Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Объедините предикторы с помощью стекинга#
Стекинг относится к методу объединения оценщиков. В этой стратегии некоторые оценщики индивидуально обучаются на некоторых тренировочных данных, в то время как финальный оценщик обучается с использованием сложенных предсказаний этих базовых оценщиков.
В этом примере мы иллюстрируем случай использования, когда различные регрессоры объединяются вместе, и финальный линейный штрафной регрессор используется для вывода прогноза. Мы сравниваем производительность каждого отдельного регрессора со стратегией стекинга. Стекинг немного улучшает общую производительность.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузите набор данных#
Мы будем использовать Данные по жилью в Эймсе набор данных, который был впервые составлен Дином Де Коком и стал более известен после использования в соревновании Kaggle. Это набор из 1460 жилых домов в Эймсе, Айова, каждый из которых описан 80 признаками. Мы будем использовать его для прогнозирования конечной логарифмической цены домов. В этом примере мы будем использовать только 20 наиболее интересных признаков, выбранных с помощью GradientBoostingRegressor(), и ограничим количество записей (здесь мы не будем вдаваться в подробности о том, как выбирать наиболее интересные признаки).
Набор данных о жилье в Эймсе не поставляется с scikit-learn, поэтому мы загрузим его из OpenML.
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
def load_ames_housing():
df = fetch_openml(name="house_prices", as_frame=True)
X = df.data
y = df.target
features = [
"YrSold",
"HeatingQC",
"Street",
"YearRemodAdd",
"Heating",
"MasVnrType",
"BsmtUnfSF",
"Foundation",
"MasVnrArea",
"MSSubClass",
"ExterQual",
"Condition2",
"GarageCars",
"GarageType",
"OverallQual",
"TotalBsmtSF",
"BsmtFinSF1",
"HouseStyle",
"MiscFeature",
"MoSold",
]
X = X.loc[:, features]
X, y = shuffle(X, y, random_state=0)
X = X.iloc[:600]
y = y.iloc[:600]
return X, np.log(y)
X, y = load_ames_housing()
Создать конвейер для предобработки данных#
Прежде чем мы сможем использовать набор данных Ames, нам все еще нужно выполнить некоторую предварительную обработку. Сначала мы выберем категориальные и числовые столбцы набора данных для построения первого шага конвейера.
from sklearn.compose import make_column_selector
cat_selector = make_column_selector(dtype_include=[object, "string"])
num_selector = make_column_selector(dtype_include=np.number)
cat_selector(X)
['HeatingQC', 'Street', 'Heating', 'MasVnrType', 'Foundation', 'ExterQual', 'Condition2', 'GarageType', 'HouseStyle', 'MiscFeature']
num_selector(X)
['YrSold', 'YearRemodAdd', 'BsmtUnfSF', 'MasVnrArea', 'MSSubClass', 'GarageCars', 'OverallQual', 'TotalBsmtSF', 'BsmtFinSF1', 'MoSold']
Затем нам нужно будет разработать конвейеры предобработки, которые зависят от конечного регрессора. Если конечный регрессор является линейной моделью, необходимо применить one-hot кодирование категорий. Если конечный регрессор является моделью на основе деревьев, достаточно будет порядкового кодировщика. Кроме того, числовые значения необходимо стандартизировать для линейной модели, в то время как необработанные числовые данные могут быть обработаны как есть моделью на основе деревьев. Однако обе модели нуждаются в импутере для обработки пропущенных значений.
Сначала мы разработаем конвейер, необходимый для древовидных моделей.
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
cat_tree_processor = OrdinalEncoder(
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-2,
)
num_tree_processor = SimpleImputer(strategy="mean", add_indicator=True)
tree_preprocessor = make_column_transformer(
(num_tree_processor, num_selector), (cat_tree_processor, cat_selector)
)
tree_preprocessor
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
)]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Затем мы определим препроцессор, используемый, когда конечный регрессор является линейной моделью.
from sklearn.preprocessing import OneHotEncoder, StandardScaler
cat_linear_processor = OneHotEncoder(handle_unknown="ignore")
num_linear_processor = make_pipeline(
StandardScaler(), SimpleImputer(strategy="mean", add_indicator=True)
)
linear_preprocessor = make_column_transformer(
(num_linear_processor, num_selector), (cat_linear_processor, cat_selector)
)
linear_preprocessor
ColumnTransformer(transformers=[('pipeline',
Pipeline(steps=[('standardscaler',
StandardScaler()),
('simpleimputer',
SimpleImputer(add_indicator=True))]),
),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
)]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Стек предикторов на одном наборе данных#
Иногда утомительно найти модель, которая лучше всего будет работать на данном наборе данных. Stacking предоставляет альтернативу, объединяя выходы нескольких обучаемых моделей, без необходимости выбирать конкретную модель. Производительность stacking обычно близка к лучшей модели, а иногда может превзойти прогнозную производительность каждой отдельной модели.
Здесь мы объединяем 3 обучающихся (линейный и нелинейные) и используем гребневый регрессор для объединения их выходов вместе.
Примечание
Хотя мы создадим новые конвейеры с процессорами, которые мы написали в предыдущем разделе для 3 обучаемых моделей, финальный оценщик
RidgeCV() не требует предварительной обработки данных, так как будет получать уже предобработанный выход от 3 обучаемых моделей.
from sklearn.linear_model import LassoCV
lasso_pipeline = make_pipeline(linear_preprocessor, LassoCV())
lasso_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('pipeline',
Pipeline(steps=[('standardscaler',
StandardScaler()),
('simpleimputer',
SimpleImputer(add_indicator=True))]),
),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
)])),
('lassocv', LassoCV())]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
from sklearn.ensemble import RandomForestRegressor
rf_pipeline = make_pipeline(tree_preprocessor, RandomForestRegressor(random_state=42))
rf_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
)])),
('randomforestregressor',
RandomForestRegressor(random_state=42))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Параметры
from sklearn.ensemble import HistGradientBoostingRegressor
gbdt_pipeline = make_pipeline(
tree_preprocessor, HistGradientBoostingRegressor(random_state=0)
)
gbdt_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=0))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Параметры
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import RidgeCV
estimators = [
("Random Forest", rf_pipeline),
("Lasso", lasso_pipeline),
("Gradient Boosting", gbdt_pipeline),
]
stacking_regressor = StackingRegressor(estimators=estimators, final_estimator=RidgeCV())
stacking_regressor
StackingRegressor(estimators=[('Random Forest',
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_v...
),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=0))]))],
final_estimator=RidgeCV()) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Параметры
Измерение и построение результатов#
Теперь мы можем использовать набор данных Ames Housing для прогнозирования. Мы проверяем производительность каждого отдельного предиктора, а также стека регрессоров.
import time
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
from sklearn.model_selection import cross_val_predict, cross_validate
fig, axs = plt.subplots(2, 2, figsize=(9, 7))
axs = np.ravel(axs)
for ax, (name, est) in zip(
axs, estimators + [("Stacking Regressor", stacking_regressor)]
):
scorers = {"R2": "r2", "MAE": "neg_mean_absolute_error"}
start_time = time.time()
scores = cross_validate(
est, X, y, scoring=list(scorers.values()), n_jobs=-1, verbose=0
)
elapsed_time = time.time() - start_time
y_pred = cross_val_predict(est, X, y, n_jobs=-1, verbose=0)
scores = {
key: (
f"{np.abs(np.mean(scores[f'test_{value}'])):.2f} +- "
f"{np.std(scores[f'test_{value}']):.2f}"
)
for key, value in scorers.items()
}
display = PredictionErrorDisplay.from_predictions(
y_true=y,
y_pred=y_pred,
kind="actual_vs_predicted",
ax=ax,
scatter_kwargs={"alpha": 0.2, "color": "tab:blue"},
line_kwargs={"color": "tab:red"},
)
ax.set_title(f"{name}\nEvaluation in {elapsed_time:.2f} seconds")
for name, score in scores.items():
ax.plot([], [], " ", label=f"{name}: {score}")
ax.legend(loc="upper left")
plt.suptitle("Single predictors versus stacked predictors")
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
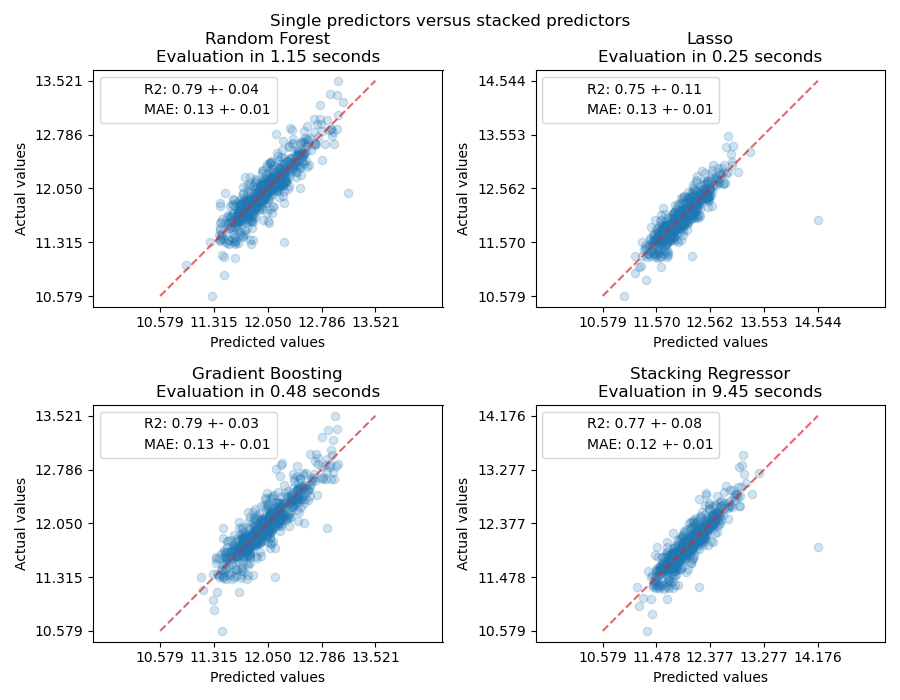
Стекированный регрессор объединит сильные стороны различных регрессоров. Однако мы также видим, что обучение стекированного регрессора требует значительно больше вычислительных ресурсов.
Общее время выполнения скрипта: (0 минут 22.386 секунд)
Связанные примеры
Построить индивидуальные и голосующие регрессионные предсказания

Поддержка категориальных признаков в градиентном бустинге