Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Распространение меток на цифрах: Демонстрация производительности#
Этот пример демонстрирует мощь полуконтролируемого обучения путем обучения модели Label Spreading для классификации рукописных цифр с наборами очень немногих меток.
Набор данных рукописных цифр содержит 1797 точек. Модель будет обучена на всех точках, но только 30 будут размечены. Результаты в виде матрицы ошибок и ряда метрик для каждого класса будут очень хорошими.
В конце будут показаны 10 наиболее неопределённых предсказаний.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Генерация данных#
Мы используем набор данных digits. Мы используем только подмножество случайно выбранных образцов.
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
rng = np.random.RandomState(2)
indices = np.arange(len(digits.data))
rng.shuffle(indices)
Мы выбрали 340 образцов, из которых только 40 будут связаны с известной меткой. Поэтому мы сохраняем индексы 300 других образцов, для которых мы не должны знать их метки.
X = digits.data[indices[:340]]
y = digits.target[indices[:340]]
images = digits.images[indices[:340]]
n_total_samples = len(y)
n_labeled_points = 40
indices = np.arange(n_total_samples)
unlabeled_set = indices[n_labeled_points:]
Перемешать все вокруг
y_train = np.copy(y)
y_train[unlabeled_set] = -1
Полу-контролируемое обучение#
Мы обучаем LabelSpreading и использовать его для предсказания неизвестных меток.
from sklearn.metrics import classification_report
from sklearn.semi_supervised import LabelSpreading
lp_model = LabelSpreading(gamma=0.25, max_iter=20)
lp_model.fit(X, y_train)
predicted_labels = lp_model.transduction_[unlabeled_set]
true_labels = y[unlabeled_set]
print(
"Label Spreading model: %d labeled & %d unlabeled points (%d total)"
% (n_labeled_points, n_total_samples - n_labeled_points, n_total_samples)
)
Label Spreading model: 40 labeled & 300 unlabeled points (340 total)
Отчет о классификации
print(classification_report(true_labels, predicted_labels))
precision recall f1-score support
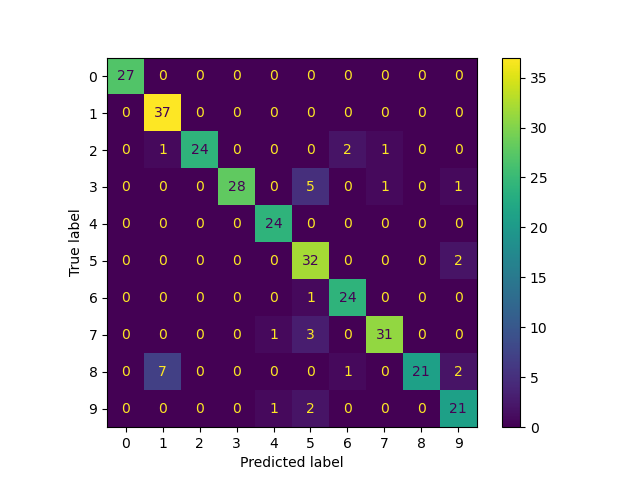
0 1.00 1.00 1.00 27
1 0.82 1.00 0.90 37
2 1.00 0.86 0.92 28
3 1.00 0.80 0.89 35
4 0.92 1.00 0.96 24
5 0.74 0.94 0.83 34
6 0.89 0.96 0.92 25
7 0.94 0.89 0.91 35
8 1.00 0.68 0.81 31
9 0.81 0.88 0.84 24
accuracy 0.90 300
macro avg 0.91 0.90 0.90 300
weighted avg 0.91 0.90 0.90 300
Матрица ошибок
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(
true_labels, predicted_labels, labels=lp_model.classes_
)
Построить график наиболее неопределенных предсказаний#
Здесь мы выберем и покажем 10 наиболее неопределенных предсказаний.
from scipy import stats
pred_entropies = stats.distributions.entropy(lp_model.label_distributions_.T)
Отношения правдоподобия классов для измерения производительности классификации
uncertainty_index = np.argsort(pred_entropies)[-10:]
Построить график
import matplotlib.pyplot as plt
f = plt.figure(figsize=(7, 5))
for index, image_index in enumerate(uncertainty_index):
image = images[image_index]
sub = f.add_subplot(2, 5, index + 1)
sub.imshow(image, cmap=plt.cm.gray_r)
plt.xticks([])
plt.yticks([])
sub.set_title(
"predict: %i\ntrue: %i" % (lp_model.transduction_[image_index], y[image_index])
)
f.suptitle("Learning with small amount of labeled data")
plt.show()

Общее время выполнения скрипта: (0 минут 0.258 секунд)
Связанные примеры

Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris
Различные агломеративные кластеризации на 2D-вложении цифр