Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Важность признаков с использованием леса деревьев#
Этот пример показывает использование леса деревьев для оценки важности признаков на искусственной задаче классификации. Синие столбцы представляют важность признаков леса, а их изменчивость между деревьями показана полосами ошибок.
Как и ожидалось, график показывает, что 3 признака являются информативными, а остальные — нет.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
Генерация данных и подгонка модели#
Мы генерируем синтетический набор данных только с 3 информативными признаками. Мы явно не будем перемешивать набор данных, чтобы гарантировать, что информативные признаки будут соответствовать первым трем столбцам X. Кроме того, мы разделим наш набор данных на обучающую и тестовую подвыборки.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
Классификатор случайного леса будет обучен для вычисления важности признаков.
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
Важность признаков на основе среднего уменьшения примесей#
Важность признаков предоставляется обученным атрибутом
feature_importances_ и они вычисляются как среднее значение и стандартное отклонение накопления уменьшения примеси внутри каждого дерева.
Предупреждение
Важности признаков на основе нечистоты могут вводить в заблуждение для высокая кардинальность признаков (много уникальных значений). См. Важность признаков на основе перестановок в качестве альтернативы ниже.
Elapsed time to compute the importances: 0.018 seconds
Построим график важности на основе нечистоты.
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
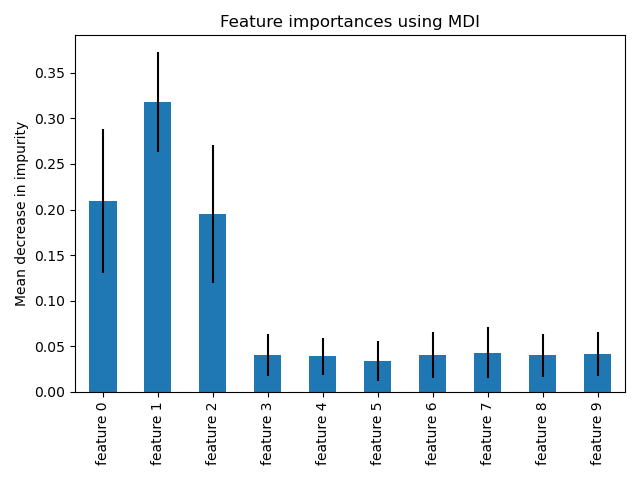
Мы наблюдаем, что, как и ожидалось, первые три признака оказались важными.
Важность признаков на основе перестановки признаков#
Важность признаков на основе перестановок преодолевает ограничения важности признаков на основе нечистоты: они не имеют смещения в сторону признаков с высокой кардинальностью и могут быть вычислены на отложенном тестовом наборе.
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 1.203 seconds
Вычисление полной важности перестановок более затратно. Каждый признак перемешивается n раз, и модель используется для прогнозирования на переставленных данных, чтобы увидеть снижение производительности. См. Важность признаков на основе перестановок для получения дополнительных деталей. Теперь мы можем построить график важности признаков.
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
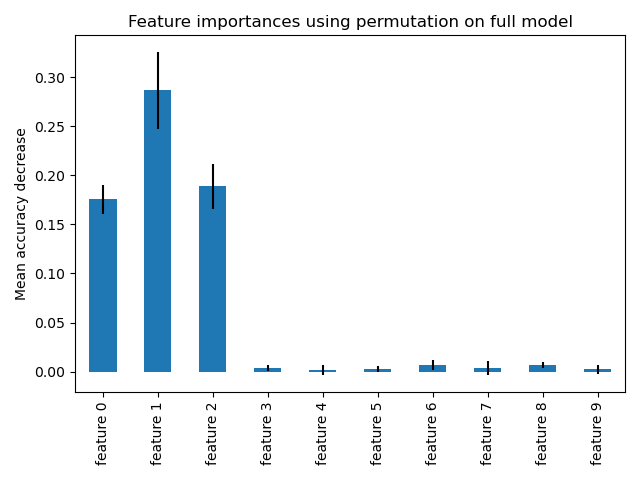
Те же признаки определяются как наиболее важные с использованием обоих методов. Хотя относительная важность варьируется. Как видно на графиках, MDI реже, чем важность перестановки, полностью исключает признак.
Общее время выполнения скрипта: (0 минут 1.722 секунд)
Связанные примеры
Важность перестановок против важности признаков случайного леса (MDI)
Важность перестановок с мультиколлинеарными или коррелированными признаками

