Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Распознавание рукописных цифр#
Этот пример показывает, как scikit-learn можно использовать для распознавания изображений рукописных цифр от 0 до 9.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
# Standard scientific Python imports
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, metrics, svm
from sklearn.model_selection import train_test_split
Набор данных Digits#
Набор данных digits состоит из изображений цифр размером 8x8
пикселей. images атрибут набора данных хранит
8x8 массивы значений в градациях серого для каждого изображения. Мы будем использовать эти массивы для
визуализации первых 4 изображений. target атрибут набора данных хранит
цифру, которую представляет каждое изображение, и это включено в заголовок 4
графиков ниже.
Примечание: если бы мы работали с файлами изображений (например, файлами 'png'), мы бы загружали
их с помощью matplotlib.pyplot.imread.
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title("Training: %i" % label)

Классификация#
Чтобы применить классификатор к этим данным, нам нужно сгладить изображения, превратив
каждый 2-D массив значений градаций серого из формы (8, 8) в форму
(64,). Впоследствии весь набор данных будет иметь форму
(n_samples, n_features), где n_samples — это количество изображений и
n_features это общее количество пикселей в каждом изображении.
Затем мы можем разделить данные на обучающую и тестовую выборки и обучить классификатор метода опорных векторов на обучающих образцах. Обученный классификатор может впоследствии использоваться для предсказания значения цифры для образцов в тестовой выборке.
# flatten the images
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Create a classifier: a support vector classifier
clf = svm.SVC(gamma=0.001)
# Split data into 50% train and 50% test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False
)
# Learn the digits on the train subset
clf.fit(X_train, y_train)
# Predict the value of the digit on the test subset
predicted = clf.predict(X_test)
Ниже мы визуализируем первые 4 тестовых образца и показываем их предсказанное значение цифры в заголовке.
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, predicted):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title(f"Prediction: {prediction}")

classification_report строит текстовый отчет, показывающий
основные метрики классификации.
print(
f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n"
)
Classification report for classifier SVC(gamma=0.001):
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
Мы также можем построить матрица ошибок истинных значений цифр и предсказанных значений цифр.
disp = metrics.ConfusionMatrixDisplay.from_predictions(y_test, predicted)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
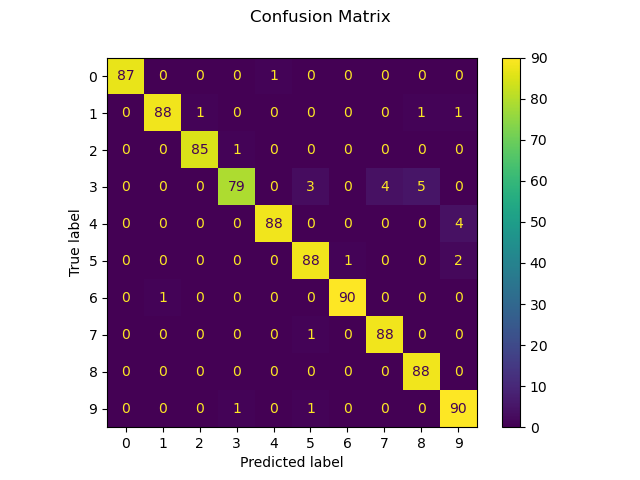
Confusion matrix:
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]
Если результаты оценки классификатора сохранены в виде
матрица ошибок и не в терминах y_true и
y_pred, можно всё равно построить classification_report
следующим образом:
# The ground truth and predicted lists
y_true = []
y_pred = []
cm = disp.confusion_matrix
# For each cell in the confusion matrix, add the corresponding ground truths
# and predictions to the lists
for gt in range(len(cm)):
for pred in range(len(cm)):
y_true += [gt] * cm[gt][pred]
y_pred += [pred] * cm[gt][pred]
print(
"Classification report rebuilt from confusion matrix:\n"
f"{metrics.classification_report(y_true, y_pred)}\n"
)
Classification report rebuilt from confusion matrix:
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
Общее время выполнения скрипта: (0 минут 0.366 секунд)
Связанные примеры
Распространение меток на цифрах: Демонстрация производительности


Удаление шума с изображения с использованием ядерного PCA