Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Различные агломеративные кластеризации на 2D-вложении цифр#
Иллюстрация различных вариантов связывания для агломеративной кластеризации на двумерном представлении набора данных digits.
Цель этого примера — интуитивно показать, как ведут себя метрики, а не найти хорошие кластеры для цифр. Поэтому пример работает на 2D-вложении.
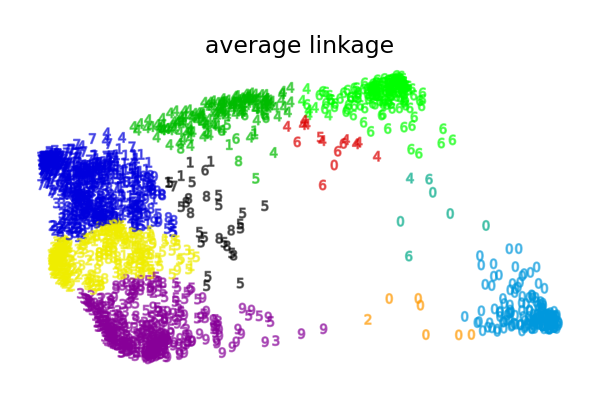
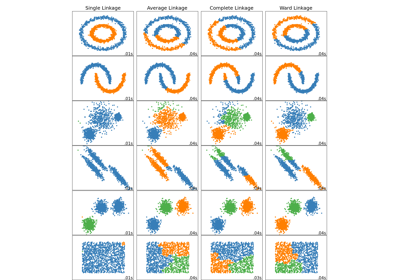
Что показывает нам этот пример — это поведение "богатые становятся богаче" агломеративной кластеризации, которая стремится создавать неравномерные размеры кластеров.
Такое поведение выражено для стратегии среднего связывания, которая заканчивается парой кластеров с небольшим количеством точек данных.
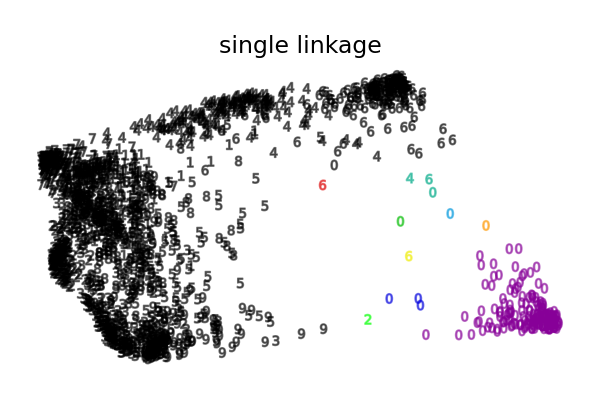
Случай одиночной связи еще более патологичен с очень большим кластером, покрывающим большинство цифр, кластером среднего размера (чистым) с большинством нулевых цифр и всеми остальными кластерами, состоящими из шумовых точек на периферии.
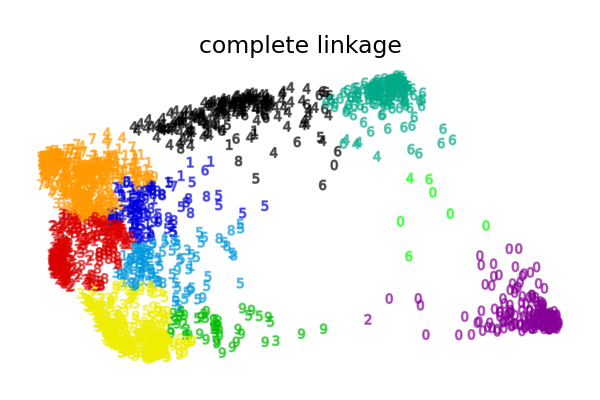
Другие стратегии связывания приводят к более равномерно распределённым кластерам, которые, следовательно, с меньшей вероятностью будут чувствительны к случайной повторной выборке набора данных.

Computing embedding
Done.
ward : 0.06s
average : 0.06s
complete : 0.05s
single : 0.02s
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets, manifold
digits = datasets.load_digits()
X, y = digits.data, digits.target
n_samples, n_features = X.shape
np.random.seed(0)
# ----------------------------------------------------------------------
# Visualize the clustering
def plot_clustering(X_red, labels, title=None):
x_min, x_max = np.min(X_red, axis=0), np.max(X_red, axis=0)
X_red = (X_red - x_min) / (x_max - x_min)
plt.figure(figsize=(6, 4))
for digit in digits.target_names:
plt.scatter(
*X_red[y == digit].T,
marker=f"${digit}$",
s=50,
c=plt.cm.nipy_spectral(labels[y == digit] / 10),
alpha=0.5,
)
plt.xticks([])
plt.yticks([])
if title is not None:
plt.title(title, size=17)
plt.axis("off")
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# ----------------------------------------------------------------------
# 2D embedding of the digits dataset
print("Computing embedding")
X_red = manifold.SpectralEmbedding(n_components=2).fit_transform(X)
print("Done.")
from sklearn.cluster import AgglomerativeClustering
for linkage in ("ward", "average", "complete", "single"):
clustering = AgglomerativeClustering(linkage=linkage, n_clusters=10)
t0 = time()
clustering.fit(X_red)
print("%s :\t%.2fs" % (linkage, time() - t0))
plot_clustering(X_red, clustering.labels_, "%s linkage" % linkage)
plt.show()
Общее время выполнения скрипта: (0 минут 1.491 секунд)
Связанные примеры
Сравнение различных методов иерархической связи на игрушечных наборах данных

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…