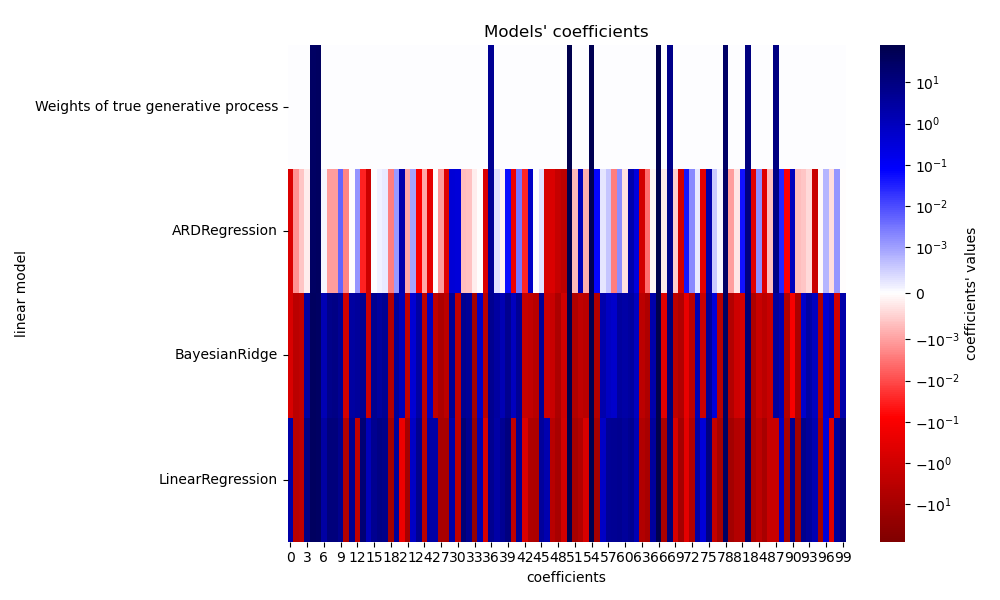
Из-за добавленного шума ни одна из моделей не восстанавливает истинные веса. Действительно, все модели всегда имеют более 10 ненулевых коэффициентов. По сравнению с оценщиком OLS, коэффициенты с использованием байесовской гребневой регрессии слегка смещены к нулю, что стабилизирует их. Регрессия ARD дает более разреженное решение: некоторые неинформативные коэффициенты устанавливаются точно в ноль, в то время как другие смещаются ближе к нулю. Некоторые неинформативные коэффициенты все еще присутствуют и сохраняют большие значения.
Построение маргинального логарифмического правдоподобия#
import numpy as np
ard_scores = -np.array(ard.scores_)
brr_scores = -np.array(brr.scores_)
plt.plot(ard_scores, color="navy", label="ARD")
plt.plot(brr_scores, color="red", label="BayesianRidge")
plt.ylabel("Log-likelihood")
plt.xlabel("Iterations")
plt.xlim(1, 30)
plt.legend()
_ = plt.title("Models log-likelihood")
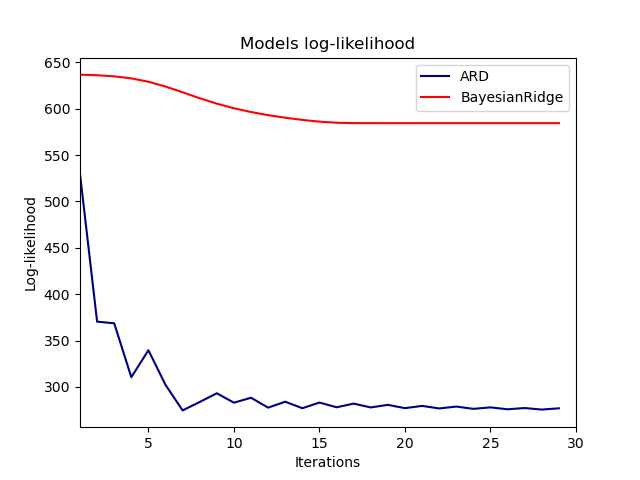
Действительно, обе модели минимизируют логарифмическое правдоподобие до произвольного порога, определенного max_iter параметр.
Байесовские регрессии с полиномиальным расширением признаков#
Сгенерировать синтетический набор данных#
Мы создаем цель, которая является нелинейной функцией входного признака. Добавляется шум, следующий стандартному равномерному распределению.
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
rng = np.random.RandomState(0)
n_samples = 110
# sort the data to make plotting easier later
X = np.sort(-10 * rng.rand(n_samples) + 10)
noise = rng.normal(0, 1, n_samples) * 1.35
y = np.sqrt(X) * np.sin(X) + noise
full_data = pd.DataFrame({"input_feature": X, "target": y})
X = X.reshape((-1, 1))
# extrapolation
X_plot = np.linspace(10, 10.4, 10)
y_plot = np.sqrt(X_plot) * np.sin(X_plot)
X_plot = np.concatenate((X, X_plot.reshape((-1, 1))))
y_plot = np.concatenate((y - noise, y_plot))
Обучить регрессоры#
Здесь мы пробуем полином 10-й степени для потенциального переобучения, хотя байесовские линейные модели регуляризируют размер полиномиальных коэффициентов. Как
fit_intercept=True по умолчанию для
ARDRegression и
BayesianRidge, затем
PolynomialFeatures не должен вводить дополнительный признак смещения. Установив return_std=True, байесовские регрессоры возвращают стандартное отклонение апостериорного распределения для параметров модели.
ard_poly = make_pipeline(
PolynomialFeatures(degree=10, include_bias=False),
StandardScaler(),
ARDRegression(),
).fit(X, y)
brr_poly = make_pipeline(
PolynomialFeatures(degree=10, include_bias=False),
StandardScaler(),
BayesianRidge(),
).fit(X, y)
y_ard, y_ard_std = ard_poly.predict(X_plot, return_std=True)
y_brr, y_brr_std = brr_poly.predict(X_plot, return_std=True)
Построение полиномиальных регрессий со стандартными ошибками оценок#
ax = sns.scatterplot(
data=full_data, x="input_feature", y="target", color="black", alpha=0.75
)
ax.plot(X_plot, y_plot, color="black", label="Ground Truth")
ax.plot(X_plot, y_brr, color="red", label="BayesianRidge with polynomial features")
ax.plot(X_plot, y_ard, color="navy", label="ARD with polynomial features")
ax.fill_between(
X_plot.ravel(),
y_ard - y_ard_std,
y_ard + y_ard_std,
color="navy",
alpha=0.3,
)
ax.fill_between(
X_plot.ravel(),
y_brr - y_brr_std,
y_brr + y_brr_std,
color="red",
alpha=0.3,
)
ax.legend()
_ = ax.set_title("Polynomial fit of a non-linear feature")
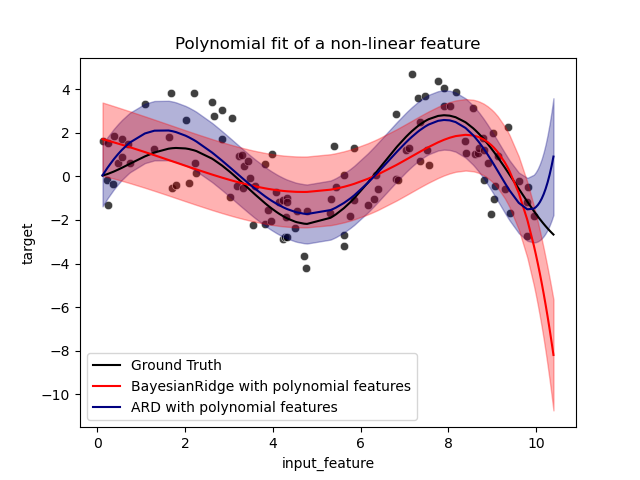
Полоски погрешностей представляют одно стандартное отклонение предсказанного гауссовского распределения точек запроса. Обратите внимание, что ARD-регрессия лучше всего захватывает истинное распределение при использовании параметров по умолчанию в обеих моделях, но дальнейшее уменьшение lambda_init гиперпараметр байесовского гребня может
уменьшить его смещение (см. пример
Аппроксимация кривой с использованием байесовской гребневой регрессии).
Наконец, из-за внутренних ограничений полиномиальной регрессии обе модели терпят неудачу при экстраполяции.
Общее время выполнения скрипта: (0 минут 0.623 секунды)
Связанные примеры