Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Важность перестановок против важности признаков случайного леса (MDI)#
В этом примере мы сравним важность признаков на основе нечистоты для
RandomForestClassifier с перестановочной важностью на наборе данных Titanic с использованием
permutation_importance. Мы покажем, что важность признаков на основе нечистоты может завышать важность числовых признаков.
Кроме того, важность признаков на основе неопределенности в случайных лесах страдает от того, что вычисляется на статистиках, полученных из обучающего набора данных: важности могут быть высокими даже для признаков, не предсказывающих целевую переменную, пока модель имеет возможность использовать их для переобучения.
Этот пример показывает, как использовать Перестановочные важности в качестве альтернативы, которая может смягчить эти ограничения.
Ссылки
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузка данных и проектирование признаков#
Давайте используем pandas для загрузки копии набора данных Titanic. Ниже показано, как применять отдельную предобработку к числовым и категориальным признакам.
Мы дополнительно включаем две случайные переменные, которые никак не коррелируют
с целевой переменной (survived):
random_numявляется числовой переменной с высокой мощностью (столько же уникальных значений, сколько записей).random_catявляется категориальной переменной с низкой кардинальностью (3 возможных значения).
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
rng = np.random.RandomState(seed=42)
X["random_cat"] = rng.randint(3, size=X.shape[0])
X["random_num"] = rng.randn(X.shape[0])
categorical_columns = ["pclass", "sex", "embarked", "random_cat"]
numerical_columns = ["age", "sibsp", "parch", "fare", "random_num"]
X = X[categorical_columns + numerical_columns]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
Мы определяем прогнозную модель на основе случайного леса. Поэтому мы выполним следующие шаги предобработки:
использовать
OrdinalEncoderдля кодирования категориальных признаков;использовать
SimpleImputerдля заполнения пропущенных значений числовых признаков с использованием стратегии среднего.
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OrdinalEncoder
categorical_encoder = OrdinalEncoder(
handle_unknown="use_encoded_value", unknown_value=-1, encoded_missing_value=-1
)
numerical_pipe = SimpleImputer(strategy="mean")
preprocessing = ColumnTransformer(
[
("cat", categorical_encoder, categorical_columns),
("num", numerical_pipe, numerical_columns),
],
verbose_feature_names_out=False,
)
rf = Pipeline(
[
("preprocess", preprocessing),
("classifier", RandomForestClassifier(random_state=42)),
]
)
rf.fit(X_train, y_train)
Точность модели#
Перед изучением важности признаков важно убедиться, что прогностическая производительность модели достаточно высока. Действительно, изучение важных признаков непрогностической модели представляет мало интереса.
print(f"RF train accuracy: {rf.score(X_train, y_train):.3f}")
print(f"RF test accuracy: {rf.score(X_test, y_test):.3f}")
RF train accuracy: 1.000
RF test accuracy: 0.814
Здесь можно заметить, что точность обучения очень высока (модель леса имеет достаточную емкость, чтобы полностью запомнить обучающий набор), но она все еще может достаточно хорошо обобщаться на тестовый набор благодаря встроенной бэггингу случайных лесов.
Возможно, можно пожертвовать некоторой точностью на обучающем наборе для немного лучшей точности на тестовом наборе, ограничив ёмкость деревьев (например, установив min_samples_leaf=5 или
min_samples_leaf=10) для ограничения переобучения, не внося при этом слишком сильного недообучения.
Однако давайте пока оставим нашу модель случайного леса с высокой емкостью, чтобы проиллюстрировать некоторые подводные камни важности признаков для переменных со многими уникальными значениями.
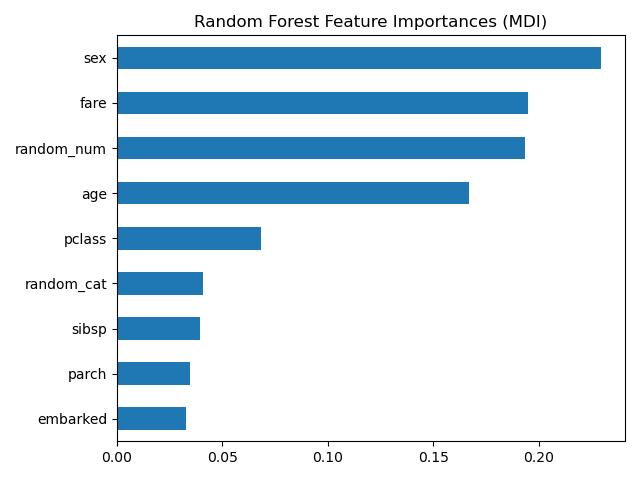
Важность признаков дерева на основе среднего уменьшения неоднородности (MDI)#
Важность признаков на основе примесей ранжирует числовые признаки как наиболее важные. В результате, непредсказательные random_num
Переменная признана одной из наиболее важных признаков!
Эта проблема возникает из-за двух ограничений важности признаков на основе нечистоты:
важности на основе нечистоты смещены в сторону признаков с высокой кардинальностью;
важности на основе примесей вычисляются на статистиках обучающего набора и поэтому не отражают способность признака быть полезным для прогнозирования, которое обобщается на тестовый набор (когда модель имеет достаточную емкость).
Смещение в сторону признаков с высокой кардинальностью объясняет, почему random_num имеет
очень большое значение по сравнению с random_cat в то время как мы бы
ожидали, что оба случайных признака имеют нулевую важность.
Тот факт, что мы используем статистику обучающей выборки, объясняет, почему оба
random_num и random_cat признаки имеют ненулевую важность.
import pandas as pd
feature_names = rf[:-1].get_feature_names_out()
mdi_importances = pd.Series(
rf[-1].feature_importances_, index=feature_names
).sort_values(ascending=True)
ax = mdi_importances.plot.barh()
ax.set_title("Random Forest Feature Importances (MDI)")
ax.figure.tight_layout()
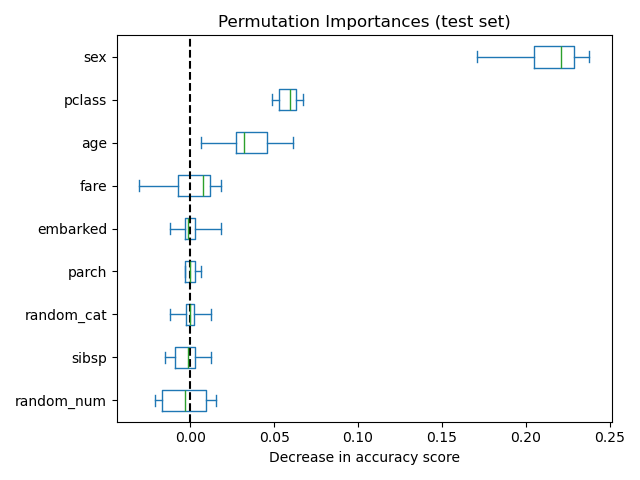
В качестве альтернативы, перестановочные важности rf вычисляются на
отложенном тестовом наборе. Это показывает, что категориальный признак с низкой кардинальностью,
sex и pclass являются наиболее важными признаками. Действительно, перестановка
значений этих признаков приведет к наибольшему снижению точности модели
на тестовом наборе.
Также обратите внимание, что обе случайные признаки имеют очень низкую важность (близко к 0), как и ожидалось.
from sklearn.inspection import permutation_importance
result = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("Permutation Importances (test set)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("Decrease in accuracy score")
ax.figure.tight_layout()
Также возможно вычислить перестановочную важность на обучающем наборе. Это показывает, что random_num и random_cat получить значительно
более высокий рейтинг важности, чем при вычислении на тестовом наборе. Разница
между этими двумя графиками подтверждает, что модель RF имеет достаточную
ёмкость, чтобы использовать эти случайные числовые и категориальные признаки для переобучения.
result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("Permutation Importances (train set)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("Decrease in accuracy score")
ax.figure.tight_layout()

Мы можем продолжить повтор эксперимента, ограничив способность деревьев переобучаться, установив min_samples_leaf на 20 точках данных.
rf.set_params(classifier__min_samples_leaf=20).fit(X_train, y_train)
Наблюдая оценку точности на обучающей и тестовой выборках, мы видим, что две метрики теперь очень похожи. Следовательно, наша модель больше не переобучается. Затем мы можем проверить перестановочную важность с этой новой моделью.
print(f"RF train accuracy: {rf.score(X_train, y_train):.3f}")
print(f"RF test accuracy: {rf.score(X_test, y_test):.3f}")
RF train accuracy: 0.810
RF test accuracy: 0.832
train_result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
test_results = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = train_result.importances_mean.argsort()
train_importances = pd.DataFrame(
train_result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
test_importances = pd.DataFrame(
test_results.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
for name, importances in zip(["train", "test"], [train_importances, test_importances]):
ax = importances.plot.box(vert=False, whis=10)
ax.set_title(f"Permutation Importances ({name} set)")
ax.set_xlabel("Decrease in accuracy score")
ax.axvline(x=0, color="k", linestyle="--")
ax.figure.tight_layout()


Теперь мы можем наблюдать, что на обоих наборах random_num и random_cat
признаки имеют меньшую важность по сравнению с переобученным случайным лесом.
Однако выводы относительно важности других признаков
все еще действительны.
Общее время выполнения скрипта: (0 минут 7.447 секунд)
Связанные примеры
Важность перестановок с мультиколлинеарными или коррелированными признаками

