Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Демонстрация алгоритма кластеризации DBSCAN#
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) находит основные образцы в областях высокой плотности и расширяет кластеры из них. Этот алгоритм хорошо подходит для данных, содержащих кластеры схожей плотности.
См. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных пример для демонстрации различных алгоритмов кластеризации на 2D наборах данных.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
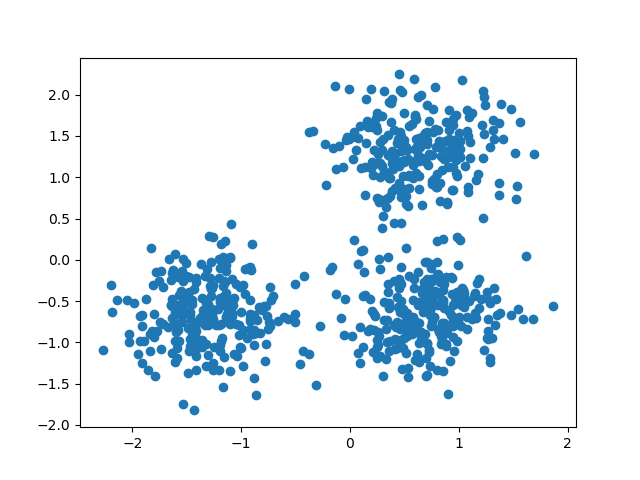
Генерация данных#
Мы используем make_blobs для создания 3 синтетических кластеров.
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=0.4, random_state=0
)
X = StandardScaler().fit_transform(X)
Мы можем визуализировать полученные данные:
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1])
plt.show()
Вычислить DBSCAN#
Можно получить метки, назначенные DBSCAN используя labels_ атрибут. Зашумленным образцам присваивается метка \(-1\).
import numpy as np
from sklearn import metrics
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
Estimated number of clusters: 3
Estimated number of noise points: 18
Алгоритмы кластеризации по своей сути являются методами обучения без учителя.
Однако, поскольку make_blobs предоставляет доступ к истинным меткам синтетических кластеров, что позволяет использовать метрики оценки, которые используют эту «контролируемую» эталонную информацию для количественной оценки качества полученных кластеров. Примерами таких метрик являются однородность, полнота, V-мера, индекс Рэнда, скорректированный индекс Рэнда и скорректированная взаимная информация (AMI).
Если истинные метки неизвестны, оценка может быть выполнена только с использованием самих результатов модели. В этом случае коэффициент силуэта оказывается полезным.
Для получения дополнительной информации см. Коррекция на случайность в оценке производительности кластеризации пример или Оценка производительности кластеризации модуль.
print(f"Homogeneity: {metrics.homogeneity_score(labels_true, labels):.3f}")
print(f"Completeness: {metrics.completeness_score(labels_true, labels):.3f}")
print(f"V-measure: {metrics.v_measure_score(labels_true, labels):.3f}")
print(f"Adjusted Rand Index: {metrics.adjusted_rand_score(labels_true, labels):.3f}")
print(
"Adjusted Mutual Information:"
f" {metrics.adjusted_mutual_info_score(labels_true, labels):.3f}"
)
print(f"Silhouette Coefficient: {metrics.silhouette_score(X, labels):.3f}")
Homogeneity: 0.953
Completeness: 0.883
V-measure: 0.917
Adjusted Rand Index: 0.952
Adjusted Mutual Information: 0.916
Silhouette Coefficient: 0.626
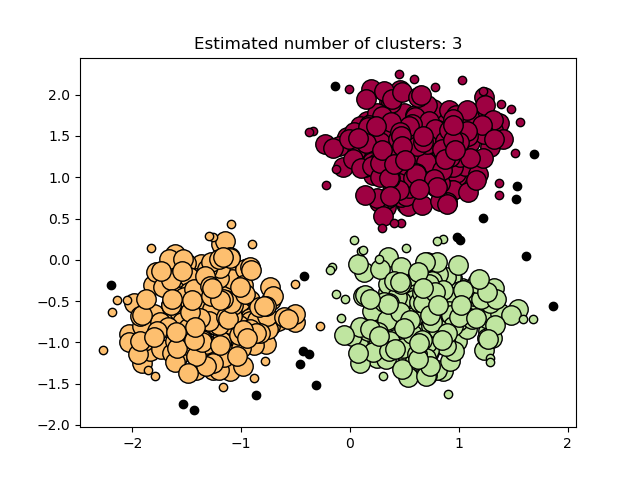
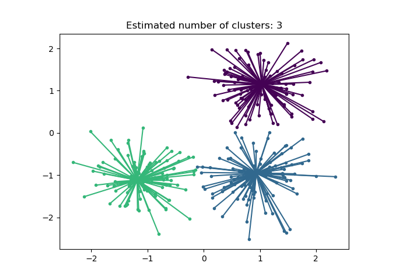
Построить результаты#
Основные образцы (большие точки) и неосновные образцы (маленькие точки) окрашены в соответствии с назначенным кластером. Образцы, помеченные как шум, представлены черным цветом.
unique_labels = set(labels)
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = labels == k
xy = X[class_member_mask & core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=14,
)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=6,
)
plt.title(f"Estimated number of clusters: {n_clusters_}")
plt.show()
Общее время выполнения скрипта: (0 минут 0.142 секунды)
Связанные примеры
Демонстрация алгоритма кластеризации с распространением аффинности
Коррекция на случайность в оценке производительности кластеризации