Перейти в конец
чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Пост-фактумная настройка точки отсечения функции принятия решений#
После обучения бинарного классификатора predict метод выводит предсказания меток классов, соответствующие пороговой обработке либо decision_function или
predict_proba вывод. Порог по умолчанию определяется как оценка апостериорной вероятности 0.5 или оценка решения 0.0. Однако эта стратегия по умолчанию может быть не оптимальной для конкретной задачи.
Этот пример показывает, как использовать
TunedThresholdClassifierCV для настройки порога
принятия решений в зависимости от интересующей метрики.
# Authors: The scikit-learn developers# SPDX-License-Identifier: BSD-3-Clause
Чтобы проиллюстрировать настройку порога принятия решений, мы будем использовать набор данных по диабету. Этот набор данных доступен на OpenML: https://www.openml.org/d/37. Мы используем
fetch_openml функция для получения этого набора данных.
Мы смотрим на целевую переменную, чтобы понять тип задачи, с которой мы имеем дело.
target.value_counts()
class
tested_negative 500
tested_positive 268
Name: count, dtype: int64
Мы видим, что имеем дело с задачей бинарной классификации. Поскольку
метки не закодированы как 0 и 1, мы явно указываем, что рассматриваем класс
с меткой “tested_negative” как отрицательный класс (который также является наиболее частым),
а класс с меткой “tested_positive” как положительный класс:
neg_label,pos_label=target.value_counts().index
Мы также можем наблюдать, что эта бинарная задача слегка несбалансирована, где у нас примерно в два раза больше образцов из отрицательного класса, чем из положительного. При оценке мы должны учитывать этот аспект для интерпретации результатов.
В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Мы оцениваем нашу модель с помощью перекрестной проверки. Мы используем точность и сбалансированную точность для отчета о производительности нашей модели. Сбалансированная точность — это метрика, менее чувствительная к дисбалансу классов, что позволит нам оценить показатель точности в перспективе.
Кросс-валидация позволяет изучить дисперсию порога решения по разным разбиениям данных. Однако набор данных довольно мал, и использование более 5 фолдов для оценки дисперсии было бы вредным. Поэтому мы используем RepeatedStratifiedKFold где мы применяем несколько повторений 5-кратной перекрестной проверки.
Наша прогнозная модель успешно улавливает взаимосвязь между данными и
целевой переменной. Оценки на обучении и тестировании близки друг к другу, что означает, что наша
прогнозная модель не переобучается. Мы также можем наблюдать, что сбалансированная точность
ниже обычной точности из-за ранее упомянутого дисбаланса классов.
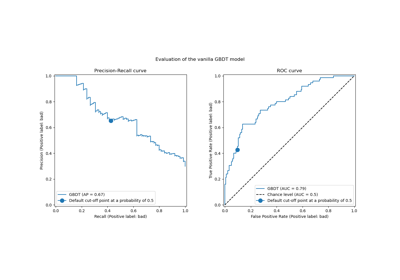
Для этого классификатора мы оставляем порог принятия решения, используемый для преобразования вероятности положительного класса в предсказание класса, равным значению по умолчанию: 0.5. Однако этот порог может быть не оптимальным. Если наша цель — максимизировать сбалансированную точность, мы должны выбрать другой порог, который максимизирует эту метрику.
The TunedThresholdClassifierCV мета-оценщик позволяет настроить порог принятия решений классификатора для заданной метрики интереса.
Мы создаем TunedThresholdClassifierCV и
настроить его для максимизации сбалансированной точности. Мы оцениваем модель, используя ту же
стратегию перекрестной проверки, что и ранее.
По сравнению с базовой моделью мы наблюдаем увеличение сбалансированной точности.
Конечно, это происходит за счет более низкой общей точности. Это означает, что
наша модель теперь более чувствительна к положительному классу, но делает больше ошибок на
отрицательном классе.
Однако важно отметить, что эта настроенная прогностическая модель внутренне является той же моделью, что и базовая модель: они имеют одинаковые подобранные коэффициенты.
importmatplotlib.pyplotaspltvanilla_model_coef=pd.DataFrame([est[-1].coef_.ravel()forestincv_results_vanilla_model["estimator"]],columns=diabetes.feature_names,)tuned_model_coef=pd.DataFrame([est.estimator_[-1].coef_.ravel()forestincv_results_tuned_model["estimator"]],columns=diabetes.feature_names,)fig,ax=plt.subplots(ncols=2,figsize=(12,4),sharex=True,sharey=True)vanilla_model_coef.boxplot(ax=ax[0])ax[0].set_ylabel("Coefficient value")ax[0].set_title("Vanilla model")tuned_model_coef.boxplot(ax=ax[1])ax[1].set_title("Tuned model")_=fig.suptitle("Coefficients of the predictive models")
Только порог принятия решения каждой модели изменялся во время перекрёстной проверки.
decision_threshold=pd.Series([est.best_threshold_forestincv_results_tuned_model["estimator"]],)ax=decision_threshold.plot.kde()ax.axvline(decision_threshold.mean(),color="k",linestyle="--",label=f"Mean decision threshold: {decision_threshold.mean():.2f}",)ax.set_xlabel("Decision threshold")ax.legend(loc="upper right")_=ax.set_title("Distribution of the decision threshold \nacross different cross-validation folds")
В среднем, порог принятия решения около 0.32 максимизирует сбалансированную точность, что отличается от стандартного порога принятия решения 0.5. Таким образом, настройка порога принятия решения особенно важна, когда выход прогнозной модели используется для принятия решений. Кроме того, метрика, используемая для настройки порога принятия решения, должна быть выбрана тщательно. Здесь мы использовали сбалансированную точность, но она может быть не самой подходящей метрикой для данной задачи. Выбор «правильной» метрики обычно зависит от проблемы и может требовать некоторых знаний предметной области. См. пример под названием,
Последующая настройка порога принятия решений для обучения с учетом стоимости,
для получения дополнительной информации.
Общее время выполнения скрипта: (0 минут 35.350 секунд)